
数据采集与融合技术实践第一次作业
152301219李志阳
任务一-大学排名
代码
点击查看代码
import urllib.request
from bs4 import BeautifulSoup
url = "http://www.shanghairanking.cn/rankings/bcur/2020"
try:
resp = urllib.request.urlopen(url)
html = resp.read().decode("UTF-8")
soup = BeautifulSoup(html, "html.parser")
# 查找class为"rk-table"的<table>标签(排名数据所在的表格)
table = soup.find("table", class_="rk-table")
# 如果未找到表格,打印提示并退出程序
if not table:
print("未找到排名表格,请检查网页结构!")
exit()
# 4. 提取表格数据
# 查找表格中的<tbody>标签(表格主体内容,包含所有行数据)
tbody = table.find("tbody")
# 获取<tbody>中所有的<tr>标签(每一行数据)
rows = tbody.find_all("tr")
print(f"{'排名':<7}{'学校名称':<14}{'省市':<10}{'学校类型':<10}{'总分'}")
# 6. 遍历每一行,提取具体数据
for row in rows:
# 获取当前行中所有的<td>标签(每一列数据)
tds = row.find_all("td")
# 确保当前行至少有5列数据(避免结构异常的行导致报错)
if len(tds) >= 5:
# 提取排名(第1列,索引0),strip()去除前后空白
rank = tds[0].text.strip()
# 提取学校中文名:第2列(索引1)中class为"name-cn"的<span>标签文本
name_span = tds[1].find("span", class_="name-cn")
name = name_span.text.strip() if name_span else "未知名称" # 容错处理
# 提取省市(第3列,索引2)
province = tds[2].text.strip()
# 提取学校类型(第4列,索引3)
school_type = tds[3].text.strip()
