

MobileNet系列
最近一段时间,重新研读了谷歌的mobilenet系列,对该系列有新的认识。
1.MobileNet V1
这篇论文是谷歌在2017年提出了,专注于移动端或者嵌入式设备中的轻量级CNN网络。该论文最大的创新点是,提出了深度可分离卷积(depthwise separable convolution)。
首先,我们分析一下传统卷积的运算过程,请参考第一个动图或者这篇博客。可以看出,传统卷积分成两步,每个卷积核与每张特征图进行按位相成然后进行相加,此时,计算量为$D_F*D_F*D_K*D_K*M*N$,其中$D_F$为特征图尺寸,$D_K$为卷积核尺寸,M为输入通道数,N为输出通道数。
然后,重点介绍一下深度可分离卷积。深度可分离卷积将传统卷积的两步进行分离开来,分别是depthwise和pointwise。从下面的图可以看出,首先按照通道进行计算按位相乘的计算,此时通道数不改变;然后依然得到将第一步的结果,使用1*1的卷积核进行传统的卷积运算,此时通道数可以进行改变。使用了深度可分离卷积,其计算量为$D_K*D_K*M*D_F*D_F+1*1*M*N*D_F*D_F$。

通过深度可分离卷积,计算量将会下降$\frac{1}{N}+\frac{1}{D_K^{2}}$,当$D_K=3$时,深度可分离卷积比传统卷积少8到9倍的计算量。
这种深度可分离卷积虽然很好的减少计算量,但同时也会损失一定的准确率。从下图可以看到,使用传统卷积的准确率比深度可分离卷积的准确率高约1%,但计算量却增大了9倍。

最后给出v1的整个模型结构,该网络有28层。可以看出,该网络基本去除了pool层,使用stride来进行降采样(难道是因为pool层的速度慢?)。

其次,v1还存在以下的亮点,值得关注一下:
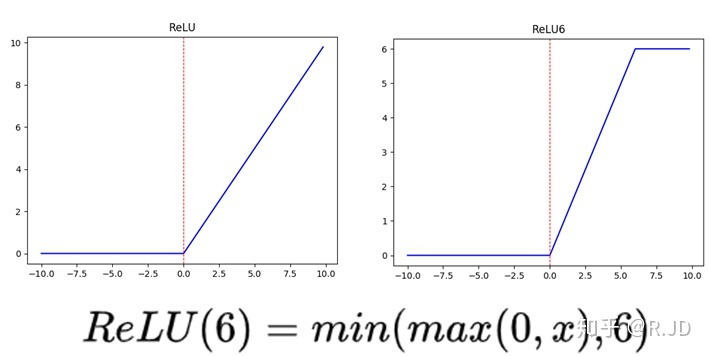
- depthwise后接BN层和RELU6,pointwise后也接BN层和RELU6,如下图所示(图中应该是RELU6)。左图是传统卷积,右图是深度可分离卷积。更多的ReLU6,增加了模型的非线性变化,增强了模型的泛化能力。

- v1中使用了RELU6作为激活函数,这个激活函数在float16/int8的嵌入式设备中效果很好,能较好地保持网络的鲁棒性。
- v1还给出了2个超参,宽度乘子$α$和分辨率乘子$β$,通过这两个超参,可以进一步缩减模型,文章中也给出了具体的试验结果。此时,我们反过来看,扩大宽度和分辨率,都能提高网络的准确率,但如果单一提升一个的话,准确率很快就会达到饱和,这就是2019年谷歌提出efficientnet的原因之一,动态提高深度、宽度、分辨率来提高网络的准确率。
2.MobileNet V2
MobileNet V2发表与2018年,时隔一年,谷歌的又一力作。V2在V1的基础上,引入了Inverted Residuals和Linear Bottlenecks。
为什么要引入这两个模块呢?参考这篇文章,有人发现,在使用V1的时候,发现depthwise部分的卷积核容易费掉,即卷积核大部分为零。作者认为这是ReLU引起的。文章的一个章节来介绍这个理论,但小弟水平有限,还理解不了。
简单来说,就是当低维信息映射到高维,经过ReLU后再映射回低维时,若映射到的维度相对较高,则信息变换回去的损失较小;若映射到的维度相对较低,则信息变换回去后损失很大,如下图所示。因此,认为对低维度做ReLU运算,很容易造成信息的丢失。而在高维度进行ReLU运算的话,信息的丢失则会很少。另外一种解释是,高维信息变换回低维信息时,相当于做了一次特征压缩,会损失一部分信息,而再进过relu后,损失的部分就更加大了。作者为了这个问题,就将ReLU替换成线性激活函数。

