
Linux 安装配置 Ollama
Ollama 是一个开源的大型语言模型本地化运行框架,它的核心目标是让任何人都能像安装普通软件一样,在自己的电脑或服务器上简单、快速地部署和运行各类大语言模型
与依赖网络的云服务( 如 ChatGPT )或复杂的专业部署工具相比,Ollama 主要解决了 “简便性” 和 “本地化” 两大痛点:
- 极简部署:一个命令完成安装,再一个命令下载和运行模型,无需处理复杂的 Python 环境、依赖或配置
- 隐私与安全:所有数据都在本地计算,不会上传到云端,适合处理敏感信息
- 离线可用:一旦下载模型,无需网络即可随时使用
- 成本可控:利用现有硬件,无需支付 API 调用费用,适合长期、高频使用
- 开放生态:支持众多开源模型,从轻量级到高性能,可按需选择
Ollama 核心优势
- 开箱即用:提供统一、简单的命令行接口。无论模型底层是 PyTorch 还是 GGUF 格式,用户只需关心 ollama run <模型名>
- 性能优化:内置高效推理引擎,对 CPU 和 GPU(尤其是NVIDIA)提供了良好支持,能自动利用硬件加速
- 开放模型库:内置 ollama pull 命令可直接从官方库下载数百个热门模型,也支持导入自定义模型
- 跨平台支持:完美支持 macOS、Linux、Windows。在 Linux 服务器上作为无界面后端服务运行时尤其稳定
- 生产就绪的 API:除了命令行交互,它还提供标准的 REST API(默认端口 11434),方便与其他应用(如聊天界面、自动化脚本)集成
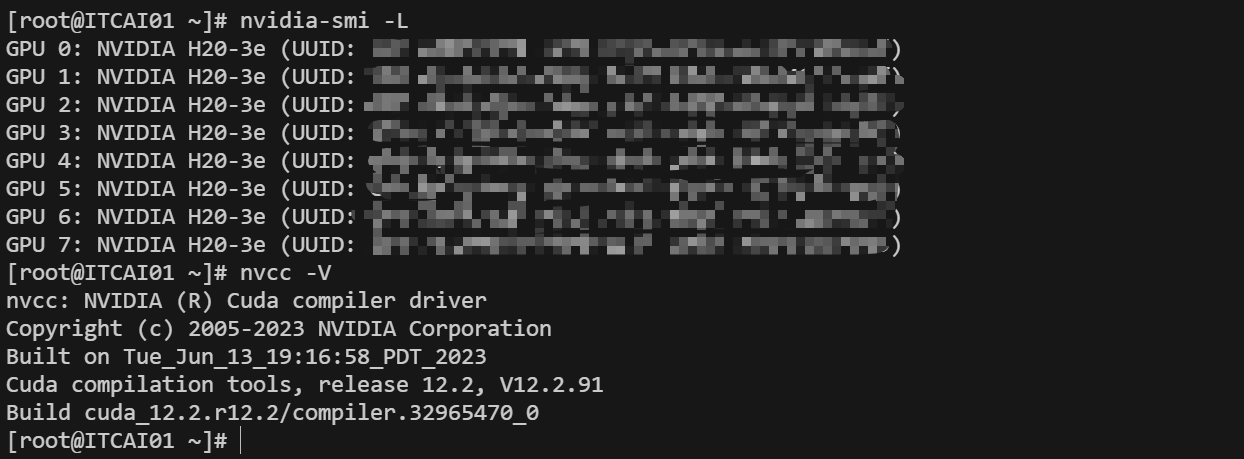
Ollama 支持在纯 CPU 模式下运行,这是它的一大优势,但拥有显卡(尤其是 NVIDIA GPU)会大幅提升性能
为了高效使用 Ollama,需确保成功安装 NVIDIA drivers 和 CUDA
如下图所示,表示已成功安装