# 提取总分(第5列,索引4)
score = tds[4].text.strip()
# 格式化打印一行数据,与表头对齐
print(f"{rank:<6}\t{name:10}\t{province:<8}\t{school_type:<10}\t{score}")
except Exception as e:
print(f"爬取失败:{e}")
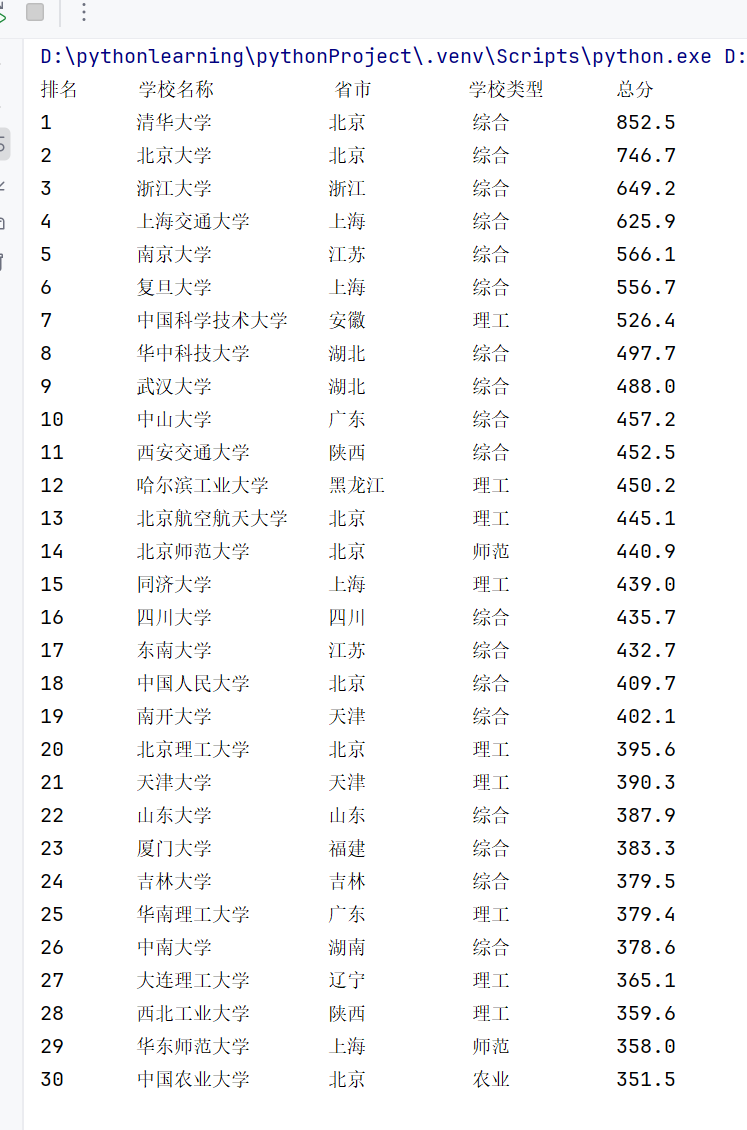
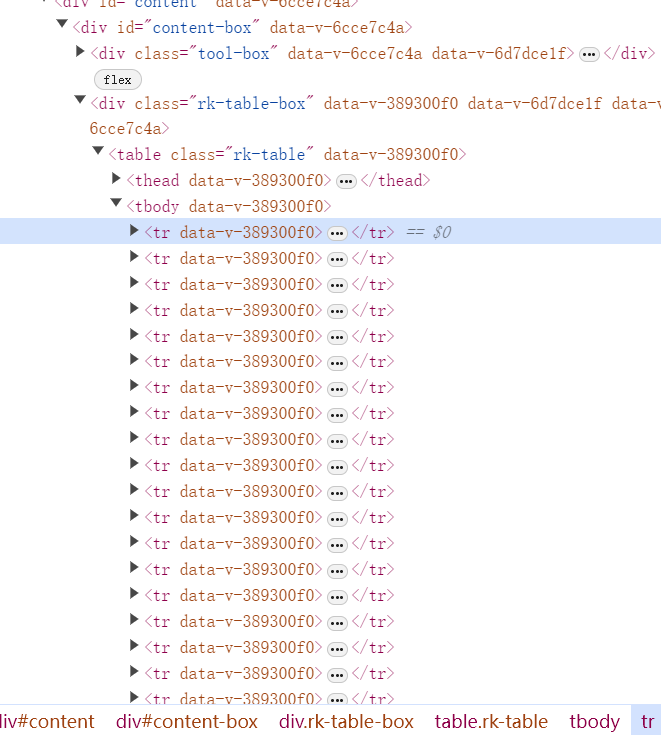
主要的思路就是观察网页的结构来对网页的信息进行提取,在网页中利用F12打开之后观察到网页的结构,先定位到class为"rk-table"的table标签存储了每一条数据,每一所大学的数据都存在tbody中每一行数据表示一所大学的基本信息,所以先用request解析网页,后采用BeautifulSoup中的库定位并提取信息,但用于这个网站的翻页采用了动态翻页,而不是简单的体现在uyl上,需要在f12中观察点进下一页后网页发送了什么请求,后发现网页采用JavaScript动态加载内容,后续通过网上查找得知可以用selenium动态模拟翻页来实现页码查询,我这里只爬取了第一页静态网页。
心得体会
编写这段爬取软科大学排名数据的代码,让我对网络数据爬取和 HTML 解析有了更深入的实践认知,拿到目标网页后,我并没有直接写代码,而是先通过浏览器开发者工具(F12)查看排名表格的 HTML 结构:发现数据存放在class="rk-table"的表格中,每行数据是tr标签,列是td标签,学校名称藏在里。这个过程就像 “拆解机器”—— 先搞清楚数据的 “存放位置”,再用BeautifulSoup的find()、find_all()精准定位。这让我明白:解析 HTML 的核心是 “先分析结构,再写代码”,逆向推导比盲目尝试高效得多。
任务二-爬取商城信息
代码
点击查看代码
import urllib.request
import re
url = "https://search.dangdang.com/?key=%CA%E9%B0%FC&act=input" # %CA%E9%B0%FC是“书包”的GBK编码
# 请求头:模拟浏览器信息,避免被反爬
HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36",
"Cookie": "ddscreen=2; ...", # 携带Cookie模拟登录状态,提升请求成功率
