反序列化
反序列化:json数据转换成模型类数据(校验、入库)
反序列化的校验:
1、字段类型校验
2、字段选项校验
3、单字段校验(方法)
4、多字段校验(方法)
5、自定义校验(方法)
反序列的入库:
1、创建新的对象create
2、更新现有的对象update
'''序列化器反序列化书籍对象''' #1准备数据,前端传来的数据 book_dict = { 'btitle':'射雕英雄传', 'bpub_date':'1990-1-1', 'bread':10, 'bcomment':5 } #2创建序列化器 serializer = BookInfoSerializer(data=book_dict) #3校验 serializer.is_valid(raise_exception=True) #4输出 print(serializer.data)
字段选项的校验需要注意以下方面:
1.字段在没有指明选项require时,默认是require=True。也就是说这个字段是必填字段,反序列化时必须有该字段才能校验成功。
2.如果某字段选项指明了default选项,例如bcomment选项指明了default=0,那该字段反序列化时可以没有,因为已经指定了默认值
3.选项read_only=True,表示只读,也就是只能序列化,不需要反序列化
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
单字段校验:
针对某一字段,除了字段类型和选项的校验外,还可以制定更详细的校验,比如书籍名字必须包含“精品”两个字
单字段校验需要在序列化器中定义
from rest_framework import serializers from app.models import BookInfo #定义序列化器 class BookInfoSerializer(serializers.Serializer): id = serializers.IntegerField(label='id',read_only=True) #read_only=True表明该字段只能序列化,不能反序列化 #反序列化是将json数据转换成模型数据,入库,而id是自动生成的,因此不需要手动入库 btitle = serializers.CharField(max_length=20,label='名称') bpub_date = serializers.DateField(label='发布日期') bread = serializers.IntegerField(default=0,label='阅读量') bcomment = serializers.IntegerField(default=0,label='评论量') is_delete = serializers.BooleanField(default=False,label='逻辑删除') # 1关联英雄主键,一方序列化化多方必须加上many=True #heroinfo_set = serializers.PrimaryKeyRelatedField(read_only=True,many=True) #2关联英雄的__str__返回值 heroinfo_set=serializers.StringRelatedField(read_only=True,many=True) #1单字段校验 def validate_btitle(self,value): #value就是传入的btitle #1校验value中的内容 if '精品' not in value: raise serializers.ValidationError('书名不包含精品') return value
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
多字段校验:多用于两两比较的场合。例如如下需求:反序列化时要求书籍的阅读量必须大于评论量
#多字段校验 def validate(self,attrs): #attrs就是前端传来的字典book_dict #1获取阅读量,评论量 bread = attrs['bread'] bcomment = attrs['bcomment'] #2判断 if bcomment>bread: raise serializers.ValidationError('评论量大于阅读量') #3返回 return attrs
--------------------------------------------------------------------------------------------------------------------------------------------------------------------
序列化器反序列化入库新的数据
1、实现create方法,需要在序列化器中定义create方法
2、入库
3、返回数据
4、视图类中,反序列化保存
from rest_framework import serializers from app.models import BookInfo #定义序列化器 class BookInfoSerializer(serializers.Serializer): id = serializers.IntegerField(label='id',read_only=True) #read_only=True表明该字段只能序列化,不能反序列化 #反序列化是将json数据转换成模型数据,入库,而id是自动生成的,因此不需要手动入库 btitle = serializers.CharField(max_length=20,label='名称') bpub_date = serializers.DateField(label='发布日期') bread = serializers.IntegerField(default=0,label='阅读量') bcomment = serializers.IntegerField(default=0,label='评论量') is_delete = serializers.BooleanField(default=False,label='逻辑删除') # 1关联英雄主键,一方序列化化多方必须加上many=True #heroinfo_set = serializers.PrimaryKeyRelatedField(read_only=True,many=True) #2关联英雄的__str__返回值 heroinfo_set=serializers.StringRelatedField(read_only=True,many=True) #1单字段校验 def validate_btitle(self,value): #1校验value中的内容 if '精品' not in value: raise serializers.ValidationError('书名不包含精品') return value #多字段校验 def validate(self,attrs): #attrs就是前端传来的字典book_dict #1获取阅读量,评论量 bread = attrs['bread'] bcomment = attrs['bcomment'] #2判断 if bcomment>bread: raise serializers.ValidationError('评论量大于阅读量') #3返回 return attrs #创建create方法 def create(self, validated_data): ''' validated_data:校验成功后的数据 ''' #1入库 book = BookInfo.objects.create(**validated_data) #2返回 return book
#2创建序列化器 serializer = BookInfoSerializer(data=book_dict) #3校验 serializer.is_valid(raise_exception=True) #4输保存数据 serializer.save()
----------------------------------------------------------------------------------------------------------------------
序列化器反序列化更新数据时
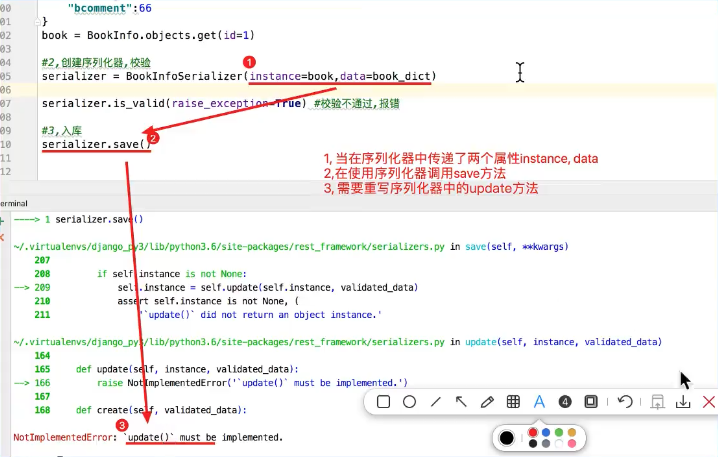
1.序列化器中实现update方法
#实现update方法 def update(self, instance, validated_data): #1更新数据 instance.btitle = validated_data('btitle') instance.bpub_date = validated_data('bpub_date') instance.bread = validated_data('bread') instance.bcomment = validated_data('bcomment') #2入库 instance.save() #3返回 return instance
2.视图中调用序列化器并保存数据
'''序列化器反序列化,update更新数据''' #1准备数据,前端传来的数据 book_dict = { 'btitle':'射雕英雄传', 'bpub_date':'1990-1-1', 'bread':10, 'bcomment':5 } book = BookInfo.objects.get(id=1) #2创建序列化器 serializer = BookInfoSerializer(instance=book,data=book_dict) #3校验 serializer.is_valid(raise_exception=True) #4输保存数据 serializer.save()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号