简单 Python 快乐之旅之:Python 基础语法之 Pandas 数据分析专题
- 1. Pandas 简介
- 2. Pandas Series 基础篇
- 3. Pandas DataFrame 基础篇
- 3.1. 如何创建或初始化一个 Pandas DataFrame?
- 3.2. 如何从字典创建 DataFrame?
- 3.3. 如何从一系列列表中创建 DataFrame?
- 3.4. 如何使用 Numpy 数组创建 Pandas DataFrame?
- 3.5. 如何由 CSV 加载 Pandas DataFrame?
- 3.6. 如何打印 Pandas DataFrame 的信息?
- 3.7. 获取索引
- 3.8. 怎样判断 Pandas DataFrame 对象是空的?
- 3.9. 如何拿到 Pandas DataFrame 的轴数
- 3.10. 访问单个数据
- 3.11. 如何获取 Pandas 中元素的个数?
- 3.12. 如何拿到 Pandas DataFrame 的形状?
- 3.13. 如何连接 Pandas 里的 DataFrame?
- 3.14. 如何进行 DataFrame 的追加?
- 3.15. 如何对 Pandas DataFrame 里的数据进行查询?
- 3.16. 如何重置 Pandas DataFrame 的索引?
- 3.17. 如何将 Pandas DataFrame 翻译成 HTML 表格?
- 3.18. 如何将 Pandas DataFrame 写到 Excel 表格?
- 3.19. 最大值 - max() 函数
- 3.20. 如何拿到 Pandas DataFrame 的平均值?
- 3.21. 如何将 DataFrame 的 NaN 填充以默认值?
- 3.22. 获取轴信息
- 3.23. 内连接
- 4. Pandas DataFrame 单元格操作篇
- 5. Pandas DataFrame 列操作篇
- 5.1. 怎样获取 Pandas DataFrame 的列名?
- 5.2. 如何修改 Pandas DataFrame 的列标签?
- 5.3. 怎样得到 Pandas 中每列的数据类型?
- 5.4. 如何重命名 Pandas DataFrame 里的列名?
- 5.5. 选择某一列
- 5.6. 如何从 DataFrame 获取数字类型的列?
- 5.7. 如何根据某列对 DataFrame 进行排序?
- 5.8. 如何给 DataFrame 添加列?
- 5.9. 怎样删除 Pandas DataFrame 的列?
- 5.10. 如何将 Pandas DataFrame 的某列设置为索引?
- 5.11. 如何删除 Pandas DataFrame 的列?
- 5.12. 如何改变 Pandas DataFrame 列的数据类型?
- 5.13. 如何修改 Pandas DataFrame 里列的次序?
- 5.14. 替换多个值
- 5.15. 根据条件替换列里边的值
- 6. Pandas DataFrame 行操作
- 7. Pandas 转换
- 总结
- 参考资料
1. Pandas 简介
pandas 库可以帮助你在 Python 中执行整个数据分析流程。
通过 Pandas,你能够高效、Python 能够出色地完成数据分析、清晰以及准备等工作,可以把它看做是 Python 版的 Excel。
pandas 的构建基于 numpy。因此在导入 pandas 时,先要把 numpy 引入进来。
import numpy as np
import pandas as pd
这就是 pandas 社区导入库并为其命名的常用方式。 我们还将在以后的 pandas 示例中使用相同的别名。
