
逻辑时钟概念
Logic Clock Lamport Timestamp
简单说就是为了记录事件发生的因果导向,物理时钟在分布式系统因为机器的时间精度总会有偏差不可能完全精确所以诞生一种记录事件发生顺序的逻辑,这个不是时间而是一种函数用数字表示顺序
- 每一台机器内部都有一个时间戳(Timestamp),初始值为 0。
- 机器执行一个事件(event)之后,该机器的 timestamp + 1。
- 当机器发送信息(message)给另一台机器,它会附带上自己的时间戳,如 。
- 当机器接受到一条 message,它会将本机的 timestamp 和 message 的 timestamp 进行对比,选取大的 timestamp 并 +1
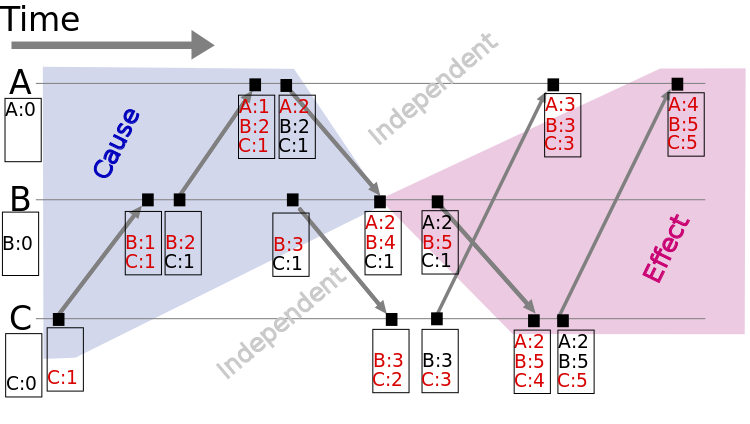
事件序列有两种:偏序事件序列和全序事件序列。偏序指的是只能为系统中的部分事件定义先后顺序。这部分事件其实是有因果关系的。 分布式系统中只有有因果的事件才会关心先后顺序。
但是 Lamport Timestamp 不能很好的满足分布式系统,它不能区分两个事件是否有关联,或者在一个多点读的 key-value 数据库中,它无法让你确定保存哪一份副本(通常保存最新的那份副本)。
Vector Clock(Lamport Timestamp加强版,数组形式的逻辑时钟[0,0,0]每一个0代表一个节点)
(虽然ETCD不会出现脑裂但是找个例子说一下这是什么东西)
脑裂:当进行选主后,仍有客户端和原主库进行通信,使得这部分数据没有同步到新的主上,造成了数据丢失
这样的原因可能是:主是由于某些原因无法处理请求,超时后错误地判断为客观下线的。结果,在被判断下线之后,原主又重新开始处理请求了,而此时,还没有完成主切换,客户端仍然可以和原主库通信,客户端发送的写操作就会在原主上写入数据了。正因为原主并没有真的发生故障,我们在客户端操作日志中就看到了和原主的通信记录。等到从被升级为新主后,主从集群里就有两个主了,到这里,脑裂发生的原因以及什么是脑裂就说清楚了。
说到ETCD就绕不过RAFT算法(后面简要的说明)
先一点点说,随着业务的发展与业务扩展逐渐庞大。单节点访问压力逐步上升,随之而来的直观体现就是响应时间拉长,请求越多越长,直到机器不堪重负挂掉。而解决办法就是从一台变两台,两台变多台,当数量固定干活的人多了,工作分散压力就减小了。(分布式扩展分为垂直或者水平,垂直就是增加CPU提升机器本身性能。水平就是扩展机器找一个多干活的人)
而为了考虑其可用性与可靠性就需要对数据进行副本化复制,因为单节点出问题后,还有一台可用,即使硬盘损坏还有一组一样的数据存在另一个节点上。这样数据就相对得到了保证,但是这样就会出现一个问题。如何保证数据的一致性,怎么保证我在读取数据的时候一直是最新提交的数据。为了这个事出现了后面很多的副本控制协议,经过资料查找有同步异步、强一致弱一致、中心化去中心化
同步(阻塞到所有副本更新结束才对客户端返回一个节点正常数据就正常,一个节点挂掉更新无法完成。响应慢。参考网络延时,性能差的节点处理也慢。)
异步(更新一个就向客户端反馈完成,然台继续偷偷的同步给其他节点。不过在没数据同步完之前更新完数据的节点口吐白沫就完了,刚刚更新数据没了。而且有可能在没更新完数据前读取到的数据不是最新)
强一致(所有服务副本确认成功执行了第一步才能执行第二部就是强一致)意思就是我在同一个时间查询到任何一个副本数据都是一样的)
别称
- 原子一致性
- 线性一致性
任何时刻访问看到都是最新的数据,同一时间下看到的所有操作都是一样的。
弱一致(可以访问部分最新数据或者都访问不到)
最终一致性(最终结果一致)
中心化(副本更新操作有一个头头进行并发,集群并发变成单点并发。缺点老大挂了就报废了,有切换但也会有切换空档时期)可以理解看成mysql主从
去中心化(众生平等,协商达成数据一致。可用性好,多数节点存活就能用。但是,在需要强一致性保证的时候,协议流程会很复杂)
CAP理论 一致性(C,Consistency)、可用性(A, Availability)、分区容错性(P,Partition Tolerance)。3种最多同时达成两种,不过如果一致性不高勉强能实现三种。
为什么说了这么多废话。因为etcd是根据raft算法实现,而raft算法实现有涉及上面的东西。下面就了解一下机制
