CTAP: Complementary Temporal Action Proposal Generation (ECCV2018)
互补时域动作提名生成
这里的互补是指actionness score grouping 和 sliding window ranking这两种方法提proposal的结合,这两种方法各有利弊,形成互补。
滑窗均匀覆盖所有的视频片段,但时域边界不准确,聚合方法可能更准确但当actionness score比较低的时候,也会漏掉一些proposal。
整体思路:
用actionness score proposal训好PATE网络作用在滑窗proposal上,以此来收集被actionness score grouping遗漏的proposal。
这些proposal经过时域卷积用于proposal ranking和边界回归。本论文在TURN的基础上做的改进。
三种主流方法:
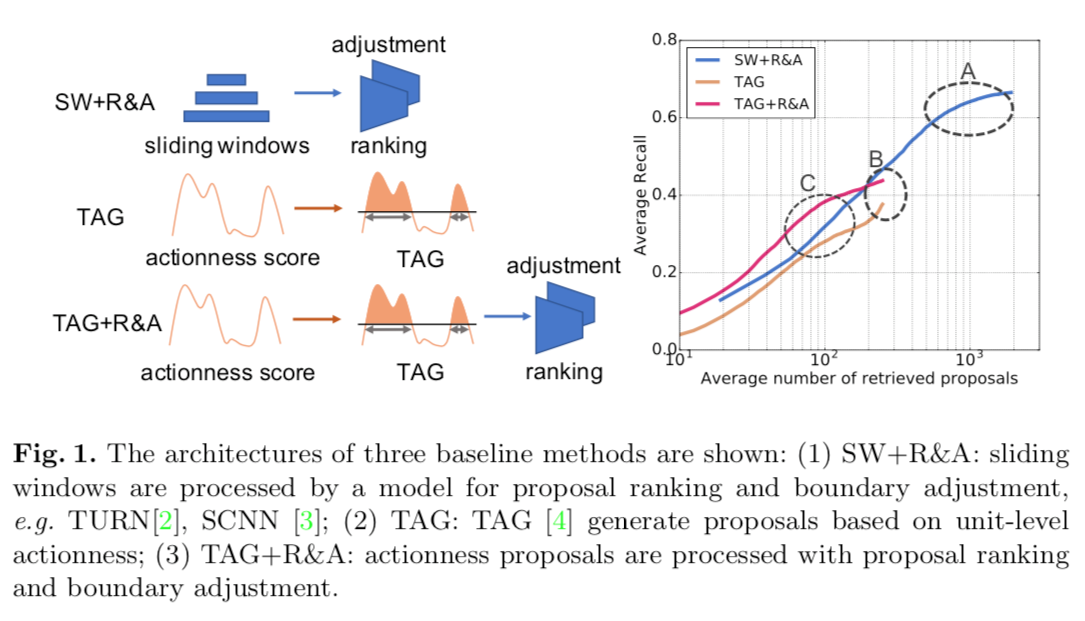
第一种方法的缺点是边界不准,当收集大量proposal时才会产生较高的recall。
第二种方法在更细的粒度上(unit / snippet)训练二分类器,产生actionness score。TAG算法是merge的处理算法,源自watershed算法,用于将连续的高分区域聚合成proposal,避开的硬阈值聚合的缺点,是ssn那篇文章提出的方法。边界更加准确。当这种方法有两个常见的缺点:
1. 在背景片段产生高分响应,导致fp。
2. 在动作片段产生低分响应,导致低recall。
解决方案:
缺点1的方案. actionness proposal是细粒度的,边界更加准确。window-level ranking 加入了全局上下文信息而更有区分性。
window-level分类器用于TAG后处理,以及proposal的排序和边界回归。
缺点2的方案. 滑窗均匀覆盖了视频的所有片段。
适应性的选择滑窗产生的proposal来弥补actionness遗漏的proposal
CTAP:
产生actionness proposals和滑窗proposals,用proposal互补分类器从滑窗proposal中选择漏掉的正确proposal,这个两类分类器用于区分proposal是否被actionness和TAG正确检测到。最后一步是proposal ranking和时域边界微调。相比作者的另一篇TURN中的简单时域平均池化,这里使用了时域卷积。可以有效的保存顺序信息
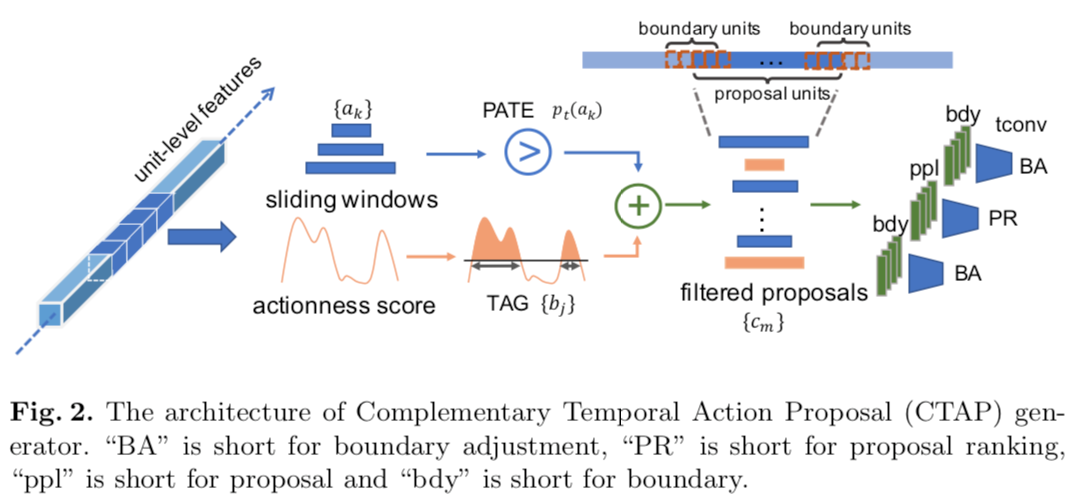