以下是 Python Pandas 主题列表,我们将在本系列教程中逐一学习。
2. Pandas Series 基础篇
2.1. Pandas Series 示例
Series 是一维带标记的数组结构,可以存储任意类型的数据,无论是整数、浮点数、字符串。你可以在单个 series 中混合存放这些数据。
接下来我们将通过示例来了解 Pandas Series。
2.1.1. Pandas Series 的创建
在面向对象编程语言里边,类和实例的关系为:类是模板,实例是根据这个模板创建的对象。Python 中,类是通过关键字 class 来定义的,类名通常首字母大写。非常类似于诸如 Java 之类的其他面向对象类编程语言。
接下来我们就使用 Pandas 的 Series 类来创建一个 Pandas Series。我们传给 Series() 一个列表,Pandas 将为这个对象创建一个默认的整数索引。以下示例中我们将使用整数来创建一个 Pandas Series。
import numpy as np
import pandas as pd
s = pd.Series([1, 3, 5, 12, 6, 8])
print(s)
执行和输出:
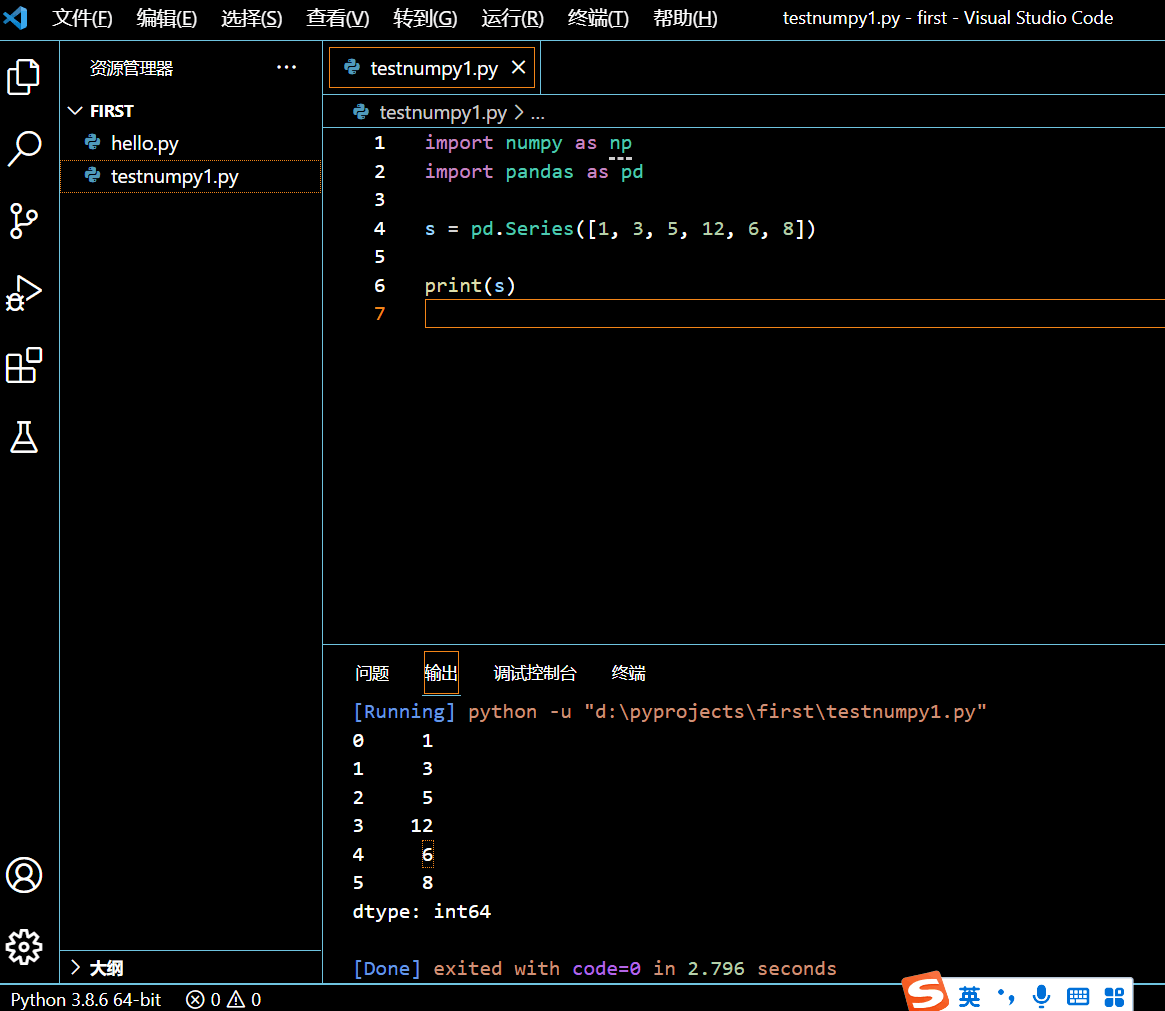
由输出可以看到该 Series 中元素的数据类型是为 int64,可见 Series 的数据类型是由内部存放的值的数据类型来决定的。
2.1.2. 装有 NaN 值的 Pandas Series
你还可以在 Pandas Series 中存放 numpy 的 NaN 值。在以下示例中,我们将创建一个装有 numpy.nan 值的 Series。
import numpy as np
import pandas as pd
s = pd.Series([1, 3, np.nan, 12, 6, 8])
print(s)
执行和输出:
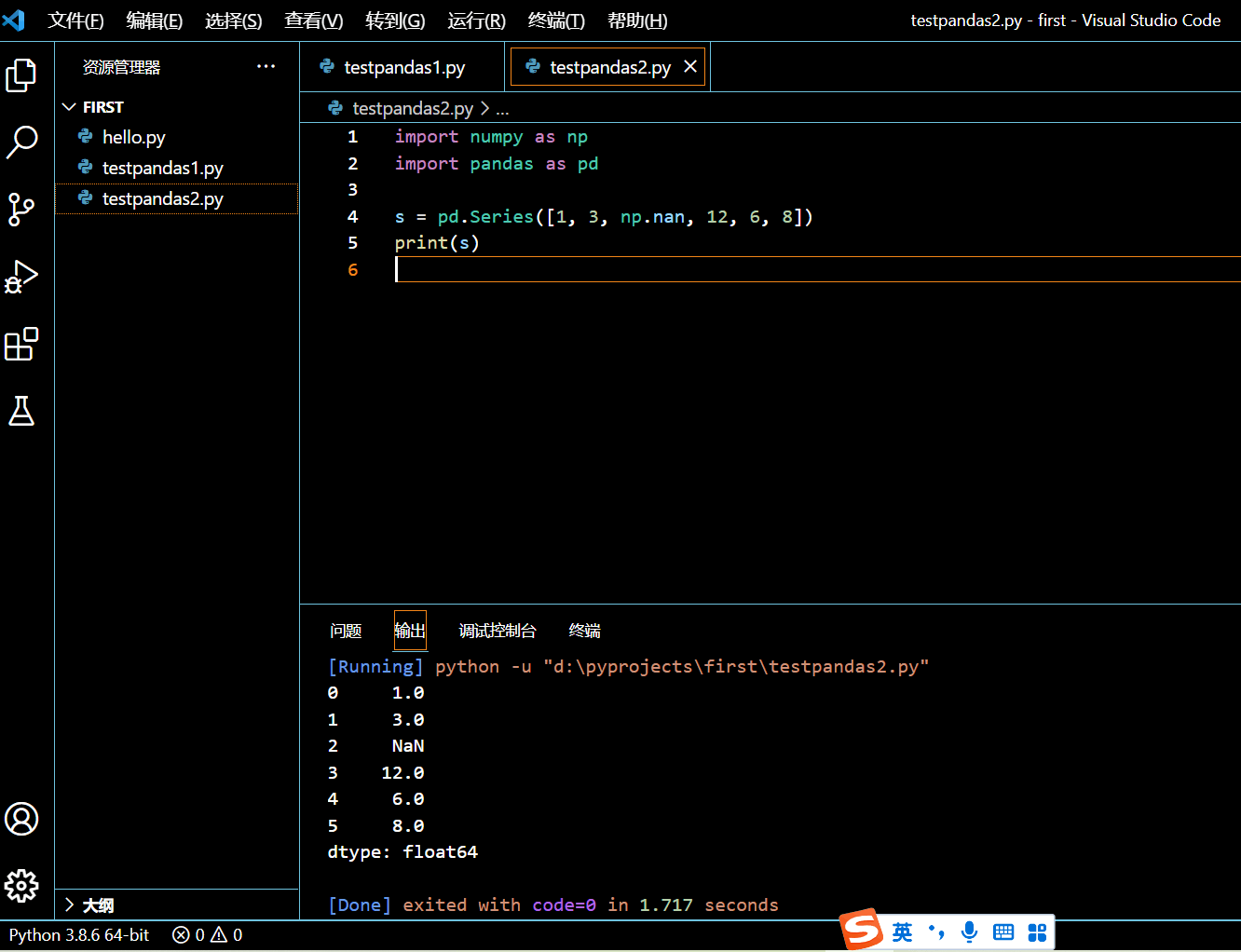
2.1.3. 装有字符串的 Pandas Series
当然你也可以把字符串装入 Series。在接下来的示例中,我们将创建一个含有一个字符串值的 Pandas Series。
import numpy as np
import pandas as pd
s = pd.Series(['Python', 3, np.nan, 12, 6, 8])
print(s)
执行和输出:
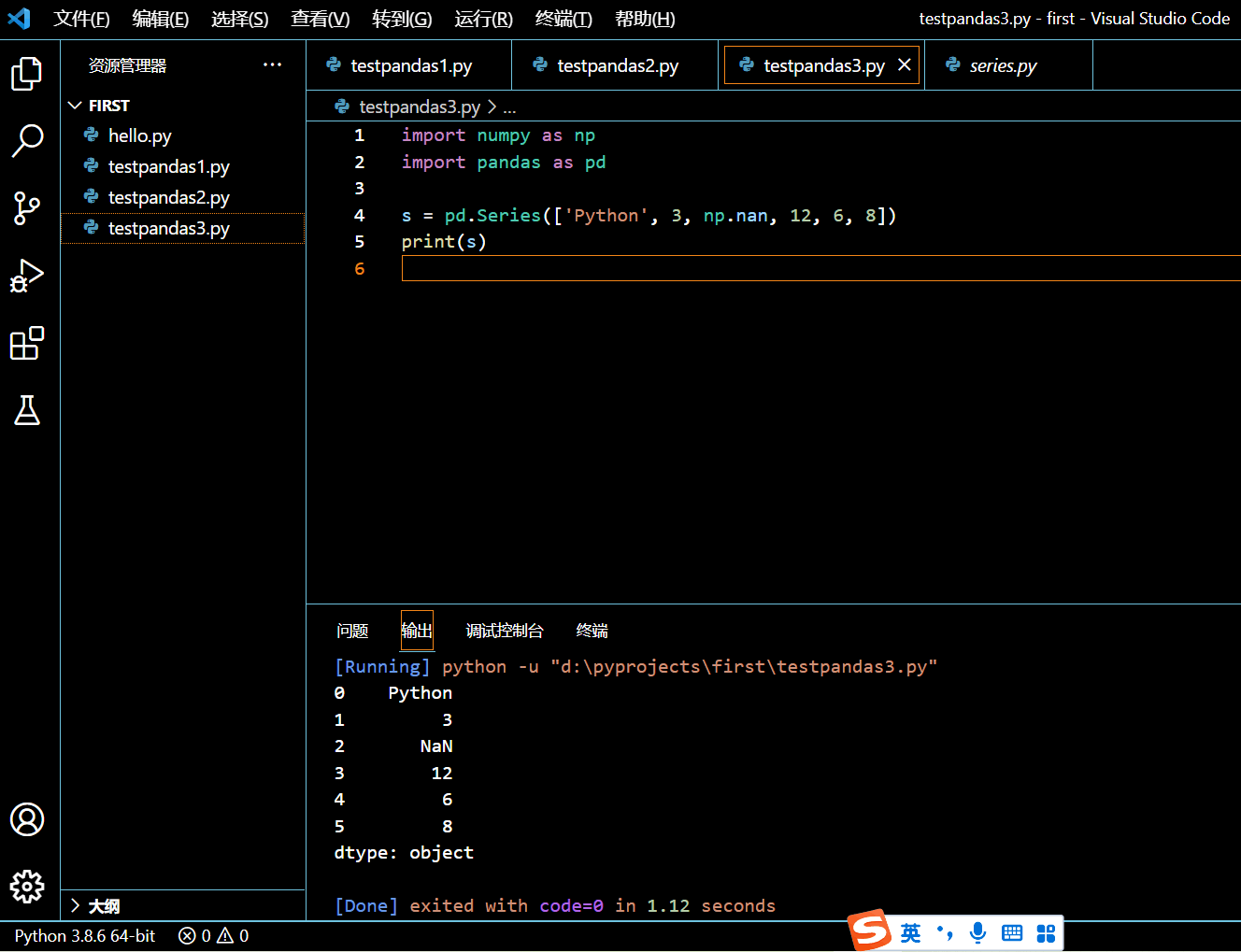
由于其中的元素属于不同的数据类型,诸如整数和字符串,所以这个 Pandas Series 里的所有的元素均被当做是对象。但当你单独访问元素时,则会返回相应的数据类型,比如 int64、str、float 等等。
2.1.4. 访问 Pandas Series 中的元素
你可以使用索引来访问一个 Pandas Series 中的元素。在接下来的示例中,我们将创建一个 Series,并使用索引来访问其中的一些元素。
import numpy as np
import pandas as pd
s = pd.Series(['python', 3, np.nan, 12, 6, 8])
print(s[0])
print(s[4])
执行和输出:
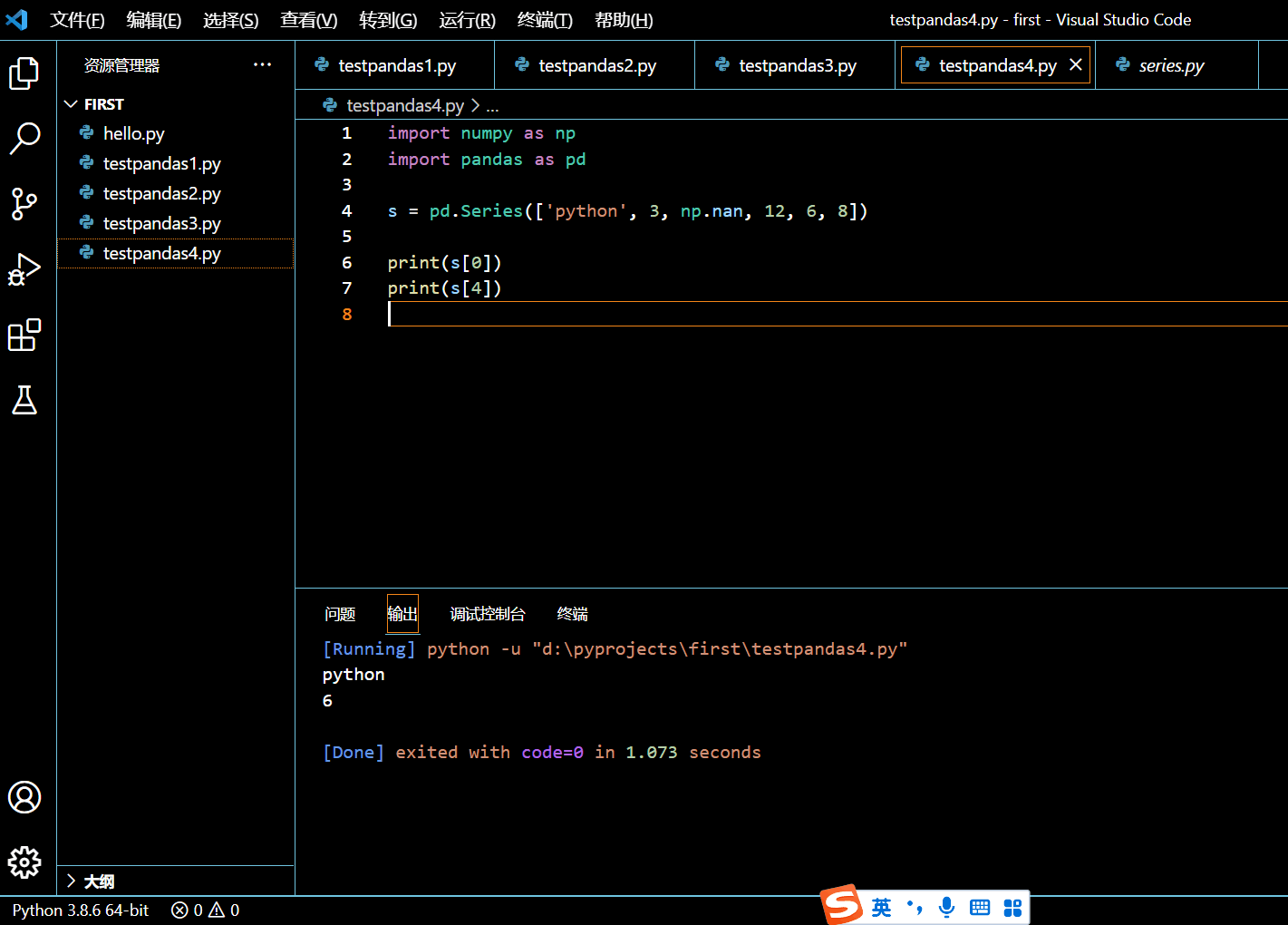
2.1.5. 小结
在本节课中,我们通过详尽的示例学习了怎样创建一个装有不同数据类型元素的 Pandas Series,并使用索引访问其中的某些元素。
3. Pandas DataFrame 基础篇
3.1. 如何创建或初始化一个 Pandas DataFrame?
