Lucene
一、分词器的核心类
1.Analyzer分词器
SimpleAnalyzer、StopAnalyzer、WhitespaceAnalyser、StandardAnalyser
2.TokenStream
分词器做好处理之后得到的一个流,这个流中存储了分词的各种信息,可以通过TokenStream有效的获取到分词单元。
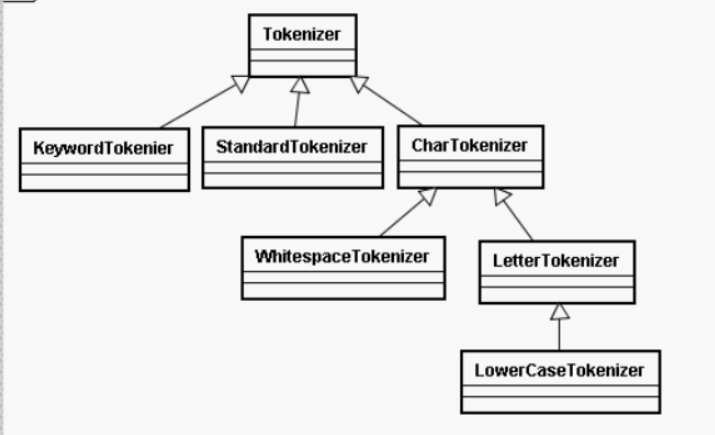
3.Tokenizer
主要负责接收Reader字符流,将Reader进行分词操作,有如下一些实现类。
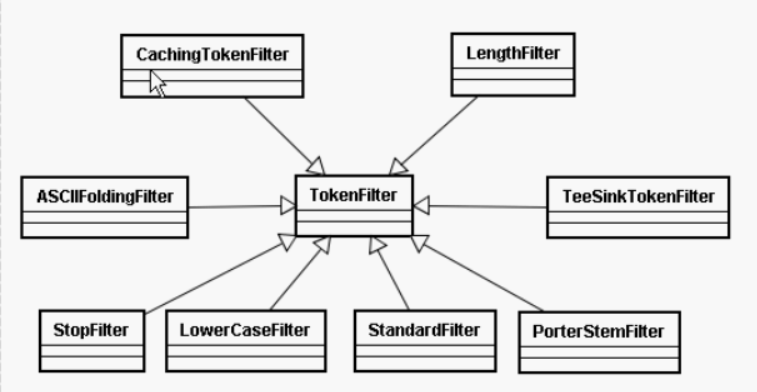
4.TokenFilter
将分词的语汇单元,进行各种各样的过滤
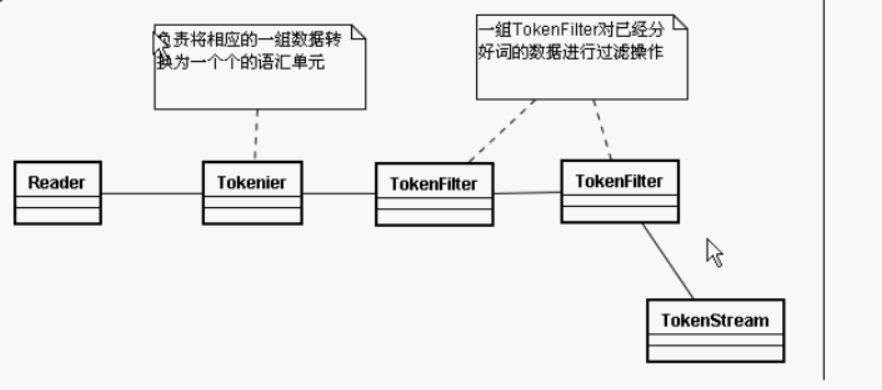
在这个流中,存储的数据有这些东西:
二、Attribute类
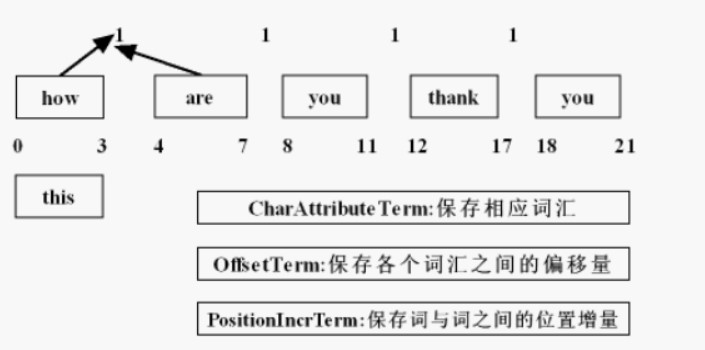
//前三个很重要!
PositionIncrementAttribute pia = stream.addAttribute(PositionIncrementAttribute.class);
//位置增量的属性,存储语汇单元之间的距离(可做同义词)
OffsetAttribute oa = stream.addAttribute(OffsetAttribute.class);
//每个语汇单元的位置偏移量
CharTermAttribute cta = stream.addAttribute(CharTermAttribute.class);
//存储每一个分词的单元信息
TypeAttribute ta = stream.addAttribute(TypeAttribute.class);
//分词器的类型信息三、自定义分词器

 浙公网安备 33010602011771号
浙公网安备 33010602011771号