

学号20192317 2022-2022-2 《Python程序设计》实验四 Python综合实践报告
学号20192317 2022-2022-2 《Python程序设计》实验四 Python综合实践报告
课程:《Python程序设计》
班级: 1923
姓名: 邓子彦
学号:20192317
实验教师:王志强
实验日期:2022年5月27日
必修/选修: 公选课
一、实验内容
- Python综合应用:爬虫、数据处理、可视化、机器学习、神经网络、游戏、网络安全等。
- 注:在华为ECS服务器(OpenOuler系统)和物理机(Windows/Linux系统)上使用VIM、PDB、IDLE、Pycharm等工具编程实现。
(1)程序能运行,功能丰富。(需求提交源代码,并建议录制程序运行的视频)
(2)综合实践报告,要体现实验分析、设计、实现过程、结果等信息,格式规范,逻辑清晰,结构合理。
(3)在实践报告中,需要对全课进行总结,并写课程感想体会、意见和建议等。
(4)使用华为云服务(ECS或者MindSpore均可)
二、实验过程及结果
2.1 配置华为云服务器
-
实验截图

2.2 SSH连接华为云服务器方便操作
-
实验截图

2.3 华为云服务器上配置anaconda和python环境
-
实验截图

2.4 在pycharm上编写爬虫程序
-
实验截图