"Referer": "https://www.dangdang.com/", # Referer字段说明请求来源,降低被拦截概率
"Host": "search.dangdang.com" # 指定主机名,确保请求正确指向目标服务器
}
try:
request = urllib.request.Request(url=url, headers=HEADERS)
resp = urllib.request.urlopen(request)
# 3. 解码响应内容(当当网使用GBK编码,需对应解码)
html = resp.read().decode("GBK")
# 4. 正则匹配商品列表容器(id="component_59"的ul标签,存放所有商品li)
# re.DOTALL使.匹配包括换行符在内的所有字符,避免因HTML换行导致匹配失败
list_pattern = r'<ul[^>]*id="component_59"[^>]*>(.*?)</ul>'
list_match = re.search(list_pattern, html, re.DOTALL)
if list_match:
# 提取ul标签内的HTML内容(所有商品li所在区域)
list_html = list_match.group(1)
# 5. 从列表容器中匹配所有商品项(class含"line"的li标签,每个li对应一个商品)
li_pattern = r'<li[^>]*class="line[^"]*"[^>]*>(.*?)</li>'
lis = re.findall(li_pattern, list_html, re.DOTALL) # 返回所有匹配的li列表
# 打印表头(格式化对齐)
print(f"{'序号':<4}{'价格':<12}{'商品名'}")
# 6. 遍历每个商品li,提取价格和商品名
for idx, li_html in enumerate(lis, start=1):
# 匹配价格(class="price_n"的span标签,包含商品单价)
price_pattern = r'<span[^>]*class="price_n"[^>]*>(.*?)</span>'
price_match = re.search(price_pattern, li_html)
# 提取价格文本,替换HTML中的¥为¥符号
price = price_match.group(1).strip().replace("¥", "¥")