# 第一步:安装 Ollama,Ollama 提供了多种安装方式,其中使用官方安装脚本最为便捷
curl -fsSL https://ollama.com/install.sh | sh
# 第二步:管理 Ollama 服务
启动服务: systemctl start ollama # 启动 Ollama 后台服务
设置自启 :systemctl enable ollama # 开机自动启动 Ollama
查看状态: systemctl status ollama # 检查服务是否正常运行
重启服务: systemctl restart ollama # 修改配置后重启生效
查看日志: journalctl -u ollama -f # 实时查看服务日志,用于排错
# 第三步:验证与基础使用
1. 拉取并运行模型
例如,拉取一个 gpt-oss:20b 模型进行对话:
# 拉取模型(首次使用会自动下载)
ollama pull gpt-oss:20b
# 启动对话
ollama run gpt-oss:20b
2. 以服务方式调用
更常见的用法是让 Ollama 在后台作为 API 服务,供其他程序调用。安装后它默认已在 http://127.0.0.1:11434 提供 API
测试:curl -s http://127.0.0.1:11434/api/tags | jq -r '.models[].name' 和 ollama list 可以列出已安装的模型
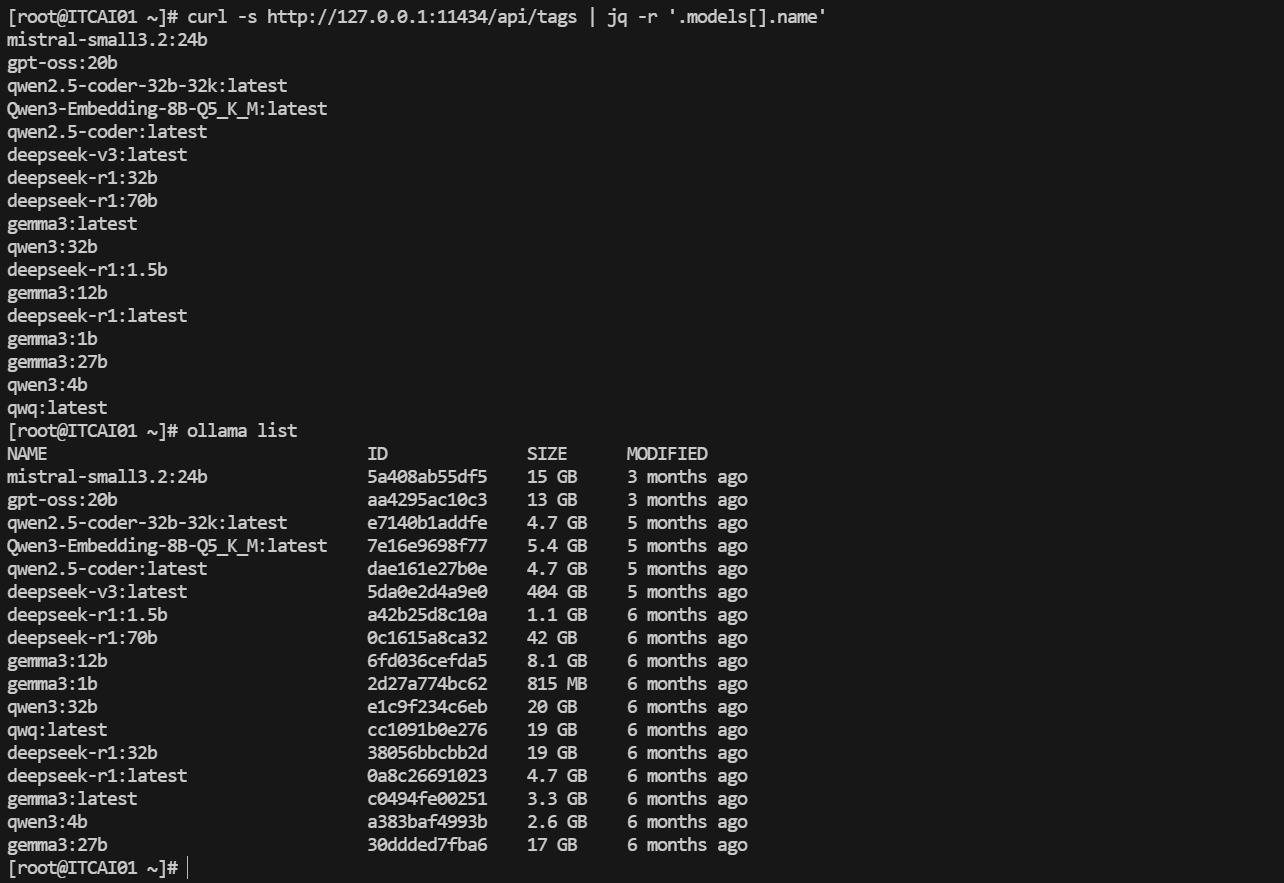
常见模型的对比:

# 第四步:常用命令与管理
ollama list # 列出本地所有模型
ollama pull <模型名> # 下载新模型(如:deepseek-v3:latest )
ollama rm <模型名> # 删除本地模型
ollama cp <源> <目标> # 复制模型(创建新名称)
ollama show <模型名> # 查看模型的详细信息
ollama run deepseek-v3:latest "你是什么模型" # 直接运行一次性命令而不进入交互模式