Inverted Residuals
这个可以翻译成“倒残差模块”。什么意思呢?我们来对比一下残差模块和倒残差模块的区别。
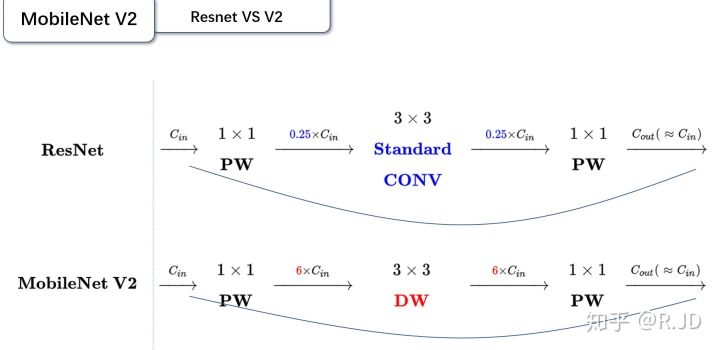
- 残差模块:输入首先经过1*1的卷积进行压缩,然后使用3*3的卷积进行特征提取,最后在用1*1的卷积把通道数变换回去。整个过程是“压缩-卷积-扩张”。这样做的目的是减少3*3模块的计算量,提高残差模块的计算效率。
- 倒残差模块:输入首先经过1*1的卷积进行通道扩张,然后使用3*3的depthwise卷积,最后使用1*1的pointwise卷积将通道数压缩回去。整个过程是“扩张-卷积-压缩”。为什么这么做呢?因为depthwise卷积不能改变通道数,因此特征提取受限于输入的通道数,所以将通道数先提升上去。文中的扩展因子为6。
Linear Bottleneck
这个模块是为了解决一开始提出的那个低维-高维-低维的问题,即将最后一层的ReLU替换成线性激活函数,而其他层的激活函数依然是ReLU6。
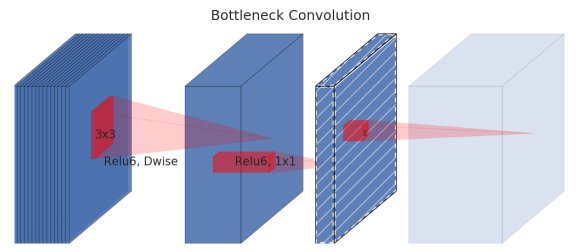
将两个模块进行结合,如下图所示。当stride=1时,输入首先经过1*1的卷积进行通道数的扩张,此时激活函数为ReLU6;然后经过3*3的depthwise卷积,激活函数是ReLU6;接着经过1*1的pointwise卷积,将通道数压缩回去,激活函数是linear;最后使用shortcut,将两者进行相加。而当stride=2时,由于input和output的特征图的尺寸不一致,所以就没有shortcut了。