# 匹配商品名(a标签的title属性,直接包含商品完整名称)
# [^"]*表示匹配非引号的任意字符,确保准确提取title内容
name_pattern = r'<p[^>]*class="name"[^>]*>\s*<a[^>]*title="([^"]*)".*?</a>\s*</p>'
name_match1 = re.search(name_pattern, li_html)
# 提取名称并去除多余空格(\s+匹配多个空白,替换为单个空格)
name = name_match1.group(1).strip()
name = re.sub(r'\s+', ' ', name).strip()
# 格式化打印商品信息(序号、价格、商品名对齐)
print(f"{idx:<4}{price:<12}{name}")
else:
print("未找到商品列表") # 未匹配到商品容器时提示
# 捕获所有异常(网络错误、正则匹配失败等)
except Exception as e:
print(f"爬取失败:{e}")
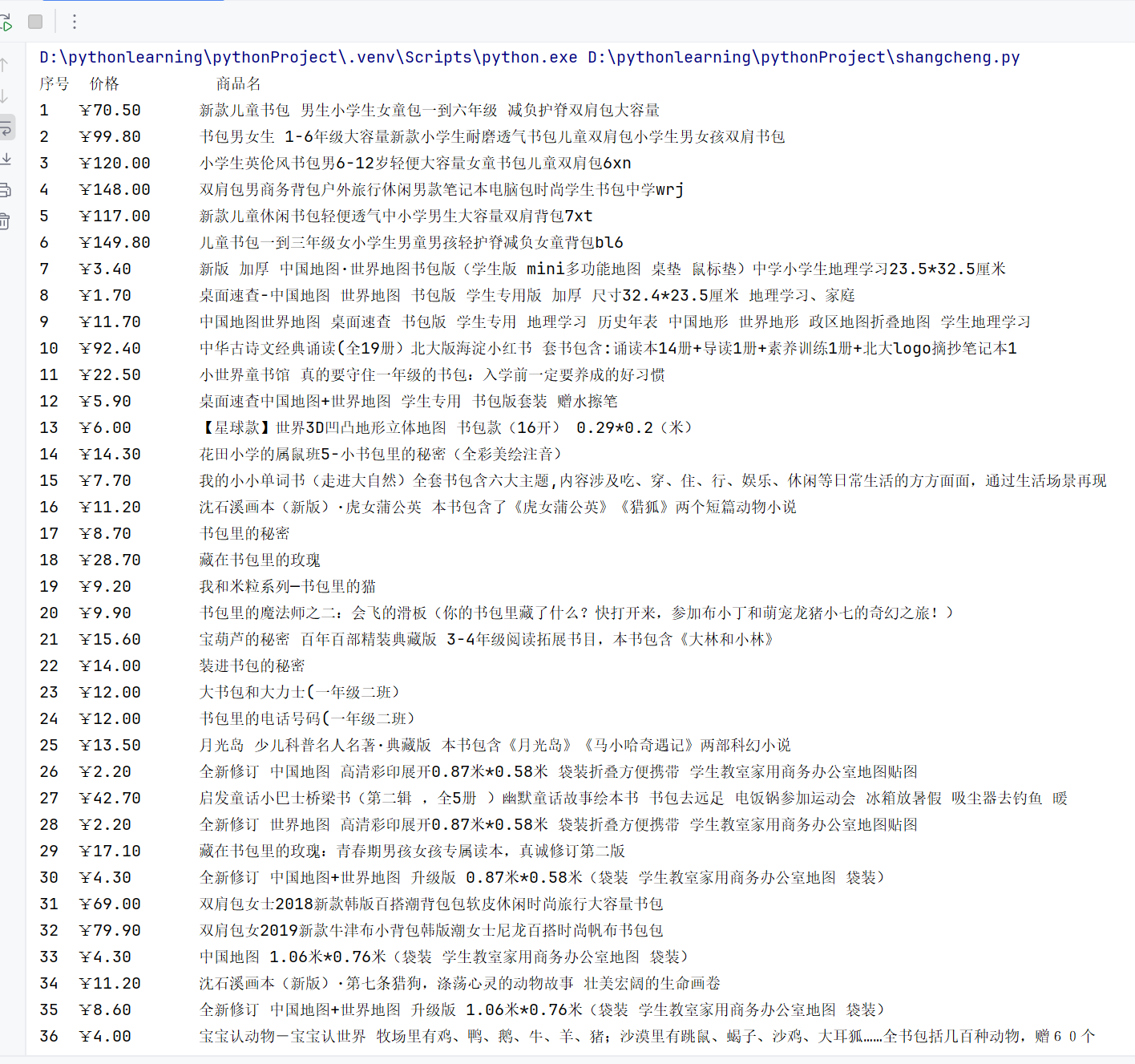

心得体会:
写当当网书包搜索页爬虫代码的过程,让我对爬虫细节有了更深体会。最初没加请求头时,直接返回 403 禁止访问,后来补充User-Agent模拟浏览器、Referer说明请求来源、Cookie模拟登录状态,才成功获取页面,这让我明白 “伪装成正常用户” 是应对反爬的关键。
解析环节,用正则匹配时,我优先选id="component_59"这类唯一标识定位商品列表,避免因class变动失效;提取商品名时直接抓a标签的title属性,避开嵌套干扰。但编码问题曾让我踩坑,一开始用UTF-8解码导致乱码,后来确认网页是GBK编码才解决。
数据清洗也不可少,价格里的¥要换成¥,商品名的多余空格得用正则替换,否则结果杂乱难用。整个过程让我发现,爬虫每一步都藏着细节,从请求头设置到编码匹配,再到数据处理,任何环节疏忽都可能导致失败,只有耐心抠细节,才能做出稳定可用的爬虫。
至于翻页,也是采用动态翻页技术,所以我只获取了一页数据
任务三-爬取福大影像
点击查看代码
import urllib.request
import re
from urllib.parse import urljoin
BASE_URL = "https://news.fzu.edu.cn/yxfd"