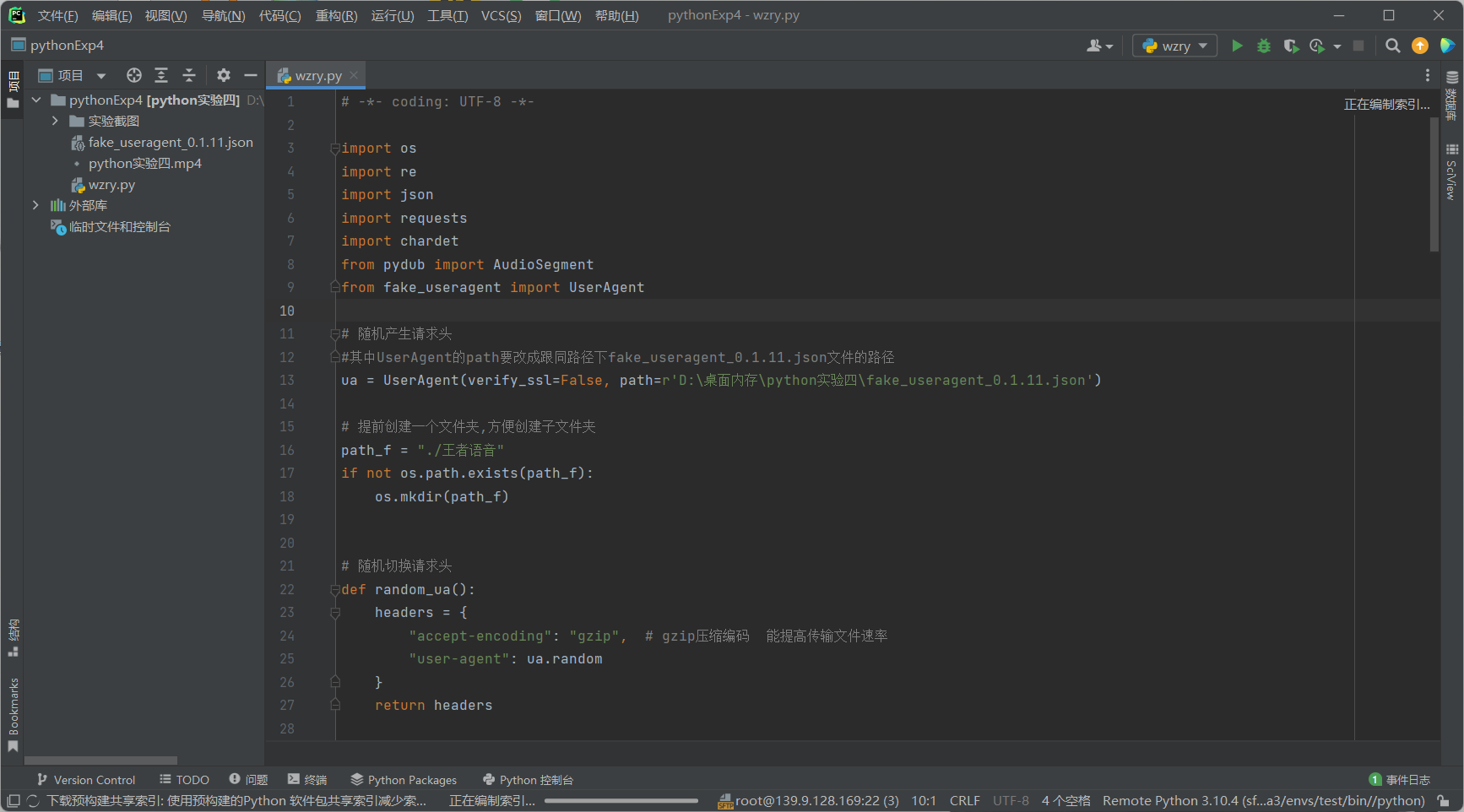
-
实验代码
# -*- coding: UTF-8 -*-
import os
import re
import json
import requests
import chardet
from pydub import AudioSegment
from fake_useragent import UserAgent
# 随机产生请求头
#其中UserAgent的path要改成跟同路径下fake_useragent_0.1.11.json文件的路径
ua = UserAgent(verify_ssl=False, path=r'D:\桌面内存\python实验四\fake_useragent_0.1.11.json')
# 提前创建一个文件夹,方便创建子文件夹
path_f = "./王者语音"
if not os.path.exists(path_f):
os.mkdir(path_f)
# 随机切换请求头
def random_ua():
headers = {
"accept-encoding": "gzip", # gzip压缩编码 能提高传输文件速率
"user-agent": ua.random
}
return headers
# 创建文件夹
def path_creat(name):
_path = "./王者语音/{}/".format(name)
