
一、缓存的思考

二、缓存算法

三、Caffeine中的算法剖析
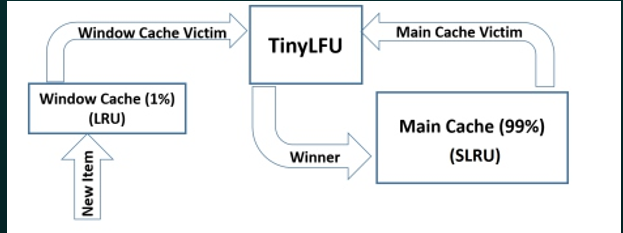
W-TinyLFU由两部分组成:
- Window Cache: 窗口缓存LRU回收策略,用于应对突发流量的问题。
- Main Cache: 主缓存使用TinyLFU+SLRU回收策略.
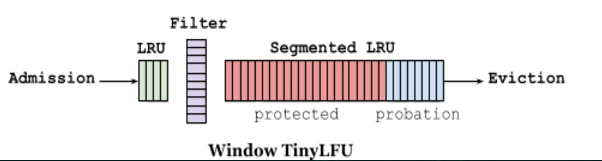
- 1.LRU:窗口缓存,占1%。用来应对突发流量。
- 2.Filter:sketch 作为过滤器。
- 3.SLRU:主缓存,占99%。
3.1 W-TinyLFU算法
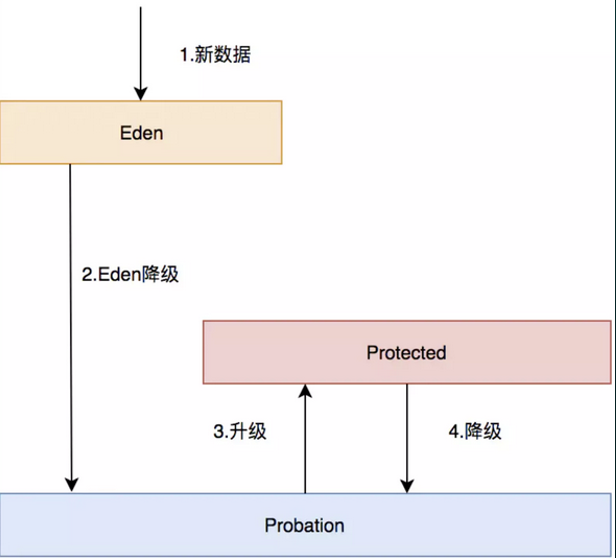
- 1.eden初始队列:1%,窗口缓存。
- 2.SLRU
- 1)Protected保护队列,它占用主缓存80%空间。
- 2)Probation缓刑队列,占用主缓存20%空间。
数据流:
- 1)新数据都会进入Eden。
- 2)Eden满了,淘汰进入Probation。
- 3)如果在Probation中被访问,进Protected。
- 4)Protected满了又会继续降级为Probation。
- 5)Probation内部进行队头队尾PK,淘汰一个。
3.2 Count-Min Sketch 算法
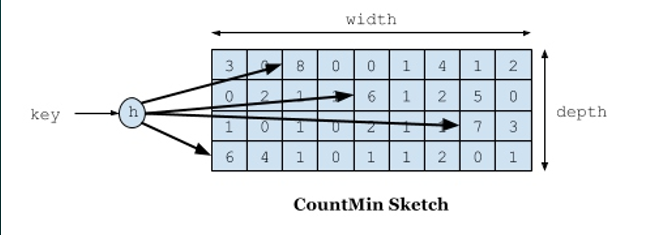
W-TinyLFU 使用 Count-Min Sketch 算法作为过滤器,该算法是布隆过滤器的一种变种。
Count-Min Sketch 算法:
根据不同的hash算法创建不同的数组,针对每一个数据进行多次hash,并在该hash算法的对应数组hash索引位置上+1,由于hash算法存在冲突,那么在最后取计数的时候,取所有数组中最小的值即可。
原理:一个hash函数碰撞几率较大,多个hash函数同时碰撞几率指数下降。
3.3 RingBuffer 算法
Caffeine缓存库在并发控制方面采用了RingBuffer和 MpscChunkedArrayQueue
---高性能无锁队列Disruptor的核心算法。
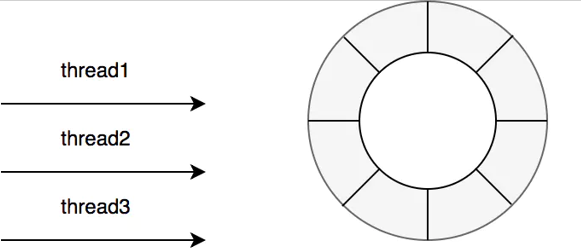
1.写操作是所有线程共享一个Ringbuffer。
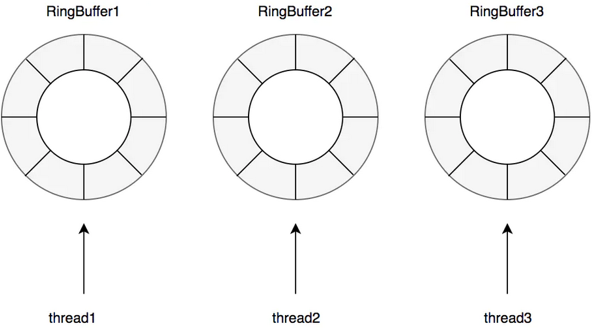
2.读操作比写操作更加频繁,进一步减少竞争,其为每个线程配备了一个RingBuffer.
---参考---
https://mp.weixin.qq.com/s/VkcwhWwHYrNu-yWKPxteZA
------------------个人能力有限,大家多交流,一起壮哉我大JAVA!------------------
如果你觉得本文对你有点帮助的话,记得在右下角点个“推荐”哦,博主在此感谢!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号