在 Python 的 Pandas 模块里,DataFrame 是一个非常基础和重要的类型。我们可以使用 DataFrame() 构造函数来从不同的数据源或其他 Python 数据类型来创建一个 DataFrame。
本节我们将了解如何来创建或初始化 Pandas DataFrame。

3.1.1. DataFrame() 的语法
DataFrame() 类的语法如下所示:
DataFrame(data=None, index=None, columns=None, dtype=None, copy=False)
这 5 个参数都是可选的:
- data 可以是 ndarray、iterable、字典或其他 dataframe。
- index 可以是索引或一个数组。如果未提供,它默认是为范围索引,比如,从 0 到 行数 - 1。
- columns 用于标记列。
- dtype 用于指定或强制定义数据的数据类型。如若不指定,则从数据本身推断 dtype。
- copy 如果设置为 True,则从输入拷贝数据。注意,这个仅作用于 DataFrame 或两维 ndarray 输入。
3.1.2. 创建一个空的 DataFrame
不给 pandas.DataFrame() 类传递任何参数,即可创建一个空的 DataFrame。
在以下示例中,我们将创建一个空 DataFrame 并将其打印到控制台输出。
import pandas as pd
df = pd.DataFrame()
print(df)
执行和输出:
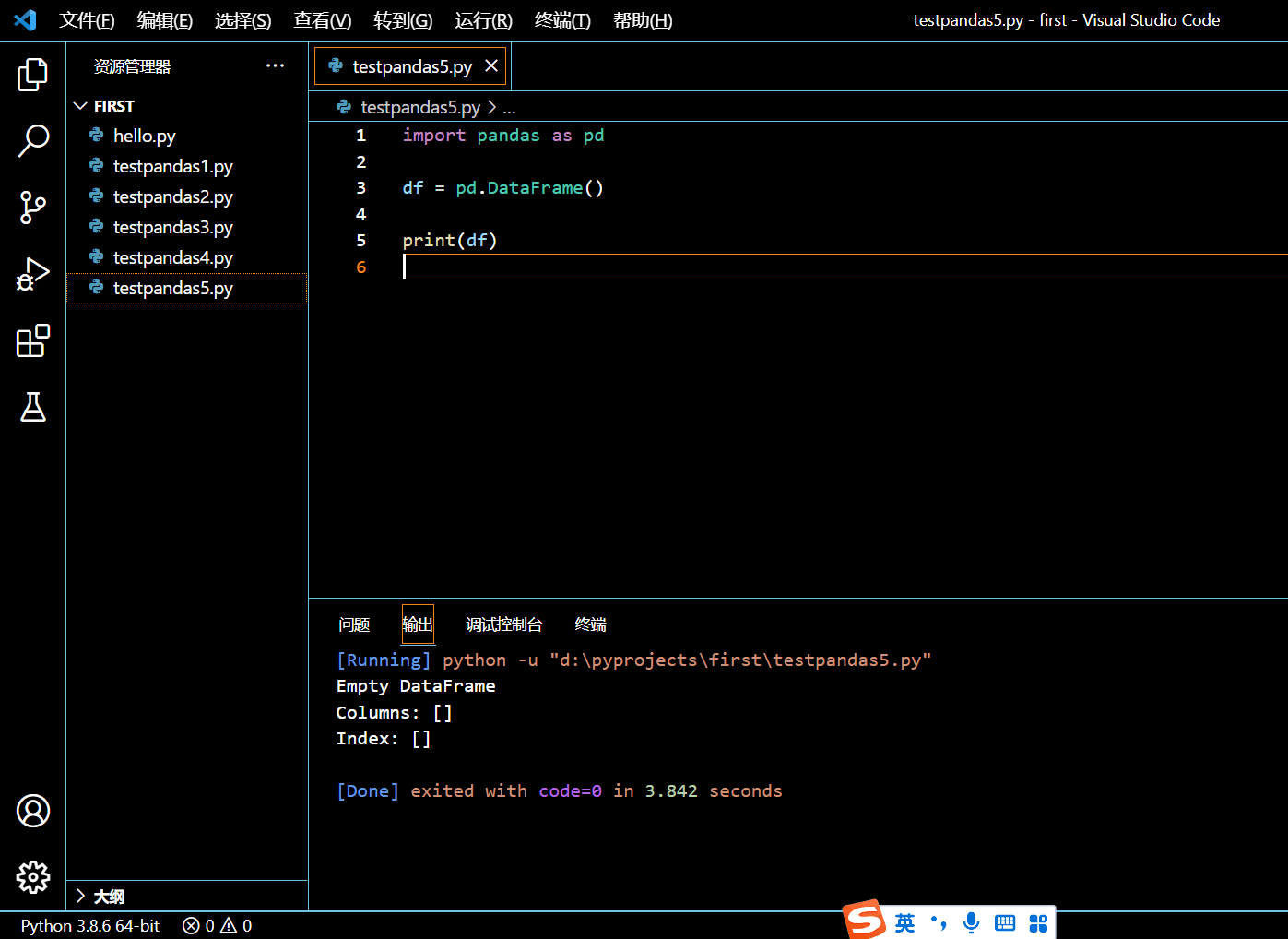
可见我们不提供任何参数的话,columns 数组和 index 数组都是空的。
3.1.3. 由一系列列表创建一个 DataFrame
要从一系列列表初始化一个 DataFrame,你可以将这一系列列表作为 data 参数传递给 pandas.DataFrame() 构造子。如以下示例所示:
import pandas as pd
# list of lists
data = [
['a1', 'b1', 'c1'],
['a2', 'b2', 'c2'],
['a3', 'b3', 'c3']
]
df = pd.DataFrame(data=data)
print(df)
执行和输出:
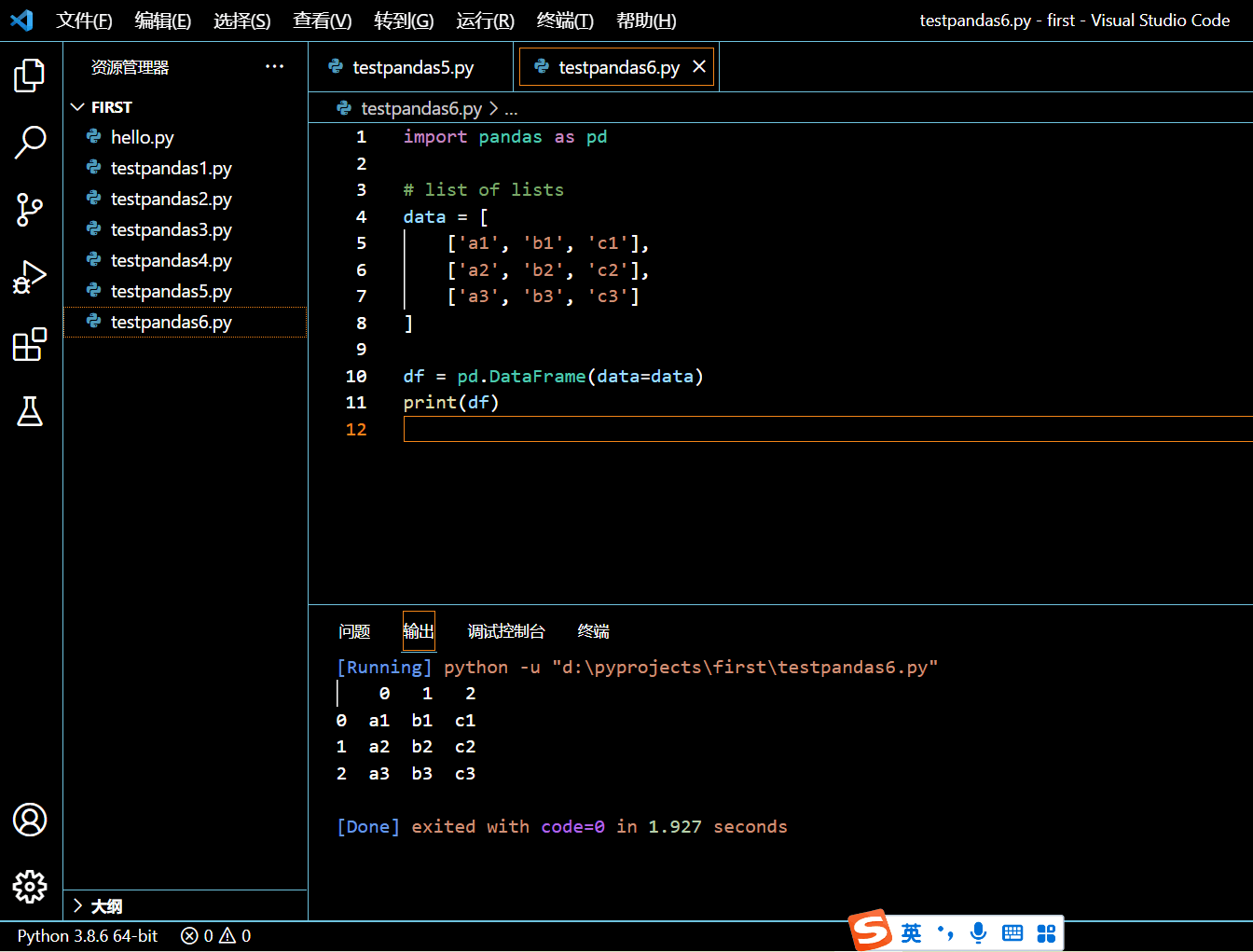
3.1.4. 用字典创建一个 DataFrame
也可以用字典来初始化一个 DataFrame,需将这个字典对象作为 data 参数传递给 pandas.DataFrame() 构造子。
在接下来的示例中,我们将使用一个字典来创建一个 DataFrame:
import pandas as pd
data = {
'aN' : ['a1', 'a2', 'a3'],
'bN' : ['b1', 'b2', 'b3'],
'cN' : ['c1', 'c2', 'c3']
}
df = pd.DataFrame(data=data)