# 其它主机访问
curl -sX POST http://ITCAI01:11434/api/generate -H "Content-Type: application/json" -d '{"model": "gpt-oss:20b","prompt": "你是什么模型","stream": false}' | jq -r '.response'
# -X POST 指定 POST 的请求类型
# -H(Header - 请求头):控制通信的规则、格式和元信息,告诉服务器 "如何" 处理接下来的请求 。"Content-Type: application/json" 指定 HTTP 头信息为 json 格式
# -d(Data - 请求体):提供实际要发送的数据内容,告诉服务器 "具体做什么", 通常配合 -H 使用。model 指定使用的模型,prompt 输入给模型的提示词或问题,stream 控制响应数据是否以“流”的形式返回
model 指定要使用的模型

# 如果 Ollama 服务只监听本地端口(即 127.0.0.1 ),其它主机访问则需要如下设置:
# 临时设置(仅当前终端有效)
export OLLAMA_HOST="0.0.0.0:11434" # 允许网络其他主机访问
export OLLAMA_NUM_PARALLEL=50 # 设置并行请求数
export OLLAMA_MODELS="/path/to/your/models" # 自定义模型存储路径
# 永久设置(两种方法任选其一即可)
1. 将上述 export 行添加到你的 ~/.bashrc 文件中,然后执行 source ~/.bashrc
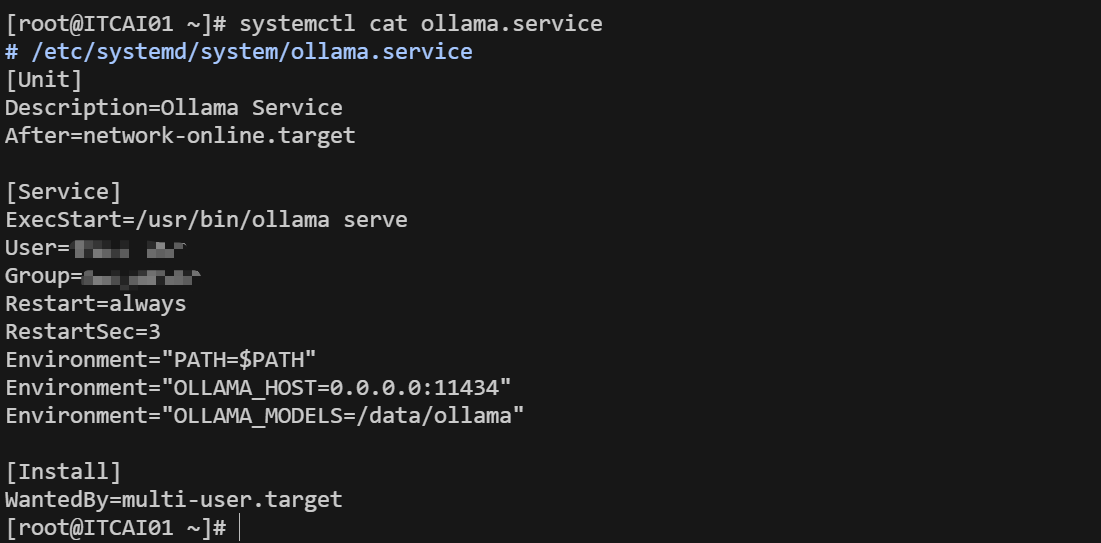
2. 设置 ollama systemd 服务的 service 文件,示例如下:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号