Kubernetes安装配置(包括master和node)
部署Kubernetes云计算平台,至少准备两台服务器,此处为4台,包括一台Docker仓库:
Kubernetes Master节点:192.168.124.20 Kubernetes Node1节点:192.168.124.19 Kubernetes Node2节点:192.168.124.18 Docker私有库节点:192.168.124.17
每台服务器主机上都运行如下命令:
systemctl stop firewalld systemctl disable firewalld
setenforce 0 yum -y install ntp ntpdate pool.ntp.org systemctl start ntpd systemctl enable ntpd
一、etcd服务简介
1. ETCD是什么
ETCD是用于共享配置和服务发现的分布式,一致性的KV存储系统。该项目目前最新稳定版本为2.3.0. 具体信息请参考[项目首页]和[Github]。ETCD是CoreOS公司发起的一个开源项目,授权协议为Apache。
提供配置共享和服务发现的系统比较多,其中最为大家熟知的是[Zookeeper](后文简称ZK),而ETCD可以算得上是后起之秀了。在项目实现,一致性协议易理解性,运维,安全等多个维度上,ETCD相比Zookeeper都占据优势。
2. ETCD vs ZK
本文选取ZK作为典型代表与ETCD进行比较,而不考虑[Consul]项目作为比较对象,原因为Consul的可靠性和稳定性还需要时间来验证(项目发起方自身服务并未使用Consul, 自己都不用)。 一致性协议: ETCD使用[Raft]协议, ZK使用ZAB(类PAXOS协议),前者容易理解,方便工程实现; 运维方面:ETCD方便运维,ZK难以运维; 项目活跃度:ETCD社区与开发活跃,ZK已经快死了; API:ETCD提供HTTP+JSON, gRPC接口,跨平台跨语言,ZK需要使用其客户端; 访问安全方面:ETCD支持HTTPS访问,ZK在这方面缺失;
3. ETCD的使用场景
和ZK类似,ETCD有很多使用场景,包括: 配置管理 服务注册于发现 选主 应用调度 分布式队列 分布式锁 4. ETCD读写性能
按照官网给出的[Benchmark], 在2CPU,1.8G内存,SSD磁盘这样的配置下,单节点的写性能可以达到16K QPS, 而先写后读也能达到12K QPS。这个性能还是相当可观的。 5. ETCD工作原理
ETCD使用Raft协议来维护集群内各个节点状态的一致性。简单说,ETCD集群是一个分布式系统,由多个节点相互通信构成整体对外服务,每个节点都存储了完整的数据,并且通过Raft协议保证每个节点维护的数据是一致的。
4. ETCD读写性能
按照官网给出的[Benchmark], 在2CPU,1.8G内存,SSD磁盘这样的配置下,单节点的写性能可以达到16K QPS, 而先写后读也能达到12K QPS。这个性能还是相当可观的。
5. ETCD工作原理
ETCD使用Raft协议来维护集群内各个节点状态的一致性。简单说,ETCD集群是一个分布式系统,由多个节点相互通信构成整体对外服务,每个节点都存储了完整的数据,并且通过Raft协议保证每个节点维护的数据是一致的。

如图所示,每个ETCD节点都维护了一个状态机,并且,任意时刻至多存在一个有效的主节点。主节点处理所有来自客户端写操作,通过Raft协议保证写操作对状态机的改动会可靠的同步到其他节点。ETCD工作原理核心部分在于Raft协议。
6. ETCD使用案例
据公开资料显示,至少有CoreOS, Google Kubernetes, Cloud Foundry, 以及在Github上超过500个项目在使用ETCD。
7. ETCD接口
ETCD提供HTTP协议,在最新版本中支持Google gRPC方式访问。具体支持接口情况如下: ETCD是一个高可靠的KV存储系统,支持PUT/GET/DELETE接口; 为了支持服务注册与发现,支持WATCH接口(通过http long poll实现); 支持KEY持有TTL属性; CAS(compare and swap)操作; 支持多key的事务操作; 支持目录操作
二、Kubernetes master安装与配置
1、安装etcd和Kubernetes、Flannel网络。
其中etcd可以独立部署在一台机器上,本次和master安装在同一台机器。
yum install kubernetes-master etcd flannel -y
2、修改/etc/etcd/etcd.conf配置文件,将localhost修改为本机IP地址,过滤#后完整配置如下:
ETCD_DATA_DIR="/var/lib/etcd/default.etcd" ETCD_LISTEN_CLIENT_URLS="http://192.168.124.17:2379,,http://127.0.0.1:2379" ETCD_NAME="default" ETCD_ADVERTISE_CLIENT_URLS="http://192.168.124.17:2379"
3、修改/etc/kubernetes/config配置文件,完整代码如下(红色标注即修改的部分):
KUBE_LOGTOSTDERR="--logtostderr=true" KUBE_LOG_LEVEL="--v=0" KUBE_ALLOW_PRIV="--allow-privileged=false" KUBE_MASTER="--master=http://192.168.124.17:8080"
将Kubernetes的apiserver进程的服务地址告诉Kubernetes的controller-manager, scheduler,proxy进程。
4、修改/etc/kubernetes/apiserver配置文件,完整代码如下(红色标注即修改的部分):