if not os.path.exists(_path):
os.mkdir(_path)
return _path
# 下载语音内容
def download(file_name, text, path): # 下载函数
file_path = path + file_name
with open(file_path, 'wb') as f:
f.write(text)
f.close()
# 获取英雄名称及对应编号
def get_hero_num():
url = 'https://pvp.qq.com/web201605/js/herolist.json'
response = requests.get(url=url, headers=random_ua()).text
hero_list = re.findall('"ename": (.+?),', response, re.S) # 得到英雄的编号列表
hero_name = re.findall('"cname": "(.+?)"', response, re.S) # 得到英雄的名字列表
return hero_list, hero_name
def text_json():
url = 'https://pvp.qq.com/zlkdatasys/data_zlk_lb.json?callback=createList'
param = {
'callback': 'createList'
}
res = requests.get(url=url, headers=random_ua(), params=param)
res.encoding = chardet.detect(res.content)['encoding']
res = res.text.replace('createList(', '').replace(')', '') # 去掉不符合json格式的部分字符串数据
res_json = json.loads(res) # 将字符串json格式化
hero = res_json["yylb_34"] # 所有英雄语音信息
return hero
# 处理台词文本
def text_deal(text):
text_result = '' # 为台词连接做准备
for j in range(len(text)):
text_result += text[j] # 将台词连起来
text_result += '\n\n' # 加一个断句的换行符
text_result = text_result.encode(encoding='utf-8')
return text_result
def main():
hero_list, hero_name = get_hero_num() # 获取英雄编号及名称