最后,给出v2的网络结构。其中,t为扩张系数,c为输出通道数,n为该层重复的次数,s为步长。可以看出,v2的网络比v1网络深了很多,v2有54层。

当然,还不能少了性能对比图。v2的准确率比v1高出不少,延时也低了很多,是一款不错的轻量化网络。

3.MoblieNet V3
MobileNet V3发表于2019年,该v3版本结合了v1的深度可分离卷积、v2的Inverted Residuals和Linear Bottleneck、SE模块,利用NAS(神经结构搜索)来搜索网络的配置和参数。这种方式已经远远超过了人工调参了,太恐怖了。
v3在v2的版本上有以下的改进:
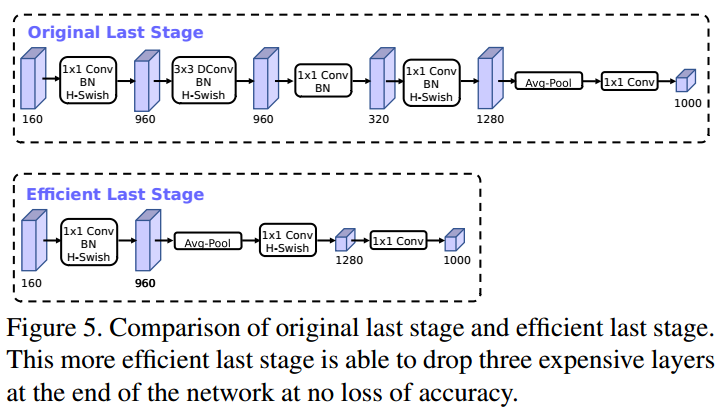
- 作者发现,计算资源耗费最多的层是网络的输入和输出层,因此作者对这两部分进行了改进。如下图所示,上面是v2的最后输出几层,下面是v3的最后输出的几层。可以看出,v3版本将平均池化层提前了。在使用$1\times 1$卷积进行扩张后,就紧接池化层-激活函数,最后使用$1\times 1$的卷积进行输出。通过这一改变,能减少10ms的延迟,提高了15%的运算速度,且几乎没有任何精度损失。其次,对于v2的输入层,通过$3\times 3$卷积将输入扩张成32维。作者发现使用ReLU或者switch激活函数,能将通道数缩减到16维,且准确率保持不变。这又能节省3ms的延时。
- 由于嵌入式设备计算sigmoid是会耗费相当大的计算资源的,因此作者提出了h-switch作为激活函数。且随着网络的加深,非线性激活函数的成本也会随之减少。所以,只有在较深的层使用h-switch才能获得更大的优势。
$$h\ switch[x]=x\frac{ReLU6(x+3))}{6}$$
- 在v2的block上引入SE模块,SE模块是一种轻量级的通道注意力模块。在depthwise之后,经过池化层,然后第一个fc层,通道数缩小4倍,再经过第二个fc层,通道数变换回去(扩大4倍),然后与depthwise进行按位相乘。

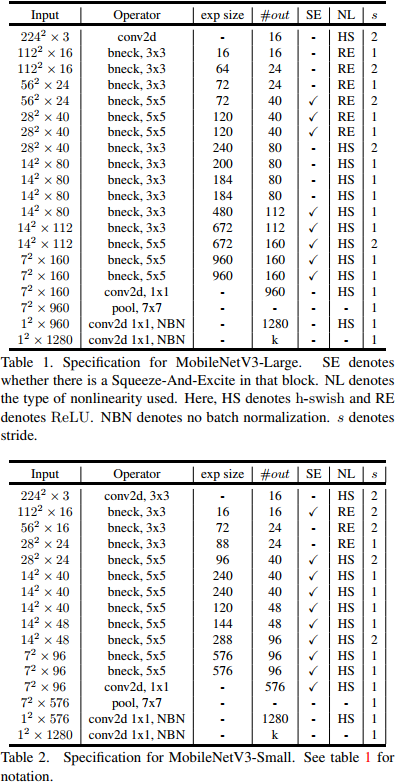
最后,v3的结构如下图所示。作者提供了两个版本的v3,分别是large和small,对应于高资源和低资源的情况。两者都是使用NAS进行搜索出来的。
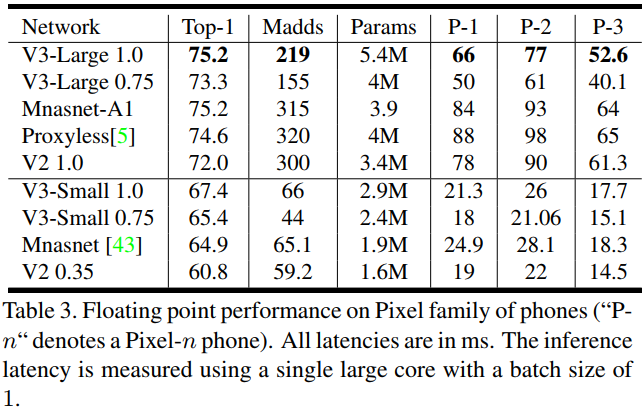
从下面的试验结果,可以看出v3-large的准确率和计算速度都高于v2。所以,AutoML搭出来的网络,已经能代替大部分调参了。
重新回顾了mobilenet系列,可以看出,准确率在逐步提高,延时也不断下降。虽然在imagenet上的准确率不能达到state-of-art,但在同等资源消耗下,其优势就能大大体现出来。
最后,给出3个版本的caffe模型:
mobilenet v1:https://github.com/shicai/MobileNet-Caffe/blob/master/mobilenet_deploy.prototxt
mobilenet v2:https://github.com/shicai/MobileNet-Caffe/blob/master/mobilenet_v2_deploy.prototxt
mobilenet v3:https://github.com/jixing0415/caffe-mobilenet-v3
参考文献
[1] https://zhuanlan.zhihu.com/p/70703846

 浙公网安备 33010602011771号
浙公网安备 33010602011771号