这里的时序卷积就是时域上的一维卷积
Initail Proposal Generation
Video pre-processing:视频被切分为许多视频单元,每个单元包含连续的n帧,应用双流提取对应单元的特征。
Actionness score:训练一个二分类器对每一个单元产生actionness score
![]()
设计了两层时序卷积网络,输入是ta个连续的特征单元![]() ,输出动作还是背景的概率
,输出动作还是背景的概率![]() 。
。
交叉熵loss,N是batchsize:
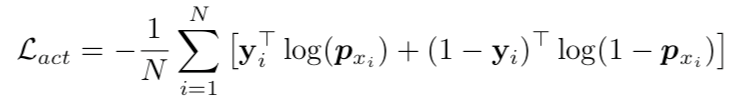
![]() 表示二值序列,对每一个输入xi表示在xi内的每一个单元有动作1,没动作0。
表示二值序列,对每一个输入xi表示在xi内的每一个单元有动作1,没动作0。
Actionness proposal generation strategy:ssn的枚举双阈值TAG算法,group proposals
Sliding window sampling strategy
Proposal Complementary Filtering
输入是平均池化后的ground truth feature,与actionness proposal相比tIoU大于阈值yi=1,小于则yi=0。
![]()
![]()
Loss:N batchsize
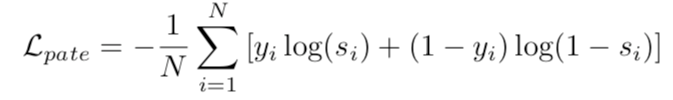
Complementary filtering
PATE网络:分类出这个proposal多大概率可以被actionness score检测出来,对于一个滑窗产生的proposal,如果低于阈值,那么TAG将无法检测出来,这个proposal将和actionness proposal合并在一起。
Proposal Ranking and Boundary Adjustment
TAR Architecture :在proposal内均匀采样nctl个单元。![]() ,分别以开始单元和结束单元采样nctx个单元作为边界单元,,proposal ranking网络输出动作概率,边界微调网络输出回归偏移,每个网络有两层时域卷积
,分别以开始单元和结束单元采样nctx个单元作为边界单元,,proposal ranking网络输出动作概率,边界微调网络输出回归偏移,每个网络有两层时域卷积
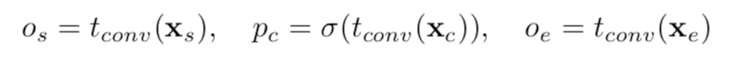