FIRST_PAGE_URL = "https://news.fzu.edu.cn/yxfd.htm"
Savepath = "C:/Users/lzy/Desktop/数据采集/实践一"
MAX_PAGE = 6 # 最大爬取页数
global_img_idx = 1 # 全局图片序号
def get_webpage_html(url):
try:
req = urllib.request.Request(url)
with urllib.request.urlopen(req) as resp:
return resp.read().decode("UTF-8")
except Exception as e:
print(f"获取网页 {url} 失败:{e}")
return None
def crawl_page_images(html, page_num):
global global_img_idx
if not html:
return
# 定位到有用的图片,避免爬取无用图片
div_pattern = r'<div[^>]*class="img slow"[^>]*>(.*?)</div>'
all_divs = re.findall(div_pattern, html, re.DOTALL)
if not all_divs:
print(f"第{page_num}页:未找到div class='img slow'图片")
return
print(f"第{page_num}页:找到 {len(all_divs)} 张图片")
for div_idx, div_html in enumerate(all_divs, 1):
img_match = re.search(r'<img[^>]*src=["\']?([^"\' >]+)', div_html, re.DOTALL)
img_url = urljoin(FIRST_PAGE_URL, img_match.group(1).strip())
try:
filename = f"img_p{page_num}_d{div_idx}_{global_img_idx}_{img_url.split('/')[-1]}"
filename = re.sub(r'[\\/:*?"<>|]', '_', filename) # 清理非法字符
urllib.request.urlretrieve(img_url, f"{Savepath}/{filename}")