| 特性 | 解释 |
|---|---|
| 选举安全特性 | 对于一个给定的任期号,最多只会有一个领导人被选举出来 |
| 领导人只附加原则 | 领导人绝对不会删除或者覆盖自己的日志,只会增加 |
| 日志匹配原则 | 如果两个日志在相同的索引位置的日志条目的任期号相同,那么我们就认为这个日志从头到这个索引位置之间全部完全相同 |
| 领导人完全特性 | 如果某个日志条目在某个任期号中已经被提交,那么这个条目必然出现在更大任期号的所有领导人中 |
| 状态机安全特性 | 如果一个领导人已经将给定的索引值位置的日志条目应用到状态机中,那么其他任何的服务器在这个索引位置不会应用一个不同的日志 |
Leader选举
状态:
所有服务器上的持久性状态 (在响应RPC请求之前 已经更新到了稳定的存储设备)
| 参数 | 解释 |
|---|---|
| currentTerm | 服务器已知最新的任期(在服务器首次启动的时候初始化为0,单调递增) |
| votedFor | 当前任期内收到选票的竞选者id 如果没有投给任何竟选者 则为空 |
| log[] | 日志条目;每个条目包含了用于状态机的命令,以及领导者接收到该条目时的任期(第一个索引为1) |
所有服务器上的易失性状态
| 参数 | 解释 |
|---|---|
| commitIndex | 已知已提交的最高的日志条目的索引(初始值为0,单调递增) |
| lastApplied | 已经被应用到状态机的最高的日志条目的索引(初始值为0,单调递增) |
所有服务器需遵守的规则:
所有服务器:
- 如果
commitIndex > lastApplied,那么就 lastApplied 加一,并把log[lastApplied]应用到状态机中 - 如果接收到的 RPC 请求或响应中,任期号
T > currentTerm,那么就令 currentTerm 等于 T,并切换状态为跟随者
- leader
初始状态时所有server都处于追随者状态,在一段时间内如果没有收到来自leader的心跳(150-300ms)。从追随者进入到竞选者的状态(之前会有一段随机休眠),竞选者状态的server发起投票,向其它所有server发出给它投票请求。并重置选举计时器,其它server给它投票。当它收到大多数server票数(含自己一票),它就切换为Leader状态,成为系统中唯一的Leader。同时其他server保持追随者状态。
一次选举过程会造成选票的瓜分。在这种情况下,这一任期会以没有领导人结束;一个新的任期(和一次新的选举)会很快重新开始。Raft 保证了在一个给定的任期内,最多只有一个领导者。(就是同时两个竞选者把票数均了,平手。然后随机休眠,谁先活动谁在发起选票这个随即时间)
成为Leader后,发送空的附加日志 RPC(以心跳超时的指定时间间隔发送)给其他所有追随者;追随者进行追加条目响应。此选举任期将持续到追随者停止接收心跳并成为竟选者为止。
对于一个追随者,最后日志条目的索引值大于等于 nextIndex。那么,发送从 nextIndex 开始的所有日志条目。
-
-
- 如果成功:更新相应追随者的 nextIndex 和 matchIndex
- 如果因为日志不一致而失败,减少 nextIndex 重试
-
Leader(服务器)上的易失性(突发的意外的可以理解为不好使了)状态 (选举后重新初始化)
| 参数 | 解释 |
|---|---|
| nextIndex[] | 对于每一台服务器,发送到该服务器的下一个日志条目的索引(初始值为Leader最后的日志条目的索引+1)(可以理解为最新的类似于xtrabackup在增备时检查last_lsn的那个值) |
| matchIndex[] | 对于每一台服务器,已知的已经复制到该服务器的最高日志条目的索引(初始值为0,单调递增) |
追加条目RPC:
被Leader调用 用于日志条目的复制 同时也被当做心跳使用
参数:
| 参数 | 解释 |
|---|---|
| term | Leader的任期 |
| leaderId | Leader ID 因此追随者可以对客户端进行重定向(译者注:追随者根据Leader id把客户端的请求重定向给Leader,比如有时客户端把请求发给了追随者而不是Leader) |
| prevLogIndex | 紧邻新日志条目之前的那个日志条目的索引 |