print(df)
执行和输出:
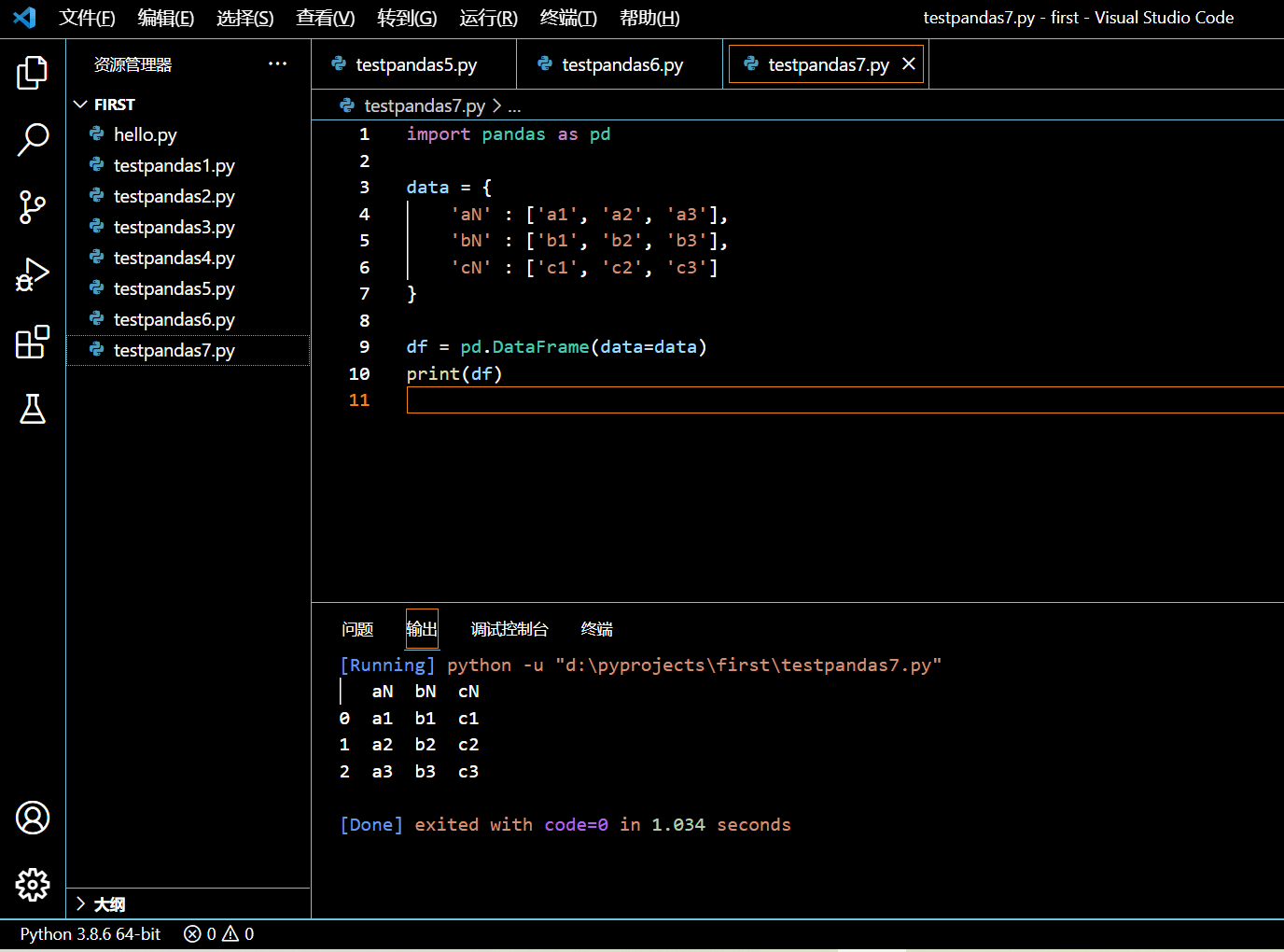
3.1.5. 小结
在本小节里,我们通过详细示例学到如何创建一个空的 DataFrame,以及通过不同的 Python 对象来创建一个 DataFrame。
3.2. 如何从字典创建 DataFrame?
你可以通过把字典对象作为 data 参数传递给 DataFrame() 构造子来创建一个 DataFrame。
在本小节中,我们将了解到如何通过 Python 字典来创建一个 Pandas DataFrame。
3.2.1. 语法
通过字典对象来创建 DataFrame 的语法如下:
mydataframe = DataFrame(dictionary)
字典中的每个元素会被转化为一个列,列名就是字典的 key,而字典的 value 则是列值。

3.2.2. 由字典来创建 DataFrame
在接下来的示例中我们将创建一个字典并将其作为 data 参数传给 DataFrame() 构造子。
import numpy as np
import pandas as pd
mydictionary = {
'name': ['Somu', 'Kiku', 'Amol', 'Lini'],
'physics': [68, 74, 77, 78],
'chemistry': [84, 56, 73, 69],
'algebra': [78, 88, 82, 87]
}
# create dataframe using dictionary
df_marks = pd.DataFrame(data=mydictionary)
print(df_marks)
执行和输出:
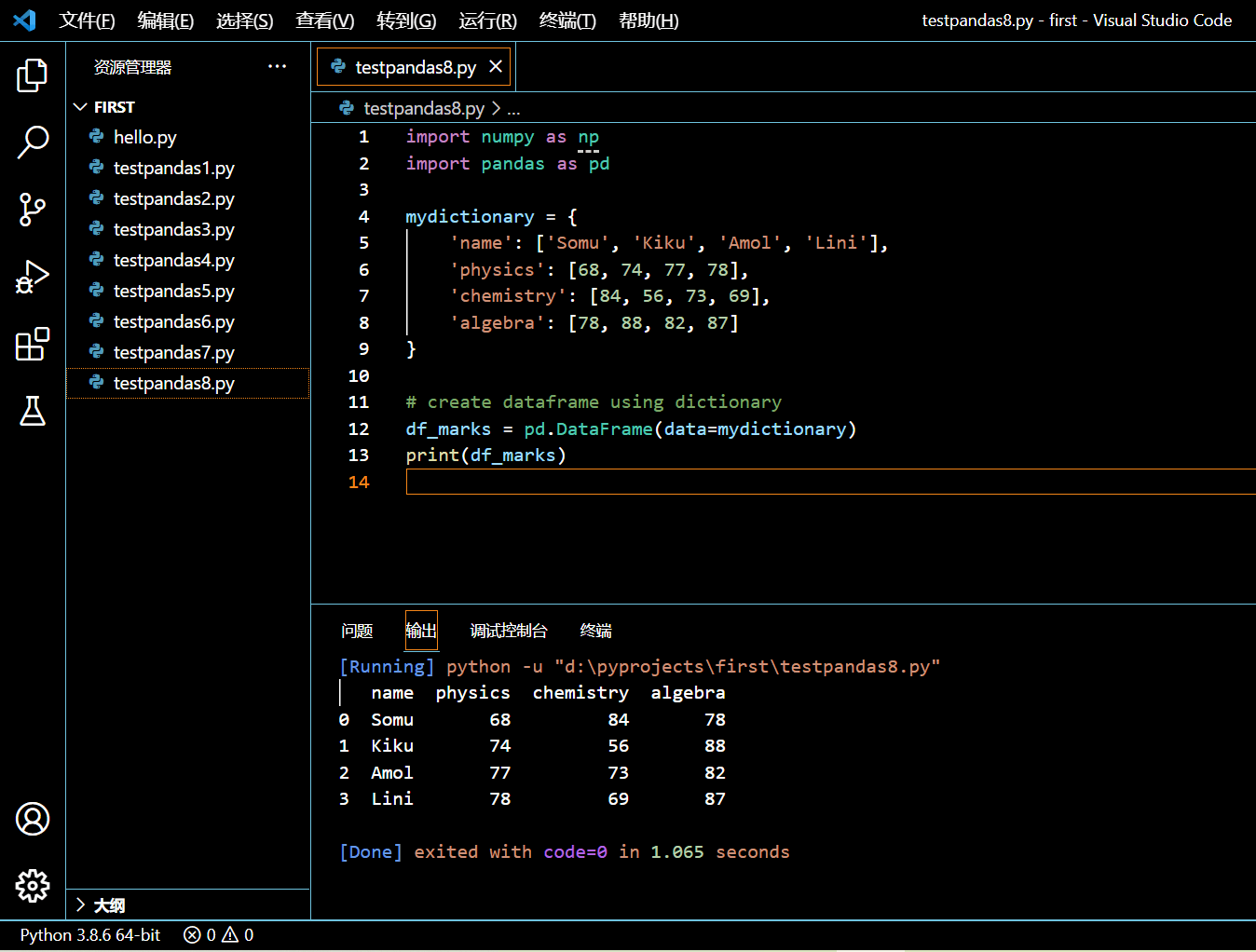
可见字典的 key 值(name、physics、chemistry、algebra) 被转换成了列名,而 value 值的数组则被转换成了列值。
3.2.3. 由 Python 字典来创建 DataFrame
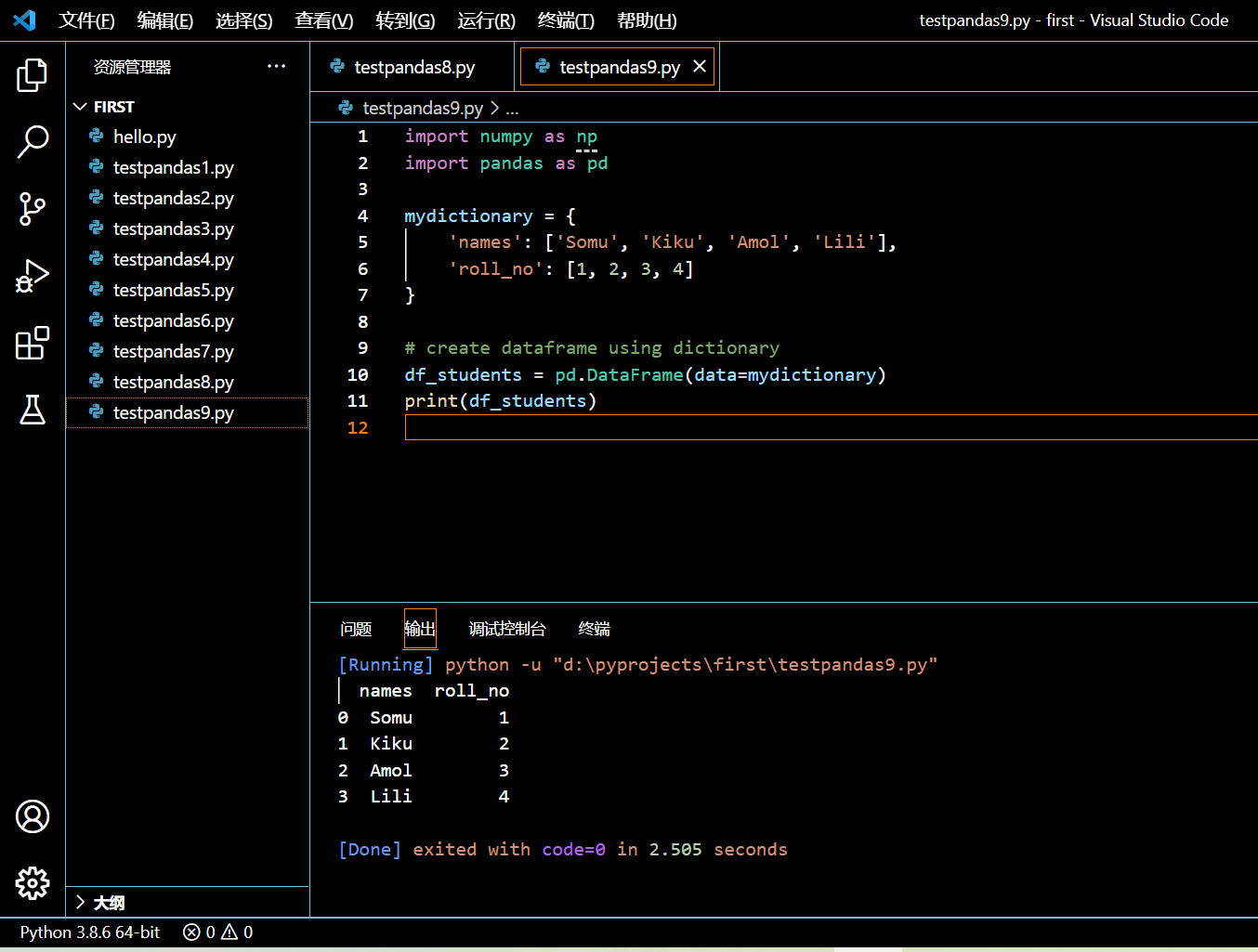
在本示例中我们将用一个字典来创建两列四行的一个 DataFrame。
import numpy as np
import pandas as pd
mydictionary = {
'names': ['Somu', 'Kiku', 'Amol', 'Lili'],
'roll_no': [1, 2, 3, 4]
}
# create dataframe using dictionary
df_students = pd.DataFrame(data=mydictionary)
print(df_students)
执行和输出:
3.2.4. 小结
在本小节中我们通过详细示例了解了如何使用 Python 字典来创建一个 Pandas DataFrame。
3.3. 如何从一系列列表中创建 DataFrame?