滑窗的proposal score计算:![]()
actionness score:![]()
TAR Training : 收集训练样本,使用密集滑窗并和groundtruth比较
(1) 和其他windows相比在某个gt上有最大的tIoU
(2) 与任意一个gt比,它的tIoU大于0.5
标准softmax 交叉熵loss训练proposal ranking 网络,L1 loss 训练边界回归网络
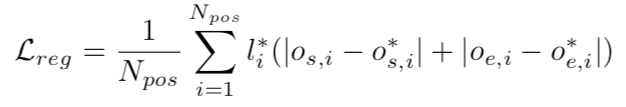
osi是预测的起始位置偏移,oei是预测结束位置偏移,星号的是gt相对proposal的偏移,当l为1时考虑回归loss
交叉熵loss:和pate的交叉熵loss相似,学出proposal为动作的概率
Thumos14 result

Experiment
Unit-level feature extraction:
(1)RGB CNN特征,从一个unit中均匀采8帧,提取ResNet中的Flatten_673特征(用Activity v1.3预训练),然后计算这8个feature的平均值作为这个unit的特征。
(2)dense flow CNN,在unit中心取连续的6帧并计算对应的光流,将flow送入BN-Inception(用Activity v1.3预训练)中,取global_pool特征
双流feature的每一种特征都是2048维,concat在一起。
unit features Flow-16 只使用flow feature unit size 为 16;Twostream-6 使用 two-stream features unit size 为 6
Sliding window sampling strategy:
和TURN一致,采用的proposal长度为{16, 32, 64, 128, 256, 512} ,Activitynet1.3: {64, 128, 256, 512, 768, 1024, 1536, 2048, 2560, 3072, 3584, 4096, 6144} tIOU of 0.75
Actionness score generation 这里介绍一些超参,连续特征单元数ta=4。
TAR setting:在每个proposal内部均匀采样8个单元feature,4个单元作为context
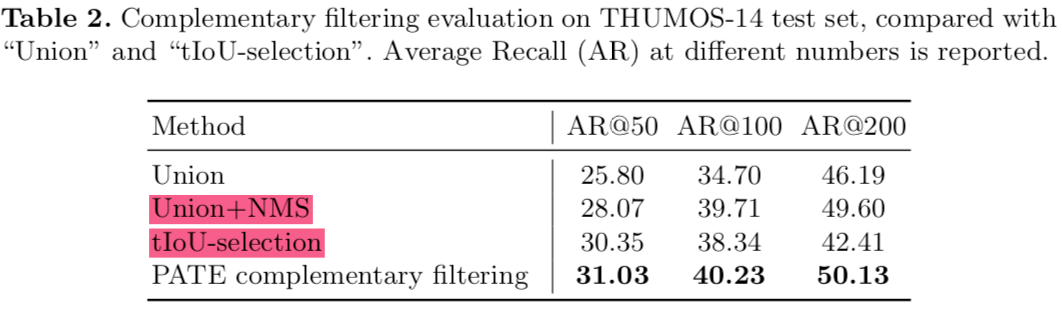
对比实验了PATE模块

 浙公网安备 33010602011771号
浙公网安备 33010602011771号