print(f"下载成功:{filename}(链接:{img_url.split('/')[-1]})")
global_img_idx += 1
except Exception as e:
print(f"第{page_num}页 第{div_idx}个容器:下载失败 {e}")
def crawl_multi_pages():
print(f"开始爬取(共{MAX_PAGE}页),保存至:{Savepath}")
# 1. 爬第1页(原URL不变)
crawl_page_images(get_webpage_html(FIRST_PAGE_URL), 1)
reverse_page_params = [5, 4, 3, 2, 1] # 替换为你实际第2-6页对应的URL末尾数字
for idx, param in enumerate(reverse_page_params, start=2): # start=2:对应爬取第2-6页
if idx > MAX_PAGE:
break
current_url = f"{BASE_URL}/{param}.htm"
crawl_page_images(get_webpage_html(current_url), idx)
print(f"\n爬取结束,共下载 {global_img_idx - 1} 张图片")
if __name__ == "__main__":
crawl_multi_pages()
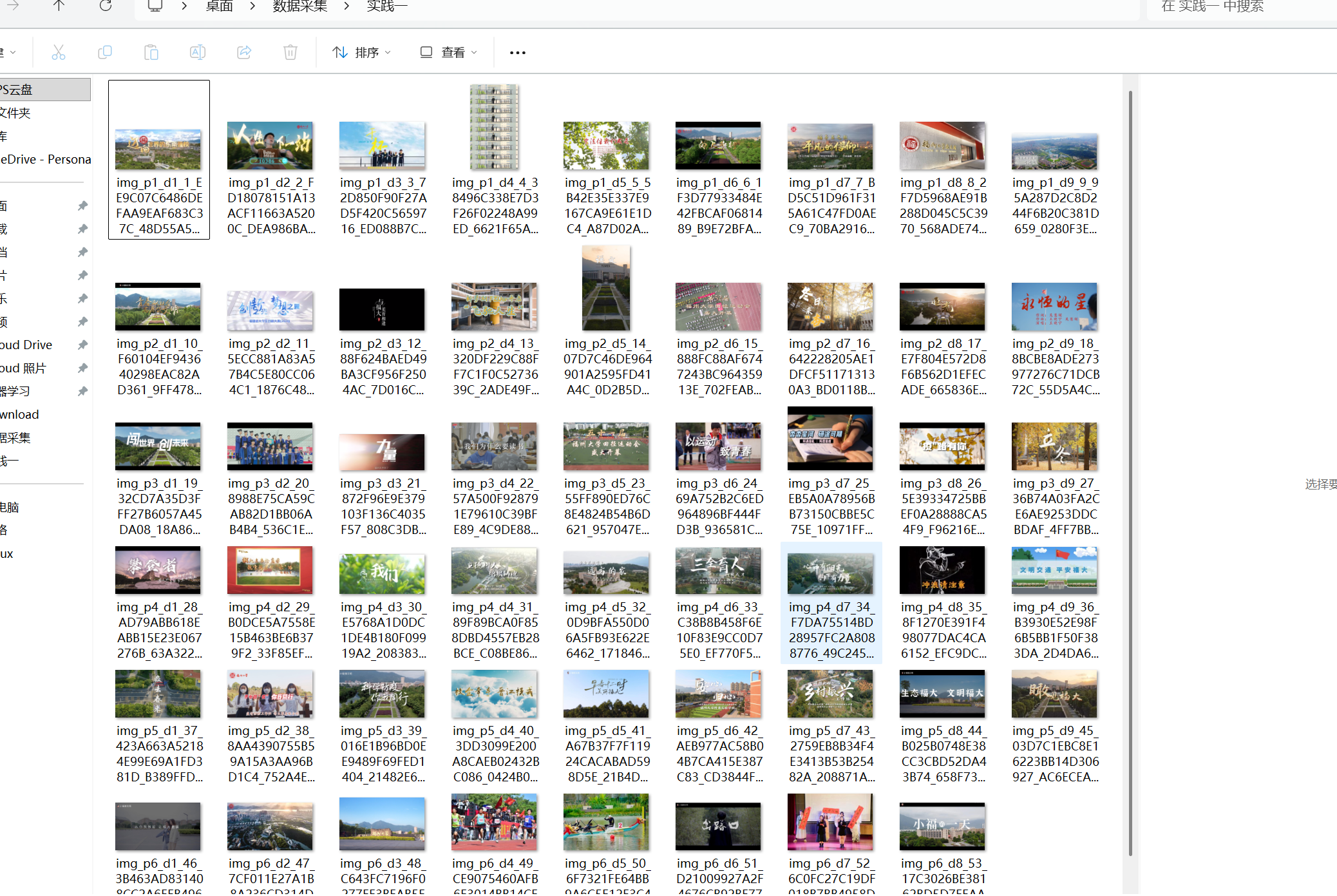
心得体会:
福大的翻页是在url上体现的,但是标签是倒序的这次修改代码适配倒序分页的过程,让我对爬虫中“页面结构适配”有了更深体会。最初按顺页逻辑爬取时,后几页始终无结果,直到发现分页是倒序(如第三页对应4.htm),才明白问题出在URL规则判断错误。
仅通过调整一个页码列表就解决了问题,这让我意识到:爬虫的核心不是代码复杂度,而是对目标网页结构的精准观察——哪怕一个小小的分页规则偏差,都会导致爬取失败。这次经历也提醒我,爬取前一定要用浏览器手动验证分页链接,尤其遇到非常规排序时,更要耐心梳理规律,再动手写代码。细节处的观察和灵活调整,往往是爬虫成功的关键。
gitee链接:https://gitee.com/li-zhiyang-dejavu/2025_crawl_project

 浙公网安备 33010602011771号
浙公网安备 33010602011771号