要从一系列列表中创建 Pandas DataFrame,你可以将该系列列表作为 data 参数传递给 pandas.DataFrame() 构造子。
外层列表内的每个内层列表将被转换为 DataFrame 的一行。
DataFrame() 类的语法为:
DataFrame(data=None, index=None, columns=None, dtype=None, copy=False)
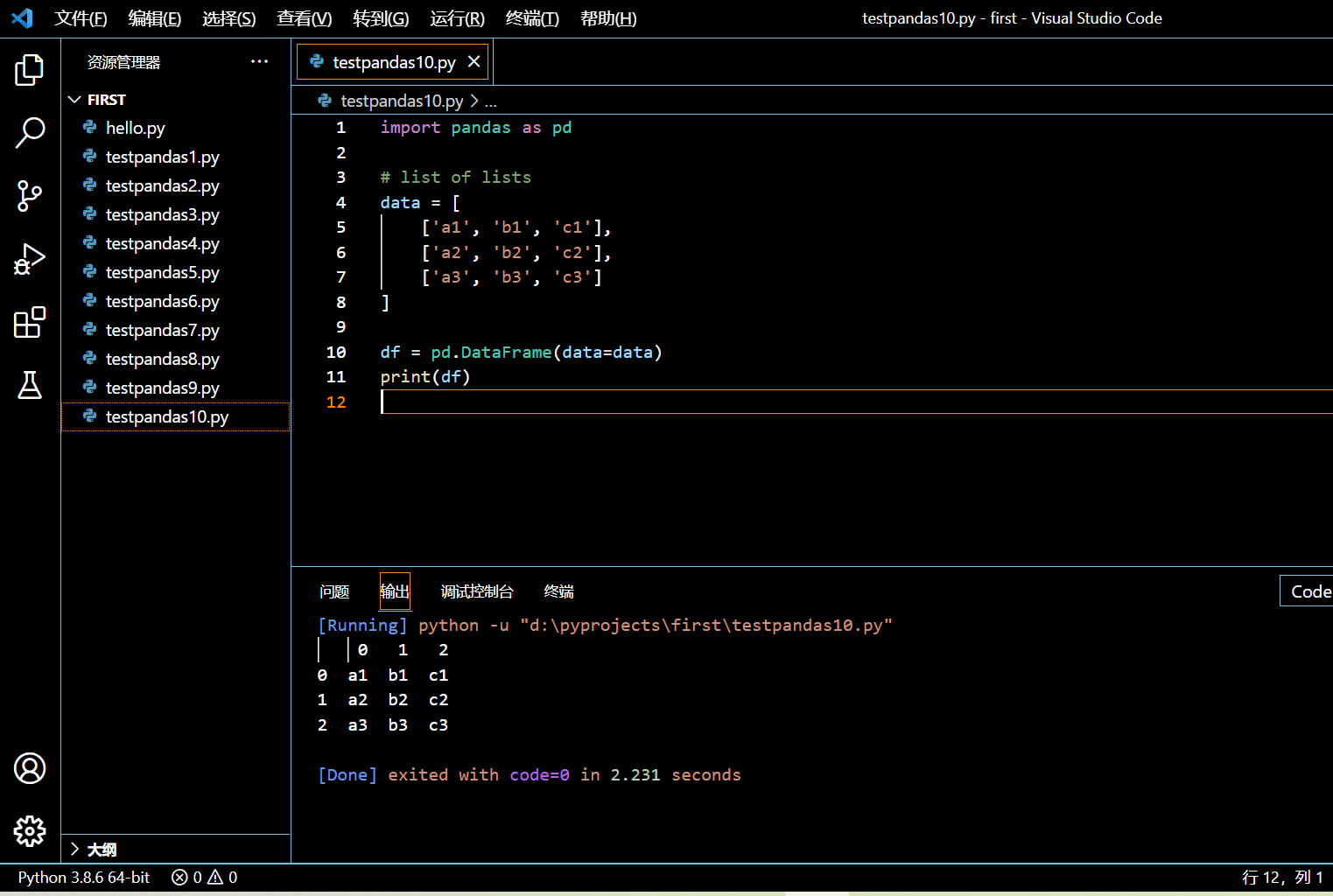
3.3.1. 以一系列列表创建 DataFrame
在接下来的示例中,我们将
- 导入 pandas 包。
- 初始化一个装有列表元素的列表。
- 将这个装有列表元素的列表作为 data 参数传给 pandas.DataFrame() 构造子以创建 DataFrame。
- pandas.DataFrame(list of lists) 返回 DataFrame 对象。
import pandas as pd
# list of lists
data = [
['a1', 'b1', 'c1'],
['a2', 'b2', 'c2'],
['a3', 'b3', 'c3']
]
df = pd.DataFrame(data=data)
print(df)
执行和输出:
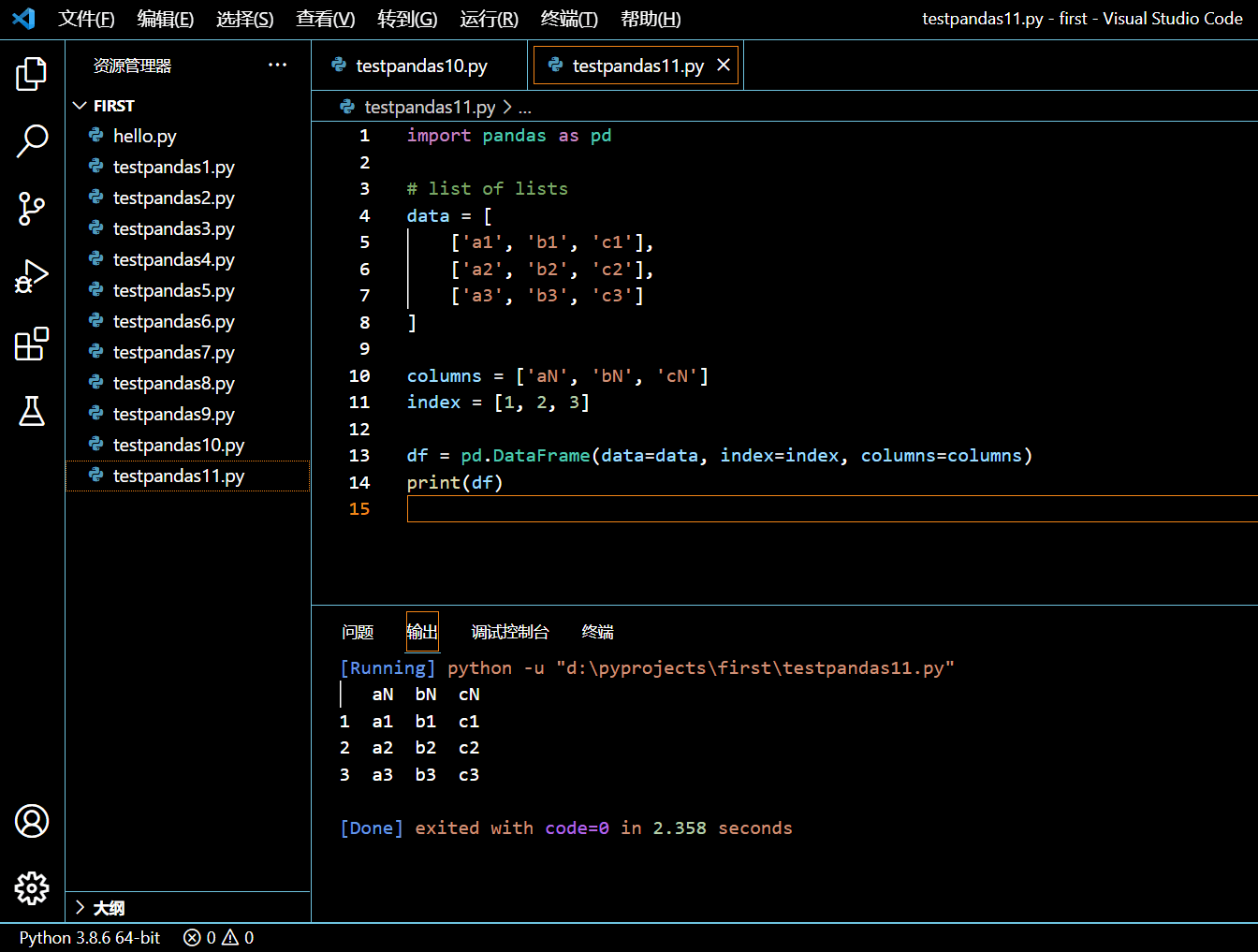
3.3.2. 以一系列列表创建自定义列名和索引的 DataFrame
在接下来的示例中,我们将
- 导入 pandas 包。
- 初始化一个装有列表元素的 Python 列表。
- 初始化将作为 DataFrame 列名的一张列表。
- 初始化将作为 DataFrame 索引的一张列表。
- 将这个装有列表元素的 Python 列表作为 data 参数传递给 pandas.DataFrame() 以创建一个 DataFrame 对象。
- pandas.DataFrame(list of lists) 返回 DataFrame 对象。
import pandas as pd
# list of lists
data = [
['a1', 'b1', 'c1'],
['a2', 'b2', 'c2'],
['a3', 'b3', 'c3']
]
columns = ['aN', 'bN', 'cN']
index = [1, 2, 3]
df = pd.DataFrame(data=data, index=index, columns=columns)
print(df)
执行和输出:
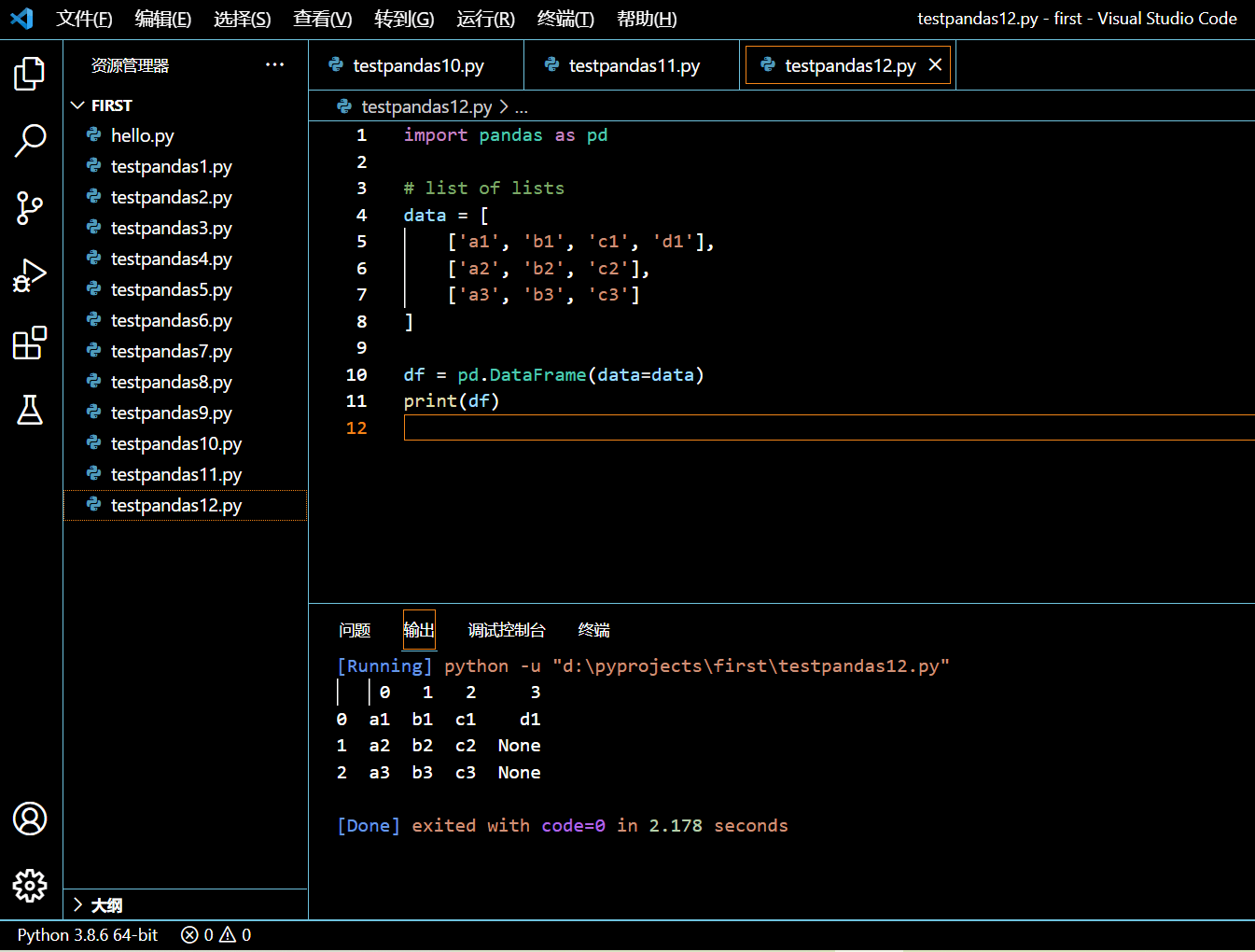
3.3.3. 以一装有不同长度列表元素的列表创建 DataFrame
如果内层的列表具有不同的长度,那么较短长度的列表将使用 None 值填充到最长 DataFrame 最长那行的长度。
在接下来的示例中,我们将
- 导入 pandas 包。
- 初始化装有列表元素的一张列表,内层列表具有不同的长度。
- 将这张装有列表元素的列表作为 data 参数传递给 pandas.DataFrame() 构造子来创建 DataFrame 对象。
- pandas.DataFrame(list of lists) 返回 DataFrame 对象。
import pandas as pd
