CCF-CSP 第三题字符串整理(模拟大法好)
URL映射
- 规则的相邻两项之间用‘/’分开,所以我们先把所有项分开,然后依次把两个字符串的对应项匹配即可。
- 分离字符串这里用字符串流(stringstream)处理,先把所有的‘/’变为空格,然后一个一个把各项分开。
- 在把‘/’变为空格的时候,要注意行末的‘/’,比如:
/okokokok 与 /okokokok/是无法匹配成功的。同样的:/<str>/ 与/okokok也无法匹配成功。 - 模拟,注意细节和边界即可。
1 #include<iostream> 2 #include<sstream> 3 #include<cstring> 4 #include<string> 5 #include<cstdio> 6 #include<vector> 7 #include<algorithm> 8 #define LL unsigned long long 9 using namespace std; 10 const int maxn=101; 11 int cnt1[maxn],isp,sp[maxn]; //cnt1[i]--第i个字符串的项数,isp--待查询的字符串末尾是否为‘/’,sp[i]--第i个字符串末尾是否为‘/’ 12 string str[maxn],str1[maxn],str2; //str[i]--第i个字符串的配置信息,str1[i]--第i个映射规则,str2--当前需要被查询的字符串 13 string sp1[maxn][maxn],sp2[maxn]; //sp1[i]--保存第i个字符串的所有项,sp2--保存当前被查询字符串的所有项。 14 string is_num(string s){ //判断某一项是否为整数:是--去掉前导0并返回整数;不是--返回“-” 15 int ok=0; 16 string ss=""; 17 int len=s.length(); 18 for(int i=0;i<len;i++){ 19 if(s[i]<'0'||s[i]>'9')return "-"; 20 if(ok||s[i]!='0')ss+=s[i],ok=1; 21 } 22 if(ss=="")ss="0"; 23 return ss; 24 } 25 void getinfo(string s,string s1[],int &f,int &t){ //分离并保存一个字符串的所有项,标记末尾是否为‘/’ 26 f=t=0; 27 int len=s.length(); 28 if(s[len-1]=='/')f=1; 29 for(int p=0;p<len;p++){ 30 if(s[p]=='/')s[p]=' '; 31 } 32 string ss; 33 stringstream in(s); 34 while(in>>ss)s1[t++]=ss; 35 } 36 bool match(int t,int j,string &s){ //判断被查询字符串与第j个规则是否能匹配 37 s=""; 38 int p1=0,p2=0; 39 while(p1<t&&p2<cnt1[j]){ 40 if(sp2[p1]==sp1[j][p2]); 41 else if(sp1[j][p2]=="<int>"){ 42 string f=is_num(sp2[p1]); 43 if(f=="-"){return 0;} 44 s+=" "+f; 45 } 46 else if(sp1[j][p2]=="<str>"){s+=" "+sp2[p1];} 47 else if(sp1[j][p2]=="<path>"){ //<path>直接全部加上 48 s+=" "+sp2[p1++]; 49 while(p1<t)s+="/"+sp2[p1++]; 50 if(isp)s+='/'; 51 return 1; 52 } 53 else return 0; 54 p1++;p2++; 55 } 56 if(isp^sp[j])return 0; //末尾判断--同时有‘/’或同时无‘/’才能匹配 57 if(p1!=t||p2!=cnt1[j])return 0; //完全匹配 58 return 1; 59 } 60 int main(){ 61 freopen("in.txt","r",stdin); 62 int n,m; 63 cin>>n>>m; 64 for(int i=0;i<n;i++){ 65 cin>>str1[i]>>str[i]; 66 getinfo(str1[i],sp1[i],sp[i],cnt1[i]); //string, split, 末尾是否'/', 字符串数量 67 } 68 for(int i=0;i<m;i++){ 69 string ans; 70 int cnt=0;isp=0; 71 cin>>str2; 72 getinfo(str2,sp2,isp,cnt); 73 bool ok=0; 74 for(int j=0;j<n;j++){ 75 if(match(cnt,j,ans)){ 76 cout<<str[j]<<ans<<endl;; 77 ok=1;break; 78 } 79 } 80 if(!ok)cout<<404<<endl; 81 } 82 return 0; 83 }
路径解析
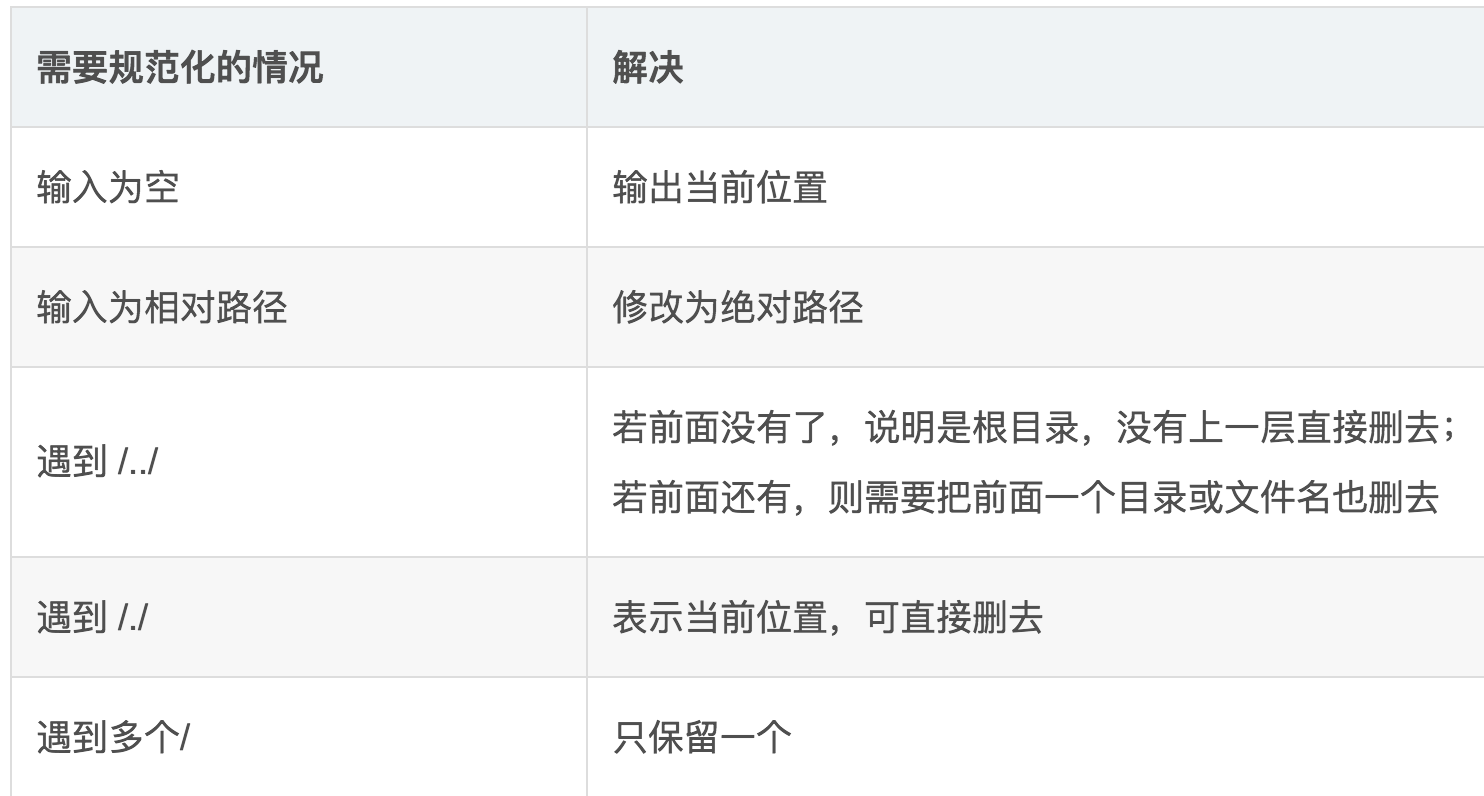
以及末尾有/