| prevLogTerm | 紧邻新日志条目之前的那个日志条目的任期 |
| entries[] | 需要被保存的日志条目(被当做心跳使用则日志条目内容为空;为了提高效率可能一次性发送多个) |
| leaderCommit | Leader的已知已提交的最高的日志条目的索引 |
结果
| 返回值 | 解释 |
|---|---|
| term | 当前任期,对于Leader而言 它会更新自己的任期 |
| success | 结果为真 如果追随者所含有的条目和prevLogIndex以及prevLogTerm匹配上了 |
- follower
响应来自竞选者和leader的请求
如果在超过选举超时时间的情况之前没有收到当前leader(前提条件leader与追随者当前任期相同)的心跳/附加日志,或者是给某个竟选者投了票,就自己变成竟选人
接收者的实现:
- false 如果Leader的任期 小于 接收者的当前任期(译者注:这里的接收者是指追随者或者竞选者)
- false 如果接收者日志中没有包含这样一个条目 即该条目的任期在prevLogIndex上能和prevLogTerm匹配上 (译者注:在接收者日志中 如果能找到一个和prevLogIndex以及prevLogTerm一样的索引和任期的日志条目 则继续执行下面的步骤 否则返回假)
- 如果一个已经存在的条目和新条目(译者注:即刚刚接收到的日志条目)发生了冲突(因为索引相同,任期不同),那么就删除这个已经存在的条目以及它之后的所有条目
- 追加日志中尚未存在的任何新条目
- 如果领导者的已知已经提交的最高的日志条目的索引leaderCommit 大于 接收者的已知已经提交的最高的日志条目的索引commitIndex 则把 接收者的已知已经提交的最高的日志条目的索引commitIndex 重置为 领导者的已知已经提交的最高的日志条目的索引leaderCommit 或者是 上一个新条目的索引 取两者的最小值
- false 如果
term < currentTerm返回 - 如果 votedFor 为空或者为竞选者的id,并且竞选者的日志至少和自己一样新,那么就投票给它
- 竞选者知道的信息不能比自己的少
- 先到先得(投票)
- candidate
在转变成竟选者后就立即开始选举过程
-
-
- 自增当前的任期号(currentTerm)
- 给自己投票
- 重置选举超时计时器
- 发送请求投票的 RPC 给其他所有服务器
-
如果接收到大多数服务器的选票,那么就变成领导人
如果接收到来自新的领导人的附加日志 RPC,转变成跟随者
如果选举过程超时,再次发起一轮选举
请求投票 RPC:
由候选人负责调用用来征集选票
| 参数 | 解释 |
|---|---|
| term | 候选人的任期号 |
| candidateId | 请求选票的候选人的 Id |
| lastLogIndex | 候选人的最后日志条目的索引值 |
| lastLogTerm | 候选人最后日志条目的任期号 |
| 返回值 | 解释 |
|---|---|
| term | 当前任期号,以便于候选人去更新自己的任期号 |
| voteGranted | 候选人赢得了此张选票时为真 |
日志复制(类似于mysql日志主从同步)
接收到来自客户端的请求,附加条目到本地日志中,在下一个心跳发送给追随者,当大多数追随者认可这个条目(因为是去中心化所以是协商形式)就会提交这个数据,然后返回给Leader响应给客户端,把条目应用到状态机中,达成一致
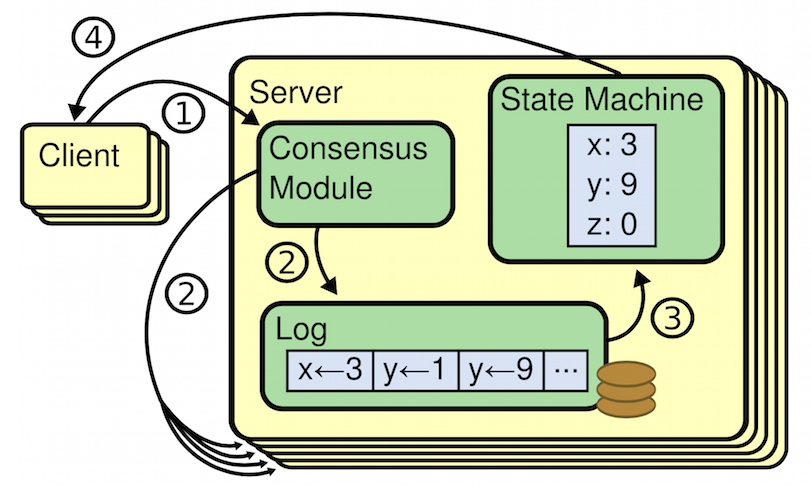
在网络分区的情况下,节点数量少的分区与节点多的分区都会有一个Leader,但是在client发出请求时,因为节点少的无法复制多点数据,所以结果是数据为未提交状态,因此不会更新节点的值
节点多的可以正常更新。在恢复后节点少的Leader看到有比自己新的任期后自动转换为追随者。然后节点少的两个节点回滚为提交的日志条目,匹配执行Leader发过来的日志
http://thesecretlivesofdata.com/raft/#conclusion
安全性
可以简单的理解为同意任期只有一个Leader,而且每个节点只有一票

 浙公网安备 33010602011771号
浙公网安备 33010602011771号