# list of lists
data = [
['a1', 'b1', 'c1', 'd1'],
['a2', 'b2', 'c2'],
['a3', 'b3', 'c3']
]
df = pd.DataFrame(data=data)
print(df)
执行和输出:
3.3.4. 小结
在本小节中我们通过详尽的示例了解了如何使用装有列表元素的列表来创建一个 Pandas DataFrame。
3.4. 如何使用 Numpy 数组创建 Pandas DataFrame?
要使用 Numpy 数组创建 Pandas DataFrame,你可以将该数组作为 data 参数传给 pandas.DataFrame() 构造子。
Numpy 数组中的每一行将被转化为 DataFrame 的一行。
DataFrame() 构造子语法如下:
DataFrame(data=None, index=None, columns=None, dtype=None, copy=False)
3.4.1. 由 Numpy 数组创建 DataFrame
在本示例中,我们将,
- 导入 pandas 和 numpy 包。
- 初始化一个两维的 Numpy 数组 array。
- 将这个 Numpy 数组 array 作为 data 参数传给 pandas.DataFrame() 来创建 DataFrame。
- pandas.DataFrame(numpy array)返回 DataFrame 对象。
import pandas as pd
import numpy as np
array = np.array([
['a1', 'b1', 'c1'],
['a2', 'b2', 'c2'],
['a3', 'b3', 'c3']
])
df = pd.DataFrame(array)
print(df)
print(type(df))
执行和输出:
3.4.2. 使用 Numpy 数组来创建自定义列名、索引的 DataFrame
在本示例中,我们将
- 导入 pandas 和 numpy 包。
- 初始化一个两维的 Numpy 数组。
- 初始化一个用于封装 DataFrame 列名的列表。
- 初始化一个用于封装 DataFrame 索引的列表。
- 将这个 numpy 数组对象作为 data 参数传递给 pandas.DataFrame() 构造子来创建 DataFrame。
- pandas.DataFrame(ndarray) 返回 DataFrame 对象。
import pandas as pd
import numpy as np
array = np.array([
['a1', 'b1', 'c1'],
['a2', 'b2', 'c2'],
['a3', 'b3', 'c3']
])
columns = ['aN', 'bN', 'cN']
index = [1, 2, 3]
df = pd.DataFrame(data=array, index=index, columns=columns)
print(df)
print(type(df))
执行和输出:
3.4.3. 小结
本小节中,我们通过详细示例了解了如何使用 Numpy 多维数组来创建一个 Pandas DataFrame。
3.5. 如何由 CSV 加载 Pandas DataFrame?