主要修改地方为,apiserver监听地址和端口,连接etcd地址和端口:
# kubernetes system config # # The following values are used to configure the kube-apiserver # # The address on the local server to listen to. KUBE_API_ADDRESS="--insecure-bind-address=0.0.0.0" # The port on the local server to listen on. KUBE_API_PORT="--port=8080" # Port minions listen on # KUBELET_PORT="--kubelet-port=10250" # Comma separated list of nodes in the etcd cluster KUBE_ETCD_SERVERS="--etcd-servers=http://192.168.124.17:2379" # Address range to use for services KUBE_SERVICE_ADDRESSES="--service-cluster-ip-range=10.254.0.0/16" # default admission control policies KUBE_ADMISSION_CONTROL="--admission-control=NamespaceLifecycle,NamespaceExists,LimitRanger,SecurityContextDeny,ServiceAccount,ResourceQuota" # Add your own! KUBE_API_ARGS=""
5、启动Kubernetes Master节点上的etcd, apiserver, controller-manager和scheduler进程及状态;
for I in etcd kube-apiserver kube-controller-manager kube-scheduler; do systemctl restart $I ;done
service flanneld restart
iptables -P FORWARD ACCEPT
二、Kubernetes Node安装配置
1、在Kubernetes Node节点上安装flannel、docker和Kubernetes;
yum install kubernetes-node docker flannel *rhsm* -y
2、配置文件/etc/kubernetes/config,完整代码如下(红色标注即修改的部分):
###
# kubernetes system config
#
# The following values are used to configure various aspects of all
# kubernetes services, including
#
# kube-apiserver.service
# kube-controller-manager.service
# kube-scheduler.service
# kubelet.service
# kube-proxy.service
# logging to stderr means we get it in the systemd journal
KUBE_LOGTOSTDERR="--logtostderr=true"
# journal message level, 0 is debug
KUBE_LOG_LEVEL="--v=0"
# Should this cluster be allowed to run privileged docker containers
KUBE_ALLOW_PRIV="--allow-privileged=false"
# How the controller-manager, scheduler, and proxy find the apiserver
KUBE_MASTER="--master=http://192.168.124.17:8080"
3、修改配置文件/etc/kubernetes/kubelet,完整代码如下(红色标注即修改的部分):
### # kubernetes kubelet (minion) config # The address for the info server to serve on (set to 0.0.0.0 or "" for all interfaces) KUBELET_ADDRESS="--address=0.0.0.0" # The port for the info server to serve on # KUBELET_PORT="--port=10250" # You may leave this blank to use the actual hostname KUBELET_HOSTNAME="--hostname-override=192.168.124.18" # location of the api-server KUBELET_API_SERVER="--api-servers=http://192.168.124.17:8080" # pod infrastructure container KUBELET_POD_INFRA_CONTAINER="--pod-infra-container-image=registry.access.redhat.com/rhel7/pod-infrastructure:latest" # Add your own! KUBELET_ARGS=""
4、分别启动Kubernetes Node节点上kube-proxy、kubelet、docker、flanneld进程并查看其状态:
for I in kube-proxy kubelet docker;do systemctl restart $I;done
service flanneld restart iptables -P FORWARD ACCEPT
三、Kubernetes flanneld网络配置
1、Kubernetes整个集群所有服务器(Master、Minions)配置Flanneld,指定etcd地址,/etc/sysconfig/flanneld代码如下:
# Flanneld configuration options # etcd url location. Point this to the server where etcd runs FLANNEL_ETCD_ENDPOINTS="http://192.168.124.17:2379" # etcd config key. This is the configuration key that flannel queries # For address range assignment FLANNEL_ETCD_PREFIX="/atomic.io/network" # Any additional options that you want to pass #FLANNEL_OPTIONS=""
2、在Master服务器,创建flannel网络配置。
etcdctl mk /atomic.io/network/config '{"Network":"172.17.0.0/16"}'
3、Kubernetes整个集群所有服务器(Master、Minions)重启flannel
service flanneld restart
4、可以输入如下代码查看flannel网络信息(互信ping,保证网络互通):
etcdctl member list etcdctl cluster-health etcdctl get /atomic.io/network/config 整个集群所在的大网段 etcdctl ls /atomic.io/network/subnets 列出分配node节点的子网段 etcdctl rm /atomic.io/network/ --recursive

Kubernetes的Node节点搭建和配置flannel网络,etcd中/atomic.io/network/config节点会被Node节点上的flannel用来创建Doker IP地址网段。
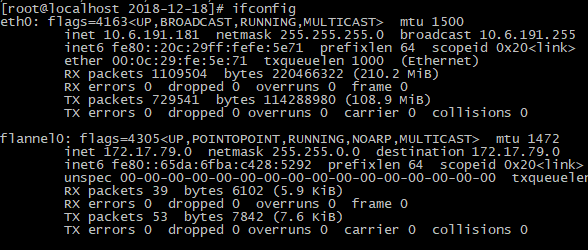
图 master的网络
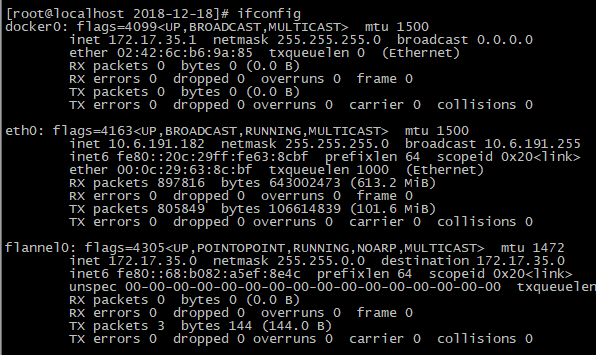
图 node1的网卡信息
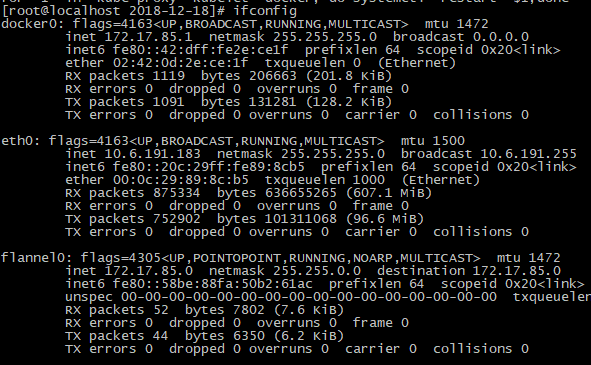
图 node2的网卡信息
四、Kubernetes Dashboard UI实战
Kubernetes实现的最重要的工作是对Docker容器集群统一的管理和调度,通常使用命令行来操作Kubernetes集群及各个节点,命令行操作非常不方便,如果使用UI界面来可视化操作,会更加方便的管理和维护。
如下为配置kubernetes dashboard完整过程,在Node节点提前导入两个列表镜像(从云盘下载即可)(或者pull更改镜像名):
1)pod-infrastructure
2)kubernetes-dashboard-amd64
1、在node节点配置导入镜像
docker load < pod-infrastructure.tgz docker tag $(docker images|grep none|awk '{print $3}') registry.access.redhat.com/rhel7/pod-infrastructure 将导入的pod镜像名称修改 docker load < kubernetes-dashboard-amd64.tgz docker tag $(docker images|grep none|awk '{print $3}') bestwu/kubernetes-dashboard-amd64:v1.6.3 将导入的pod镜像名称修改
2、然后在Master端,创建dashboard-controller.yaml,代码如下:
apiVersion: extensions/v1beta1 kind: Deployment metadata: name: kubernetes-dashboard namespace: kube-system labels: k8s-app: kubernetes-dashboard kubernetes.io/cluster-service: "true" spec: selector: matchLabels: k8s-app: kubernetes-dashboard template: metadata: labels: k8s-app: kubernetes-dashboard annotations: scheduler.alpha.kubernetes.io/critical-pod: '' scheduler.alpha.kubernetes.io/tolerations: '[{"key":"CriticalAddonsOnly", "operator":"Exists"}]' spec: containers: - name: kubernetes-dashboard image: bestwu/kubernetes-dashboard-amd64:v1.6.3 resources: # keep request = limit to keep this container in guaranteed class limits: cpu: 100m memory: 50Mi requests: cpu: 100m memory: 50Mi ports: - containerPort: 9090 args: - --apiserver-host=http://10.6.191.181:8080 livenessProbe: httpGet: path: / port: 9090 initialDelaySeconds: 30 timeoutSeconds: 30