1 #include<iostream> 2 #include <string> 3 #include <vector> 4 using namespace std; 5 int main() 6 { 7 int num,pos,pos1; 8 string curDir,line; 9 cin >> num >> curDir; 10 getchar(); // 使用getline要注意处理回车符 11 while (num--) 12 { 13 getline(cin, line); // 读空字符串 14 15 if (line.empty())line = curDir; // 16 else if (line[0] != '/')line = curDir + "/" + line; // 1.首位不为'/'的情况,将相对路径转化为绝对路径 17 18 while ((pos = line.find("//")) != -1) line.erase(pos, 1);// 2.出现/// 19 20 while ((pos = line.find("/../")) != -1) // 3.出现/../ 21 { 22 if (!pos)line.erase(0, 3); 23 else{ 24 pos1 = line.rfind("/", pos - 1); 25 line.erase(pos1, pos - pos1 + 3); 26 } 27 } 28 while ((pos = line.find("/./")) != -1)line.erase(pos, 2);// 4.出现/./ 29 30 if (line.size()>1 && line[line.size() - 1] == '/')line.erase(line.size() - 1, 1);// 5.末尾有/ 31 32 cout << line << endl; 33 } 34 return 0; 35 }、
——如果用cin>>line的方式输入string类型的line,会导致不能判断为空的输入,所以采用getline。在while循环之前还需要添加getchar(),吸收换行。否则90分;
——c++中单双引号的区别:
""是字符串,C风格字符串后面有一个'\0';''是一个字符,一共就一字节。
单引号表示是字符变量值,字母的本质也是数字。双引号表示字符串变量值,给字符串赋值时系统会自动给字符串变量后面加上一个\0来表示字符串结尾。
string::rfind(string, pos) 是从头开始找,到pos为止,最后一次出现string的位置。
权限查询
map的灵活运行,给出集合A和集合B,集合B和集合C的关系,计算集合C和集合A的关系,因为会出现重叠的元素,所以要遍历所有的A集合中的元素,取最大。
用到知识点:
map<string, map<string, int>>
map::count() 返回0,1
map<string, int>::iterator it--it->first, it->second
string::substr(start, len)--s.substr(0,3)
string::find(string)返回找到的pos,-1
#include <iostream> #include <vector> #include <string> #include <map> using namespace std; map<string,int> cate; map<string,map<string, int> > rol; map<string,map<string,int> > usr; void find(string u, string role, int level){ if(usr.count(u)>0&&usr[u].count(role)>0) { int lev = usr[u][role]; if(level==-1) { if(lev>-1)cout<<lev<<endl; else cout<<"true"<<endl; } else { if(lev<level)cout<< "false"<<endl; else cout<<"true"<<endl; } } else cout<<"false"<<endl; } int to_int(string s,int pos) { int ans=0; for(int i=pos;i<s.size();i++) { ans = ans*10 + s[i]-'0'; } return ans; } int main() { int p,r,u,q; cin>>p; string s; int level; size_t pos; for(int i=0;i<p;i++) { cin >> s; if ((pos = s.find(":")) != -1) { level = to_int(s,pos+1); s = s.substr(0,pos); cate[s]=max(cate[s],level); } else cate[s]=-1; } cin>>r; int cnt; string role; for(int i=0;i<r;i++) { cin>>role>>cnt; for(int j=0;j<cnt;j++) { cin>>s; if ((pos = s.find(":")) != -1) { level = to_int(s,pos+1); s = s.substr(0,pos); rol[role][s]=max(rol[role][s],level); } else rol[role][s]=-1; } } cin>>u; for(int i =0;i<u;i++) // 直接和cate通过role关联 { string name; cin>>name>>cnt; for(int j=0;j<cnt;j++) { cin>>s; map<string,int>::iterator it = rol[s].begin(); while(it!=rol[s].end()) { if(usr[name].count(it->first)>0)// 这里必须要区分是否存在,否则默认的0会覆盖-1 { usr[name][it->first]=max(usr[name][it->first],it->second); } else usr[name][it->first] = it->second; it++; } } } cin>>q; while(q--) { string x; cin>>s>>x; size_t pos=x.find(":"); if(pos==string::npos) find(s,x,-1); else find(s,x.substr(0,pos),x[pos+1]-'0');//string_to_int的另一种写法 } return 0; }