可以使用 pandas.read_csv() 函数来将一个 CSV 文件里的数据加载到 Pandas DataFrame。
在本小节中,我们将在多个不同场景下了解把 CSV 的数据加载到 Pandas DataFrame。

3.5.1. 将 CSV 数据装载到 DataFrame
在本示例中,我们将以下面的 csv 文件为例,查看如何使用 pandas.read_csv() 方法将其数据装载到一个 DataFrame。
data.csv 文件放在项目目录下:
name,physics,chemistry,algebra
Somu,68,84,78
Kiku,74,56,88
Amol,77,73,82
Lini,78,69,87
程序如下:
import pandas as pd
# load dataframe from csv
df = pd.read_csv("data.csv")
# print dataframe
print(df)
print(type(df))
执行和输出:
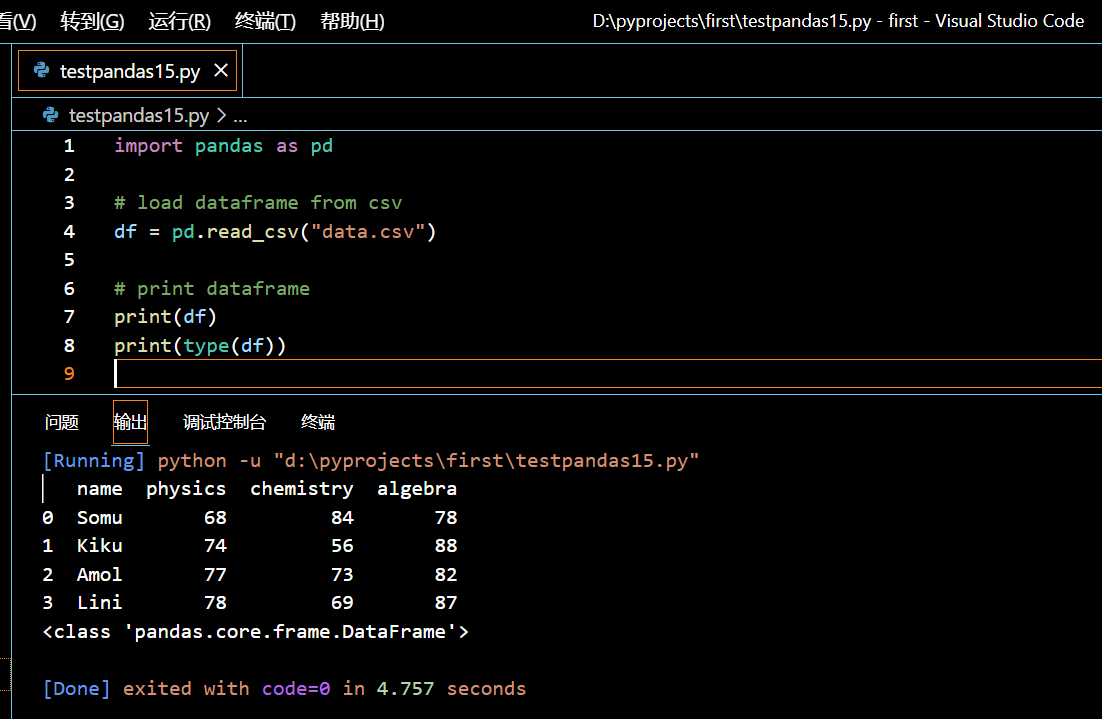
可见,csv 文件的第一行被转换成了 DataFrame 的列名,而其他行则成为了 DataFrame 的普通列。
3.5.2. 将特殊分隔符的 CSV 数据装载到 DataFrame
如果你使用了英文逗号以外的分隔符来区分你 csv 文件里的项目,你可以使用 read_csv() 的 delimiter 参数来指定你的分隔符。
比如以下 csv 文件,在这个文件中,分隔符是为单个空格。
data.csv 文件放在项目目录下:
name physics chemistry algebra
Somu 68 84 78
Kiku 74 56 88
Amol 77 73 82
Lini 78 69 87
现在我们给 read_csv() 函数以 delimiter 参数来指定空格是我们的分隔符:
import pandas as pd
# load dataframe from csv
df = pd.read_csv("data.csv", delimiter=" ")
# print dataframe
print(df)
print(type(df))
执行和输出:
3.5.3. 将没有 header 的 CSV 数据装载到 DataFrame
如果你的 CSV 文件没有 header(即列名),你可以通过两种方式将其指定给 read_csv():
- 将参数 header=None 传给 pandas.read_csv() 函数。
- 将参数 names 传给 pandas.read_csv() 函数,它隐式指定 header=None。
data.csv 文件放在项目目录下:
Somu,68,84,78
Kiku,74,56,88
Amol,77,73,82
Lini,78,69,87
编写代码:
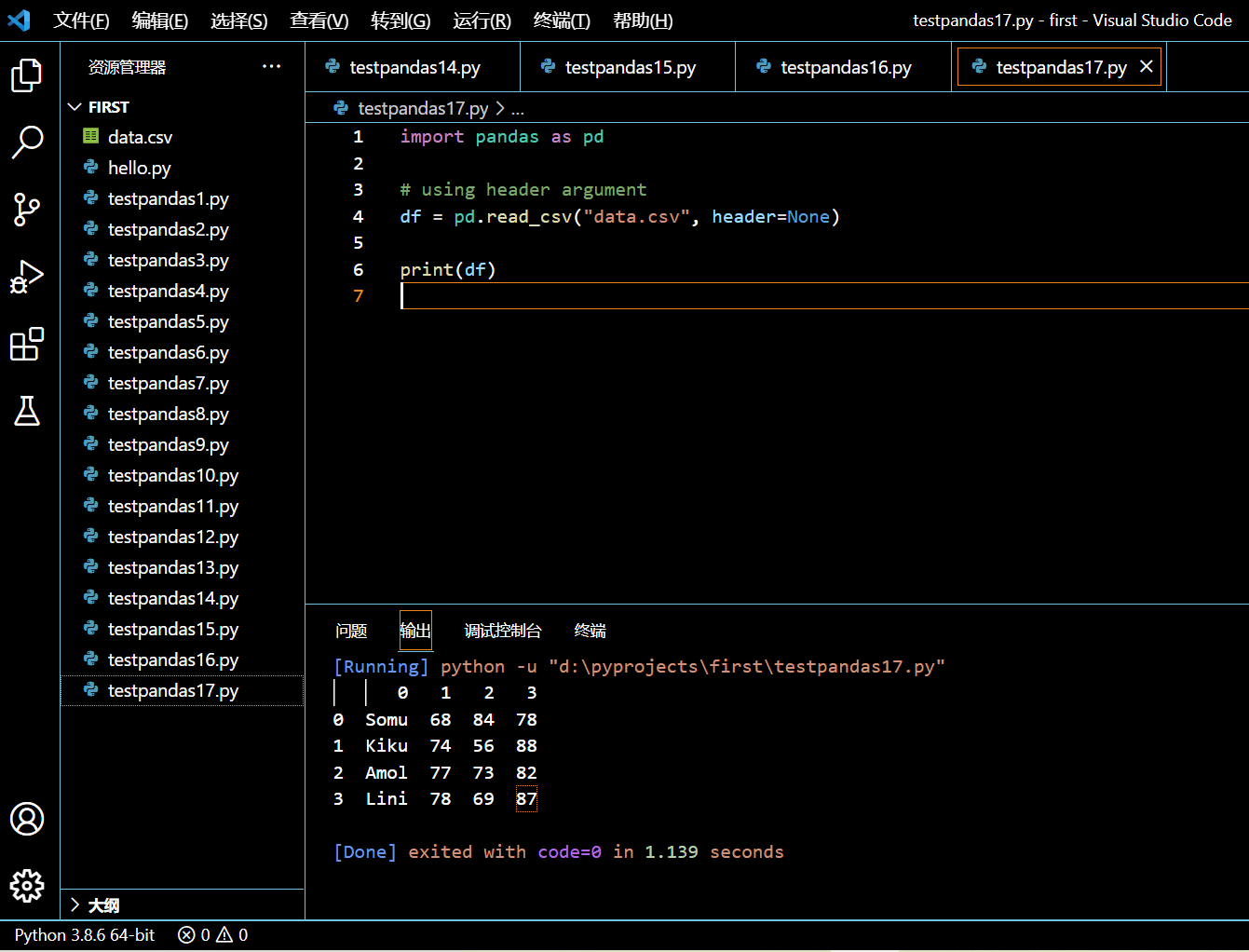
import pandas as pd
# using header argument
df = pd.read_csv("data.csv", header=None)
print(df)
执行和输出:
3.5.4. 小结
在本小节里,我们了解到了如何将 csv 文件的数据加载到 Pandas DataFrame。
3.6. 如何打印 Pandas DataFrame 的信息?