hero_s = text_json()
for i in range(len(hero_s)): # len(hero_s)
hero = hero_s[i]["yxid_a7"] # 英雄编号
hero_index = hero_list.index(hero) # 获取英雄名称对应的索引
name_result = hero_name[hero_index] # 确定英雄名称
path = path_creat(name_result) # 创建子文件夹
voice_list = hero_s[i]["yy_4e"] # 语音列表
num = 1
text = []
silence = AudioSegment.silent(duration=1000) # 1秒的空期
try: # 有部分英雄的语音合成会失败
for j in range(len(voice_list)):
voice_text = voice_list[j]["yywa1_f2"] # 语音文本
text.append(voice_text) # 拼接文本
voice_url = 'http:' + voice_list[j]["yyyp_9a"] # 语音mp3的url
voice = requests.get(url=voice_url, headers=random_ua()).content
voice_name = name_result + '{}.mp3'.format(num)
download(voice_name, voice, path) # 下载单个语音
sound = AudioSegment.from_file(path + voice_name, format="mp3") # 读取下载的MP3文件
silence += sound # 语音合成
num += 1
silence.export(path + '{}.mp3'.format(name_result), format="mp3") # 导出合成语音
print(' '.format(name_result))
except:
print(' '.format(name_result))
text_result = text_deal(text) # 最终的文本
text_name = name_result + '.txt' # 语音文本文件名称
download(text_name, text_result, path) # 下载语音文本
print("{}的语音文本信息下载完毕!\n".format(name_result))
if __name__ == '__main__':
main()
2.5 在pycharm上连接华为云服务器
-
实验截图
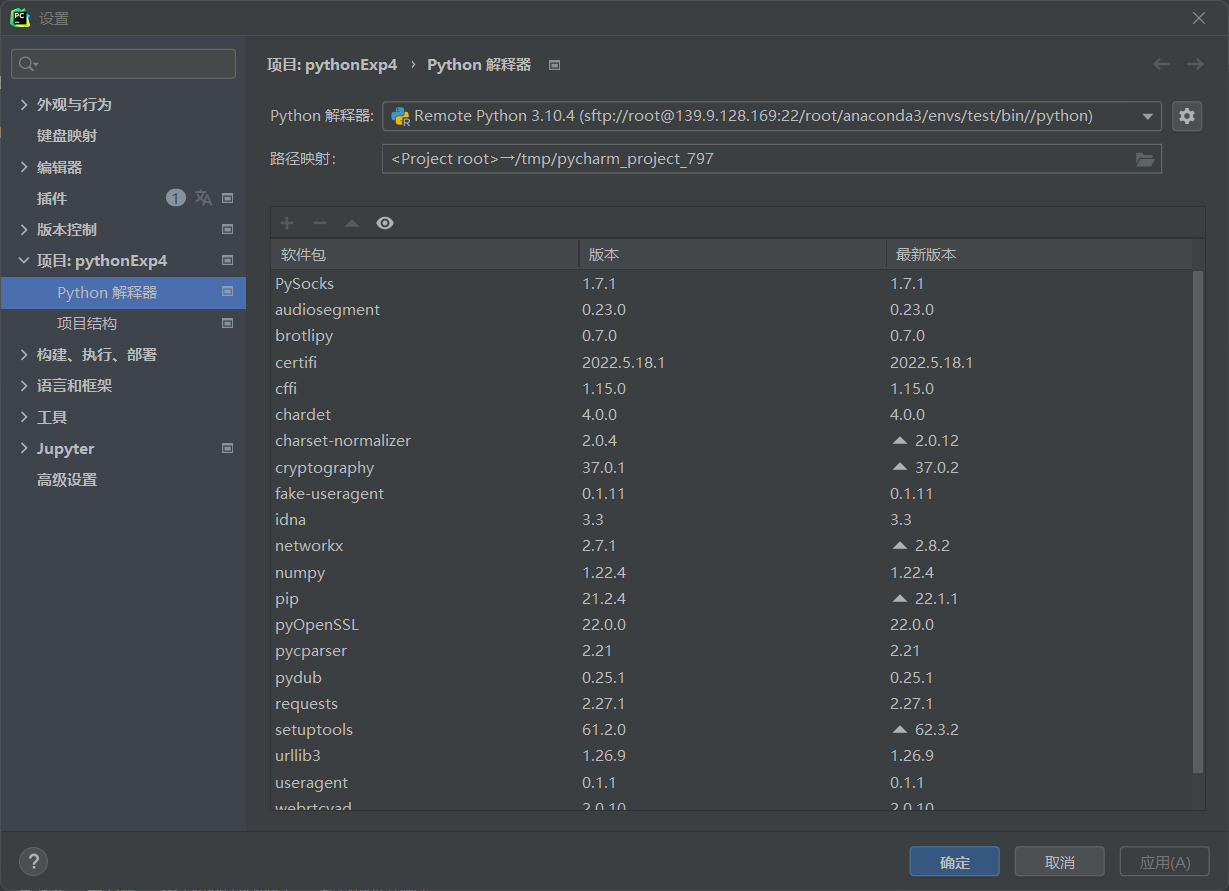