JSON查询
解法转自meelo
json是一个递归数据结构,因此可以使用函数的递归调用来进行解析。
每一类数据对应一个解析函数,代码中parseString实现解析字符串的功能,parseObject实现解析对象的功能。
解析函数的主体功能就是依次遍历每一个字符,根据字符判断是否是字符串的开始、对象的开始……并进行相应的处理。
json是一个键值对的结构,因此可以用map存储。map的键可以用查询的格式,用小数点.来分隔多层的键。
1 #include <iostream> 2 #include <cassert> 3 #include <map> 4 using namespace std; 5 6 string parseString(string &str, int &i) { 7 string tmp; 8 if(str[i] == '"') i++; 9 else assert(0); 10 11 while(i < str.size()) { 12 if(str[i] == '\\') { 13 i++; 14 tmp += str[i]; 15 i++; 16 } 17 else if(str[i] == '"') { 18 break; 19 } 20 else { 21 tmp += str[i]; 22 i++; 23 } 24 } 25 26 if(str[i] == '"') i++; 27 else assert(0); 28 29 return tmp; 30 } 31 32 void parseObject(string &str, string prefix, map<string, string> &dict, int &i) { 33 if(str[i] == '{') i++; 34 else assert(0); 35 36 string key, value; 37 bool strType = false; // 标志 false:key, true:value 38 while(i < str.size()) { 39 if(str[i] == '"') { 40 string tmp = parseString(str, i); 41 if(strType) { // value 42 value = tmp; 43 dict[key] = value; 44 } 45 else { // key 46 key = prefix + (prefix==""?"":".") + tmp; 47 } 48 } 49 else if(str[i] == ':') { 50 strType = true; 51 i++; 52 } 53 else if(str[i] == ',') { 54 strType = false; 55 i++; 56 } 57 else if(str[i] == '{') { 58 dict[key] = ""; 59 parseObject(str, key, dict, i); 60 } 61 else if(str[i] == '}') { 62 i++; 63 break; 64 } 65 else { 66 i++; 67 } 68 } 69 } 70 71 int main() { 72 int N, M; 73 cin >> N >> M; 74 string json; 75 if(cin.peek()=='\n') cin.ignore(); 76 for(int n=0; n<N; n++) { // 输入用getline(保留空格,空)连成一个string 77 string tmp; 78 getline(cin, tmp); 79 json += tmp; 80 } 81 map<string, string> dict; // 存储所有候选键值对 82 int i = 0; 83 parseObject(json, "", dict, i); // json是一个递归结构,递归解析 84 string query; 85 for(int m=0; m<M; m++) { 86 getline(cin, query); 87 if(dict.find(query) == dict.end()) { 88 cout << "NOTEXIST\n"; 89 } 90 else { 91 if(dict[query] == "") { 92 cout << "OBJECT\n"; 93 } 94 else { 95 cout << "STRING " << dict[query] << "\n"; 96 } 97 } 98 } 99 return 0; 100 }
MarkDown
解法转自:meelo 逻辑异常清晰,这老哥写的代码会说话2333
1 #include <iostream> 2 #include <vector> 3 #include <string> 4 #include <cassert> 5 6 using namespace std; 7 8 string to_string(int i) { 9 char buffer[10]; 10 return string(itoa(i, buffer, 10)); 11 } 12 13 string parseEmphasize(string text) { 14 string result; 15 result += "<em>"; 16 result += text; 17 result += "</em>"; 18 return result; 19 } 20 21 string parseLink(string text, string link) { 22 string result; 23 result += "<a href=\""; 24 result += link; 25 result += "\">"; 26 result += text; 27 result += "</a>"; 28 return result; 29 } 30 31 string parseLine(string line) { // 行内解析,包含递归调用 32 string result; 33 int i = 0; 34 while(i<line.size()) { 35 if(line[i]=='[') { 36 string text, link; 37 int j = i+1; 38 while(line[j] != ']') j++; 39 text = line.substr(i+1, j-i-1); 40 i = j+1; 41 assert(line[i]=='('); 42 while(line[j]!