3、创建dashboard-service.yaml,代码如下:
apiVersion: v1 kind: Service metadata: name: kubernetes-dashboard namespace: kube-system labels: k8s-app: kubernetes-dashboard kubernetes.io/cluster-service: "true" spec: selector: k8s-app: kubernetes-dashboard ports: - port: 80 targetPort: 9090
4、创建dashboard dashborad pods模块:
kubectl create -f dashboard-controller.yaml
kubectl create -f dashboard-service.yaml
删除dashboard dashborad pods模块:
kubectl delete -f dashboard-controller.yaml
kubectl delete -f dashboard-service.yaml
5、创建完成后,查看Pods和Service的详细信息:
kubectl get services kubernetes-dashboard -n kube-system #查看所有service kubectl get deployment kubernetes-dashboard -n kube-system #查看所有发布 kubectl get pods --all-namespaces #查看所有pod kubectl get pods -o wide --all-namespaces #查看所有pod的IP及节点 kubectl get pods -n kube-system | grep dashboard kubectl describe service/kubernetes-dashboard --namespace="kube-system" kubectl describe pods/kubernetes-dashboard-349859023-g6q8c --namespace="kube-system" #指定类型查看 kubectl describe pod nginx-772ai #查看pod详细信息 kubectl scale rc nginx --replicas=5 # 动态伸缩 kubectl scale deployment redis-slave --replicas=5 #动态伸缩 kubectl scale --replicas=2 -f redis-slave-deployment.yaml #动态伸缩 kubectl exec -it redis-master-1033017107-q47hh /bin/bash #进入容器 kubectl label nodes node1 zone=north #增加节点lable值 spec.nodeSelector: zone: north #指定pod在哪个节点 kubectl get nodes -lzone #获取zone的节点 kubectl label pod redis-master-1033017107-q47hh role=master #增加lable值 [key]=[value] kubectl label pod redis-master-1033017107-q47hh role- #删除lable值 kubectl label pod redis-master-1033017107-q47hh role=backend --overwrite #修改lable值 kubectl rolling-update redis-master -f redis-master-controller-v2.yaml #配置文件滚动升级 kubectl rolling-update redis-master --image=redis-master:2.0 #命令升级 kubectl rolling-update redis-master --image=redis-master:1.0 --rollback #pod版本回滚
6、报错信息
1)导入模板时报错

此时需要把apiserver监听端口改为0.0.0.0
2)创建模板后执行显示没有资源

查看系统日志/var/log/message

解决方法:修改apiserver配置文件vim /etc/kubernetes/apiserver
KUBE_ADMISSION_CONTROL="--admission-control=NamespaceLifecycle,NamespaceExists,LimitRanger,SecurityContextDeny,ServiceAccount,ResourceQuota"
删除认证模块,修改为如下代码
KUBE_ADMISSION_CONTROL="--admission-control=NamespaceLifecycle,NamespaceExists,LimitRanger,ResourceQuota"
重启apiserver。
service kube-apiserver restart
3、访问UI时报错
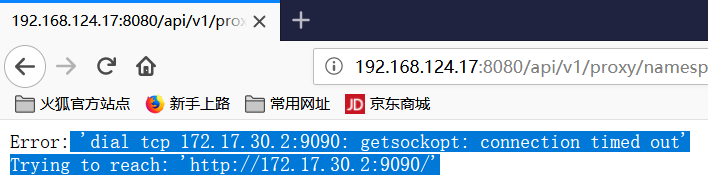
原因分析:连接远程服务器10.0.66.2的9090无法连接,应该属于网络的问题;
解决方法:
iptables -P FORWARD ACCEPT


 浙公网安备 33010602011771号
浙公网安备 33010602011771号