2.6 在华为云服务器上运行爬虫程序
-
实验截图
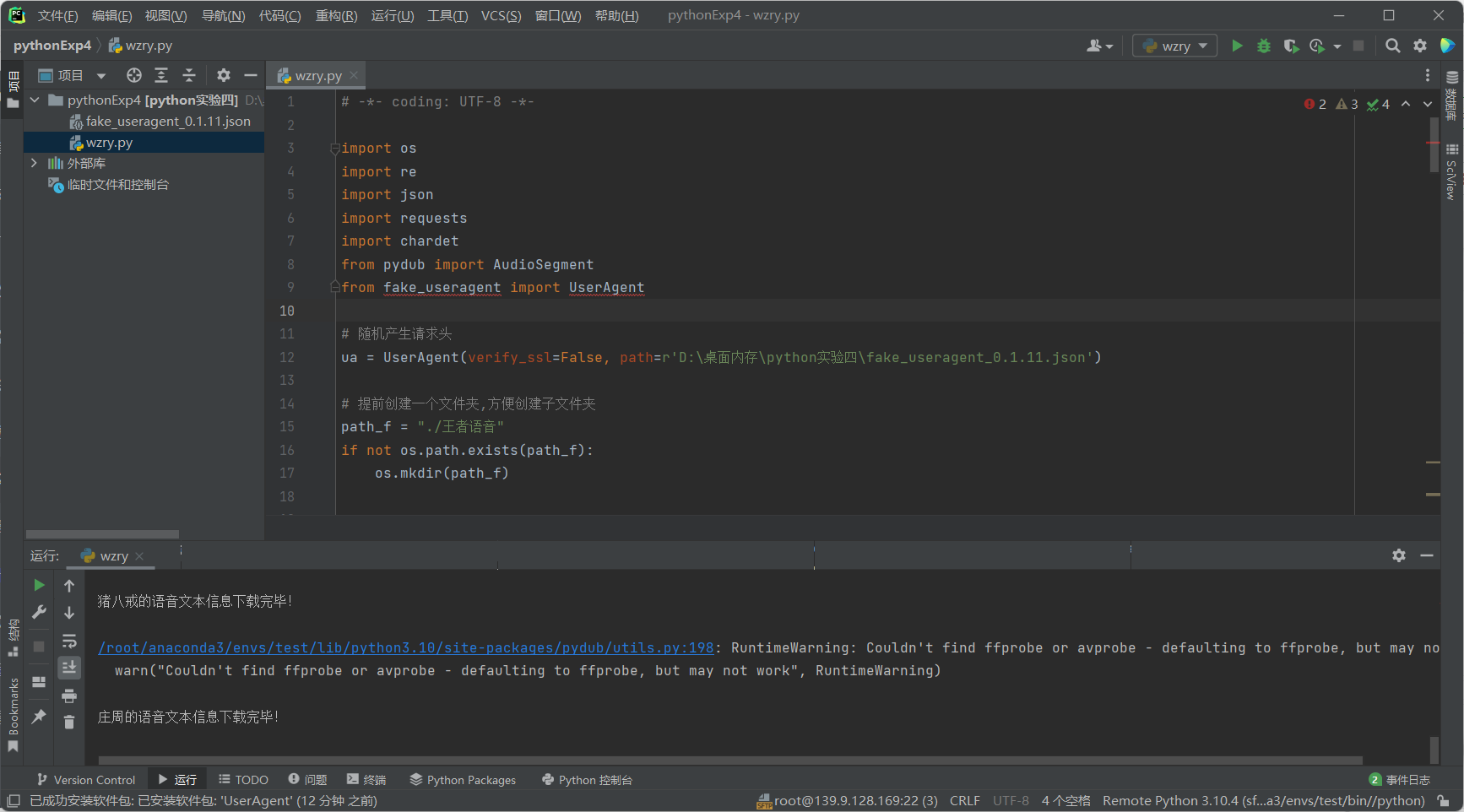
2.7 实验结果
2.7.1 云服务器运行结果
-
实验截图
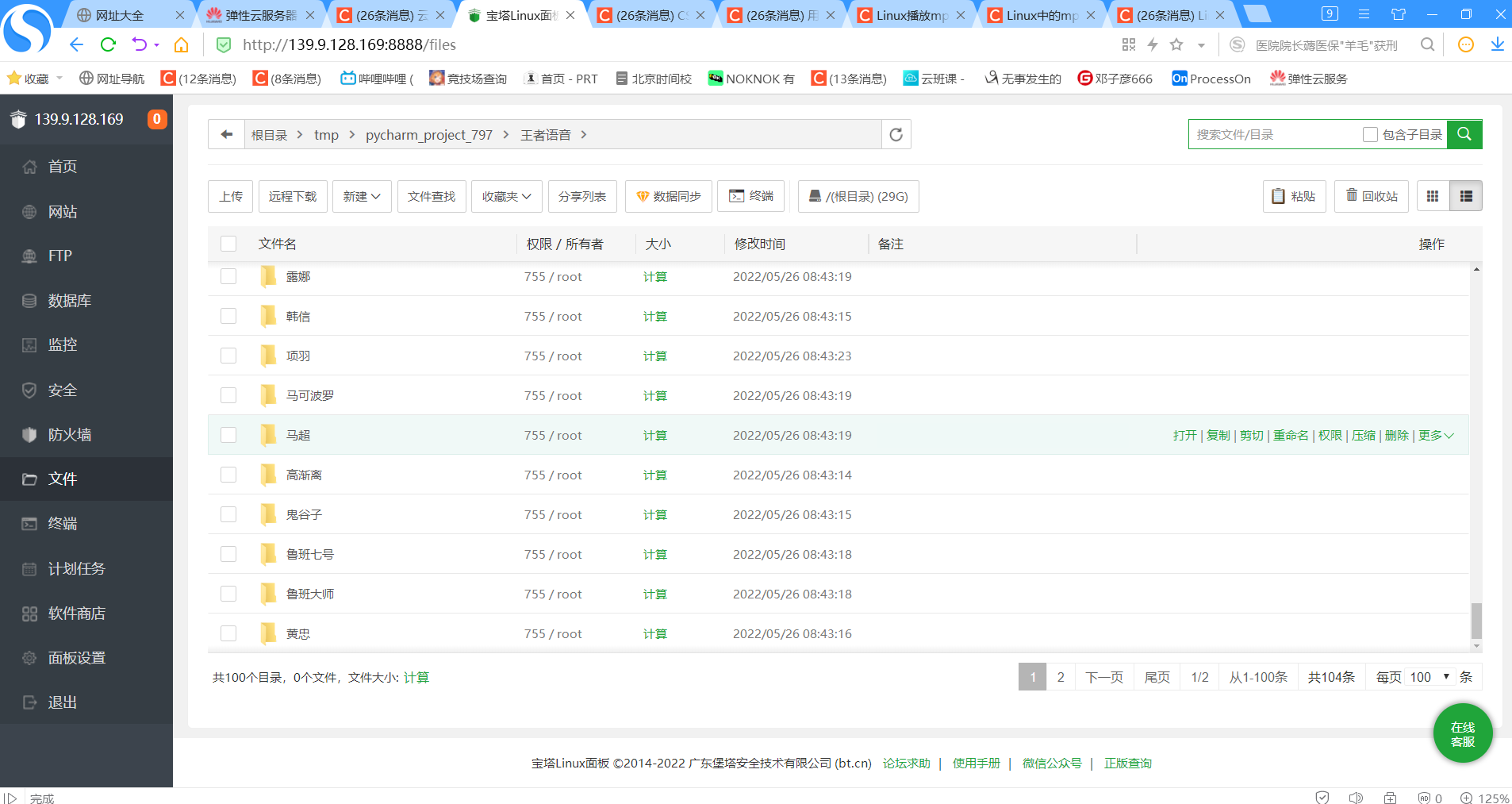
2.7.2 爬虫爬出来的文本
-
实验截图
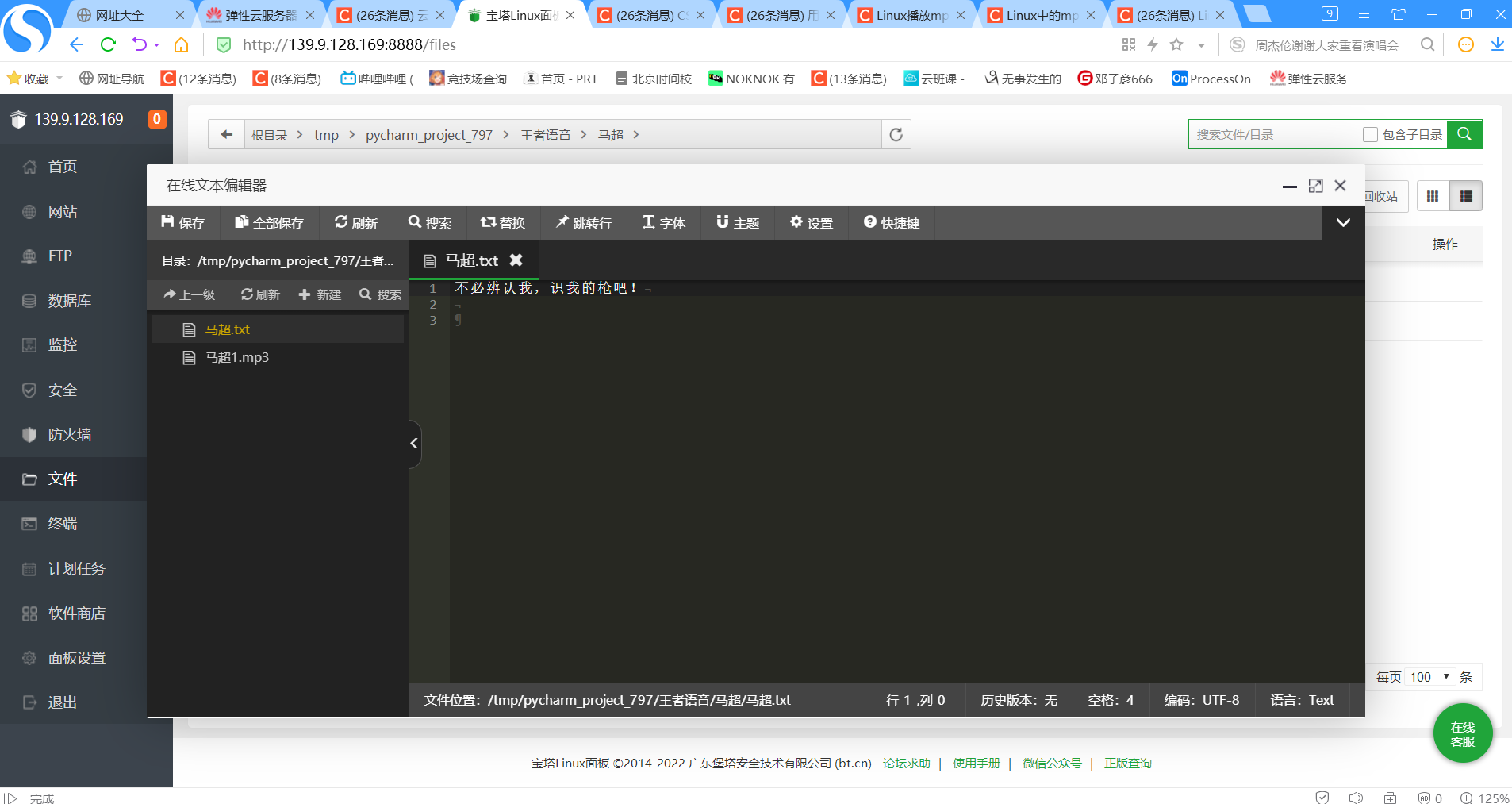
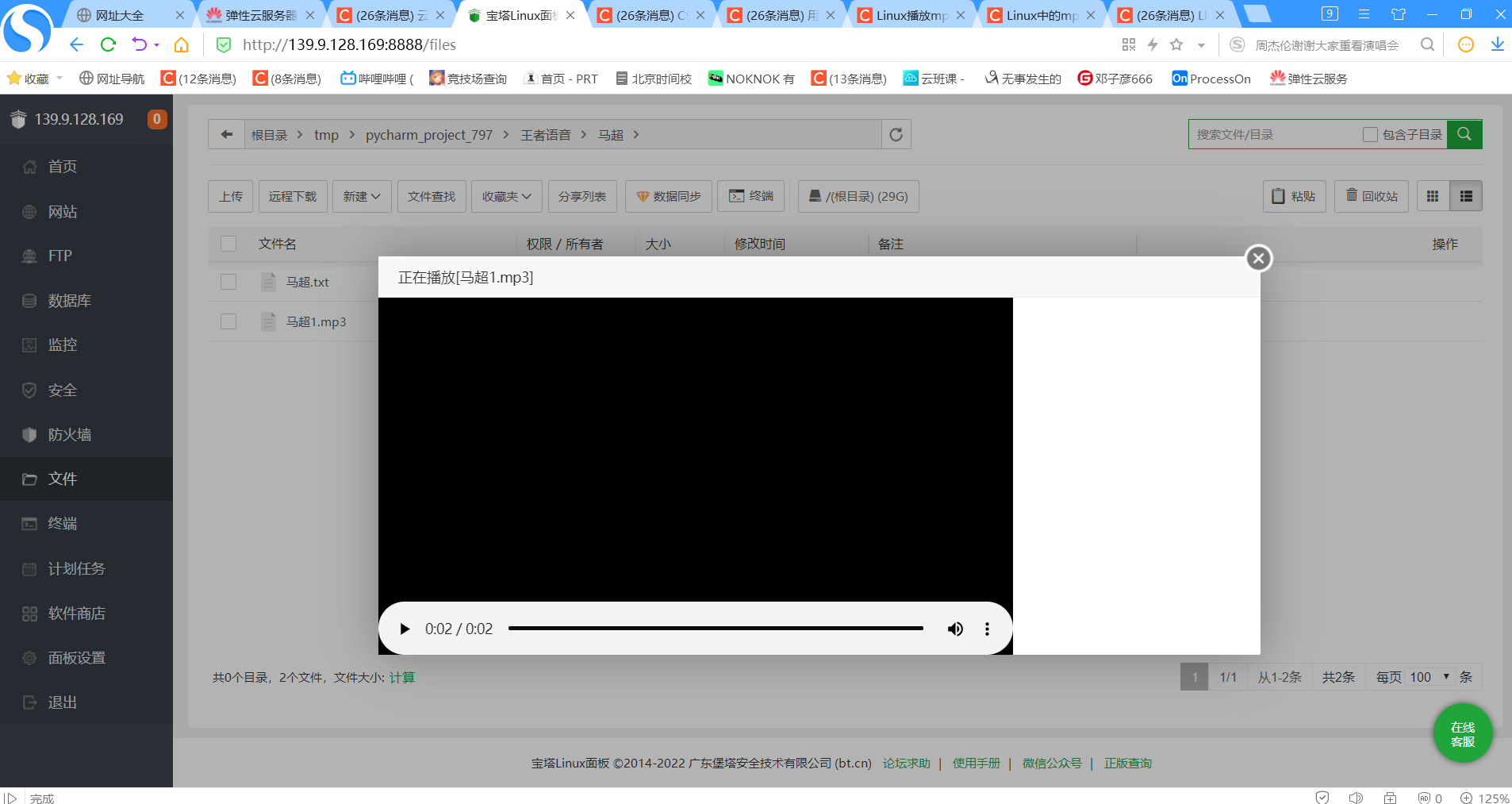
2.7.3 爬虫爬出来的语音
-
实验截图
三、实验过程中遇到的问题和解决过程
-
问题1:云服务器上面配置anaconda和python环境一直不成功
-
问题1解决方案:在CSDN上面找了很多教程都试着去走了一遍,最后有一个很简洁的教程一步步跟着走就配置好了,果然程序相关的东西本质都应该是非常简洁明了的,东西很多很全不一定是最好的
参考博客:https://blog.csdn.net/gaoping2736411763/article/details/106550342 -
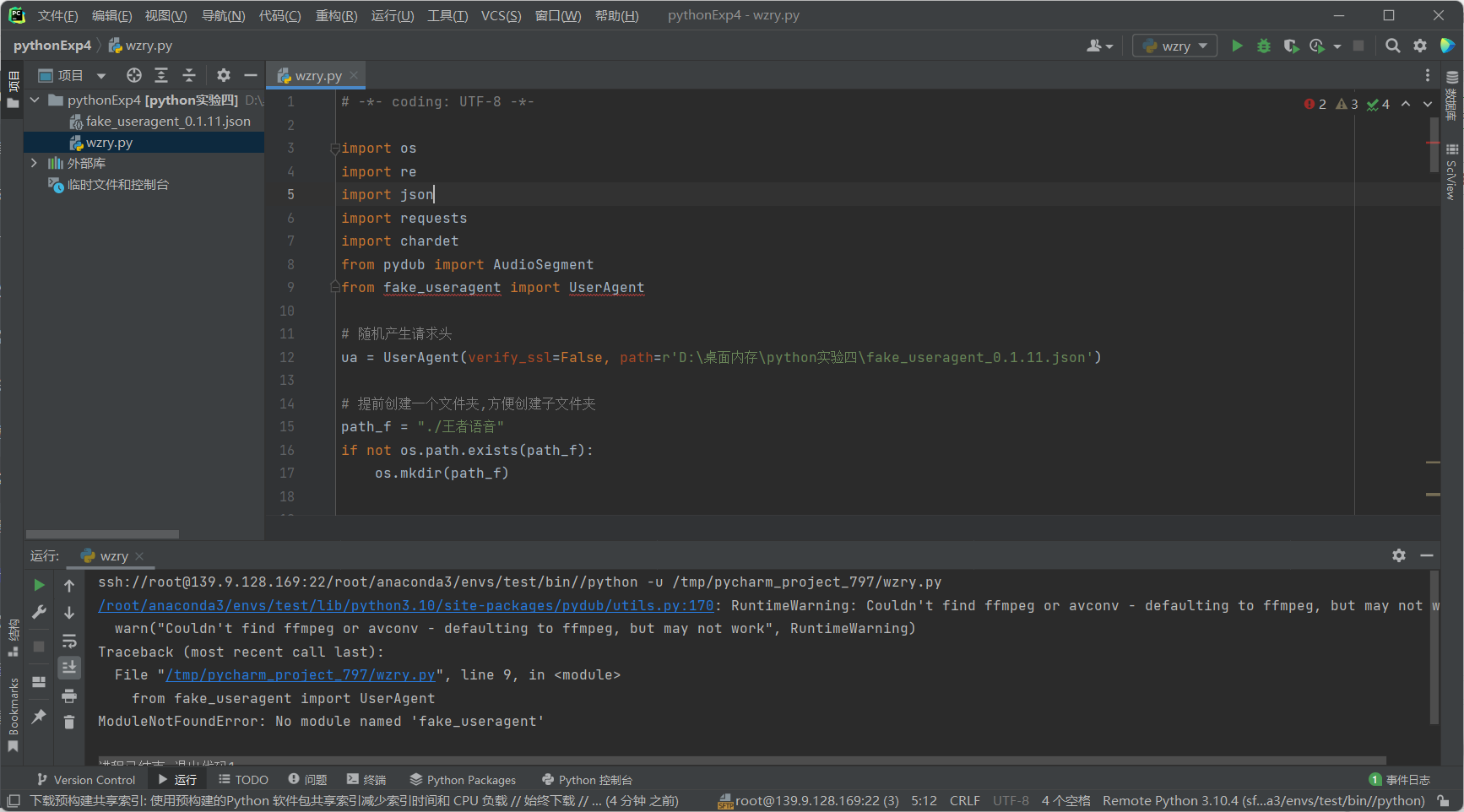
问题2:东西全都部署好之后,爬虫程序在pycharm上能跑,但是在云服务器上不能跑
-
截图
![]()
-