=')') j++; 43 link = line.substr(i+1, j-i-1); 44 45 text = parseLine(text); 46 link = parseLine(link); 47 result += parseLink(text, link); 48 i = j+1; 49 } 50 else if(line[i]=='_') { 51 string text; 52 int j = i+1; 53 while(line[j]!='_') j++; 54 text = line.substr(i+1, j-i-1); 55 56 text = parseLine(text); 57 result += parseEmphasize(text); 58 i = j + 1; 59 } 60 else { 61 result += line[i]; 62 i++; 63 } 64 } 65 return result; 66 } 67 68 string parseHeading(vector<string> &contents) { 69 assert(contents.size()==1); 70 int level = 1; 71 int i = 0; 72 string heading = parseLine(contents[0]); 73 74 while(heading[i] == '#') i++; 75 level = i; 76 while(heading[i] == ' ') i++; 77 78 string result; 79 result += "<h"; 80 result += to_string(level); 81 result += '>'; 82 result += heading.substr(i,-1); 83 result += "</h"; 84 result += to_string(level); 85 result += ">\n"; 86 return result; 87 } 88 89 string parseParagraph(vector<string> &contents) { 90 string result; 91 result += "<p>"; 92 for(int i=0; i<contents.size(); i++) { 93 result += parseLine(contents[i]); 94 if(contents.size() != 0 && i != contents.size()-1) result += '\n'; 95 } 96 result += "</p>\n"; 97 return result; 98 } 99 100 string parseUnorderedList(vector<string> &contents) { 101 string result; 102 result += "<ul>\n"; 103 int j; 104 for(int i=0; i<contents.size(); i++) { 105 result += "<li>"; 106 j = 1; 107 while(contents[i][j] == ' ') j++; 108 result += parseLine(contents[i].substr(j,-1)); 109 result += "</li>\n"; 110 } 111 result += "</ul>\n"; 112 return result; 113 } 114 115 int main() { 116 string line; 117 vector<string> contents; 118 int blockType; // 0:empty, 1:paragraph, 2:heading, 3:unordered list 119 string result; 120 while(getline(cin, line) || contents.size()>0) { // getline空行的时候注意 121 if(line.empty()) { // 结束的标志 122 if(blockType != 0) { 123 switch(blockType) { 124 case 1: result += parseParagraph(contents); break; 125 case 2: result += parseHeading(contents); break; 126 case 3: result += parseUnorderedList(contents); break; 127 } 128 contents.resize(0); 129 blockType = 0; 130 } 131 } 132 else if(line[0] == '#') { 133 contents.push_back(line); 134 blockType = 2; 135 } 136 else if(line[0] == '*') { 137 contents.push_back(line); 138 blockType = 3; 139 } 140 else { 141 contents.push_back(line); 142 blockType = 1; 143 } 144 line = ""; 145 } 146 cout << result; 147 }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号