问题2解决方案:去CSDN搜了一下爬虫程序在云服务器不能跑的原因,大概知道了是因为我程序中fake_useragent的python包下载到云服务器上之后没有改程序中的调用路径,改了之后就成功了
四、课程总结
-
课程总结
- 非常喜欢王志强老师的python课,之前上过王老师的Java和数据结构课程,对于编程类的科目有一点基础,在王志强老师的带领了又打开了一门语言的大门。王老师非常年轻有活力,我也很欣赏王志强老师的授课风格和教学理念,很多东西是不需要我们死记硬背的,而是老师领进门之后自己凭借着兴趣去探索。
- python是一门非常有潜力的高级语言,历经多年的发展,其在编程上发挥着越来越大的作用。在这学期中,通过选修python课上的基础知识学习,我对python也有了一定的认识。而且,在字符串上的处理,python相对于c语言和Java也是给程序员极大的便利。而python不仅如此,它的库也很多,正因为它强大的库,让编程变得不再艰难。程序相关的东西本质都应该是非常简洁明了的,东西很多很全不一定是最好的
- 但是,我认为python虽然在许多方面相对于c语言比较方便,但也有其相对于弱一点的方面,比如说for循环等方面。虽然一学期下来,我对python的学习也仅仅只是它的基础方面,但python的强大,也是足足地吸引着我,希望自己能够在不断地学习中,将python学习的更加好。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号