可以调用 DataFrame.info() 方法来打印 Pandas DataFrame 的信息。DataFrame.info() 方法不会返回任何信息,它只是把这个 DataFrame 的信息打印一下。
DataFrame 的 info() 方法的语法如下:
DataFrame.info(verbose=None, buf=None, max_cols=None, memory_usage=None, show_counts=None, null_counts=None)
3.6.1. 打印 DataFrame 信息
在接下来的程序里,我们将创建一个 DataFrame,然后使用 DataFrame.info() 将这个 DataFrame 的信息打印出来。
import pandas as pd
df = pd.DataFrame(
data=[
['abc', 22],
['xyz', 25],
['pqr', 31]
],
columns=['name', 'age']
)
df.info()
执行和输出:
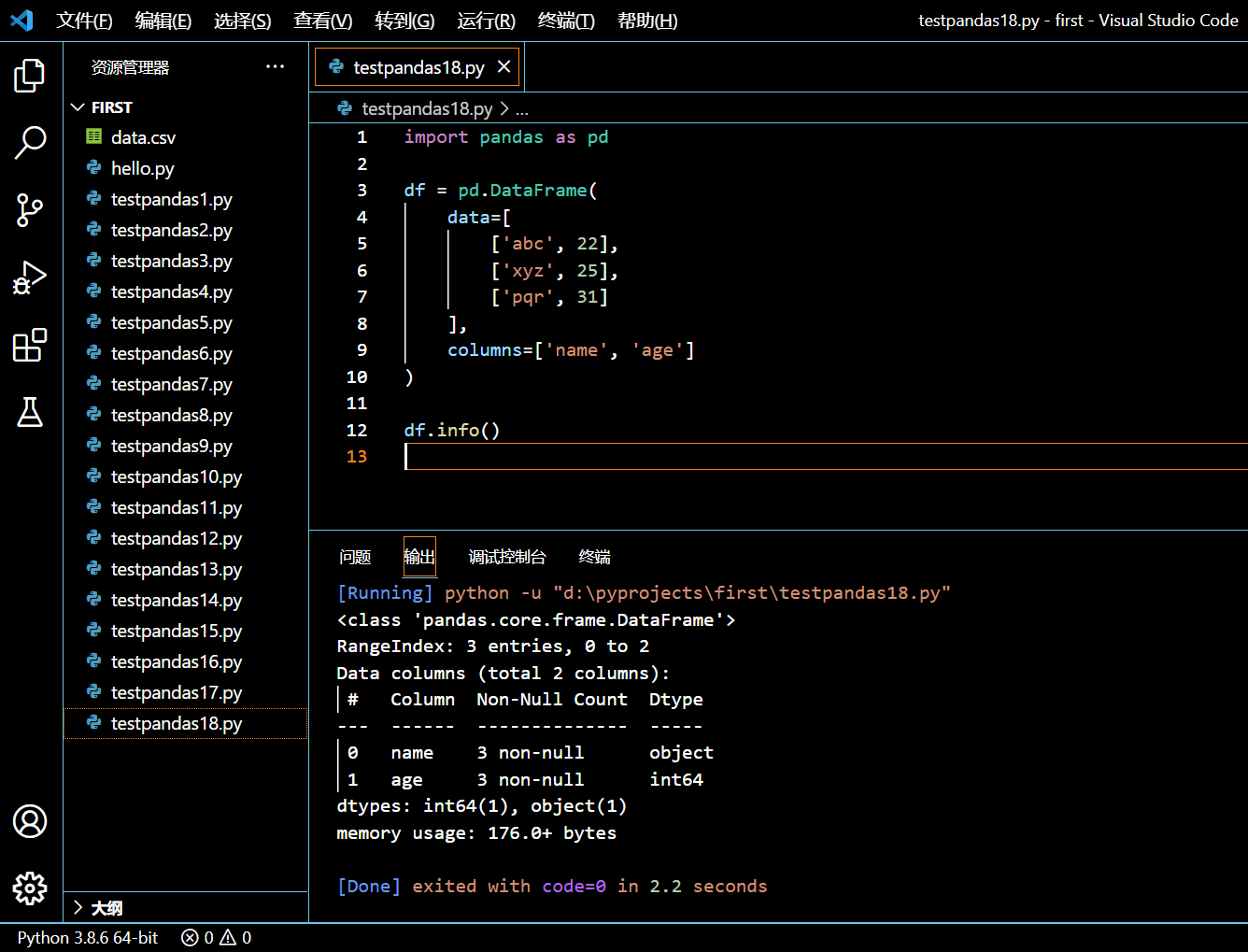
仔细观察,你会发现,info() 方法打印出了这个对象的类型、范围、列、每列条目数、每列非空值数、每列数据类型、这一 DataFrame 对象所占用的内存大小。
3.6.2. 小结
本小节中,我们了解到了如何使用 DataFrame.info() 方法打印一个 DataFrame 的相关信息。
3.7. 获取索引
要拿到 Pandas DataFrame 的索引,调用 DataFrame.index 属性。DataFrame.index 属性将返回一个表示该 DataFrame 索引的 Index 对象。
DataFrame index 属性使用的语法如下:
DataFrame.index
该索引属性返回一个 Index 类型的对象。我们可以用 Python 所支持的任意遍历手段(参考博客《简单 Python 快乐之旅之:Python 基础语法之循环关键字的使用例子》)来访问单个索引。
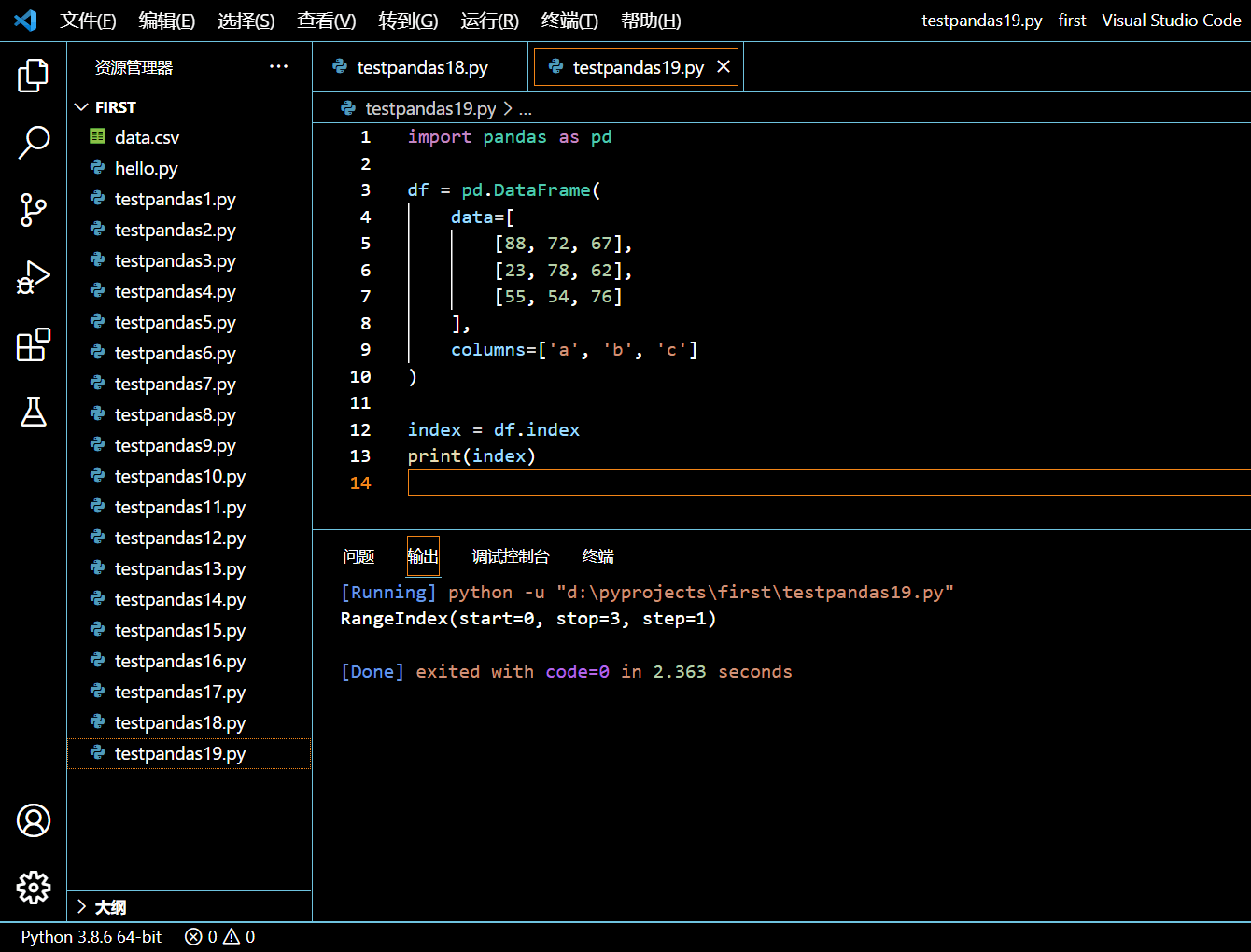
在接下来的示例中,我们将创建一个没有指定任何索引的 DataFrame。既然没有指定索引,Python 将从 0 开始并以 1 为增量的索引分配给 DataFrame。现在我们就使用 DataFrame.index 来拿到这个 DataFrame 的索引。
import pandas as pd
df = pd.DataFrame(
data=[
[88, 72, 67],
[23, 78, 62],
[55, 54, 76]
],
columns=['a', 'b', 'c']
)
index = df.index
print(index)
执行和输出:
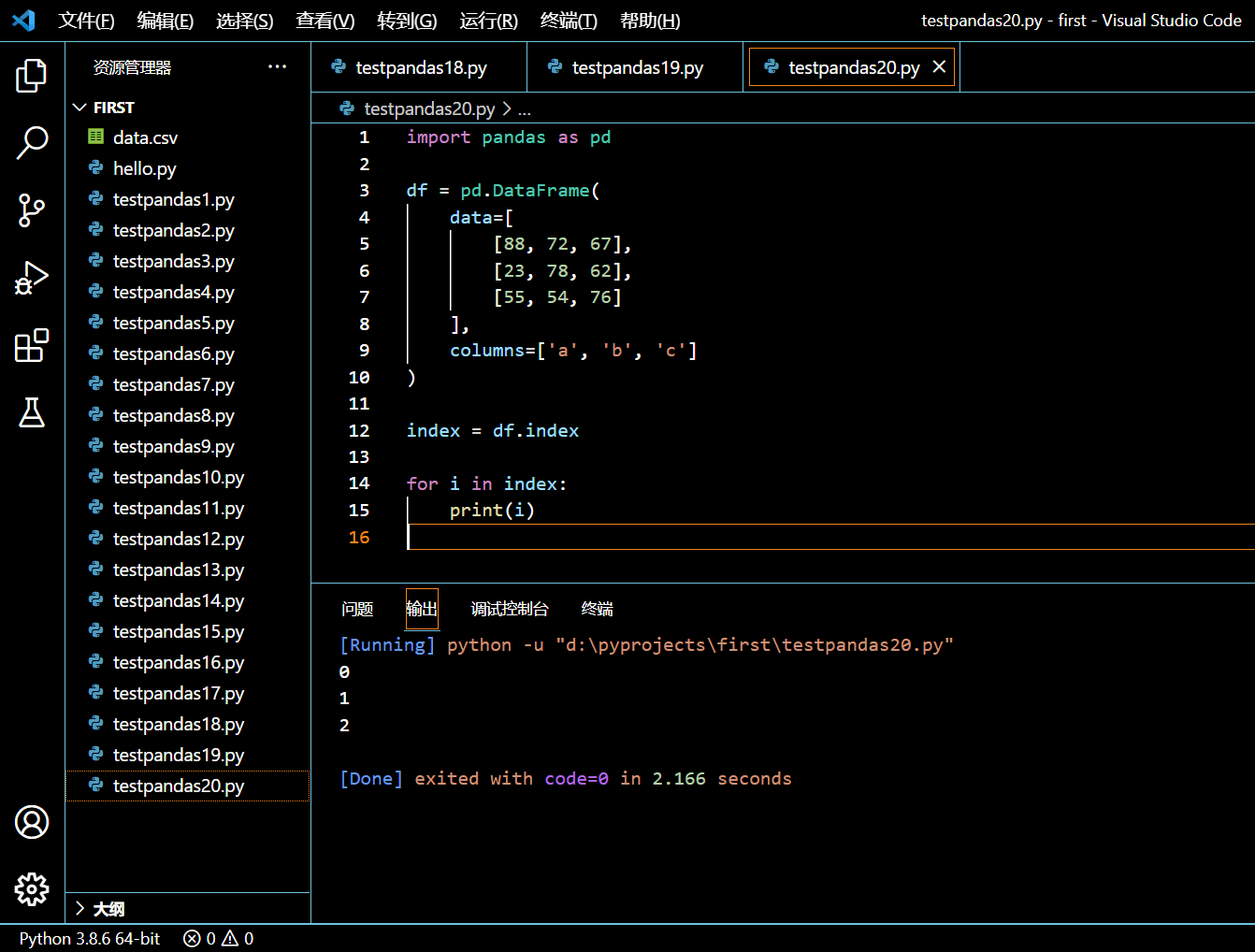
我们可以使用一个 for 循环来打印 Index 对象的相关元素:
import pandas as pd
df = pd.DataFrame(
data=[
[88, 72, 67],
[23, 78, 62],
[55, 54, 76]
],
columns=['a', 'b', 'c']
)
index = df.index
for i in index:
print(i)
执行和输出:
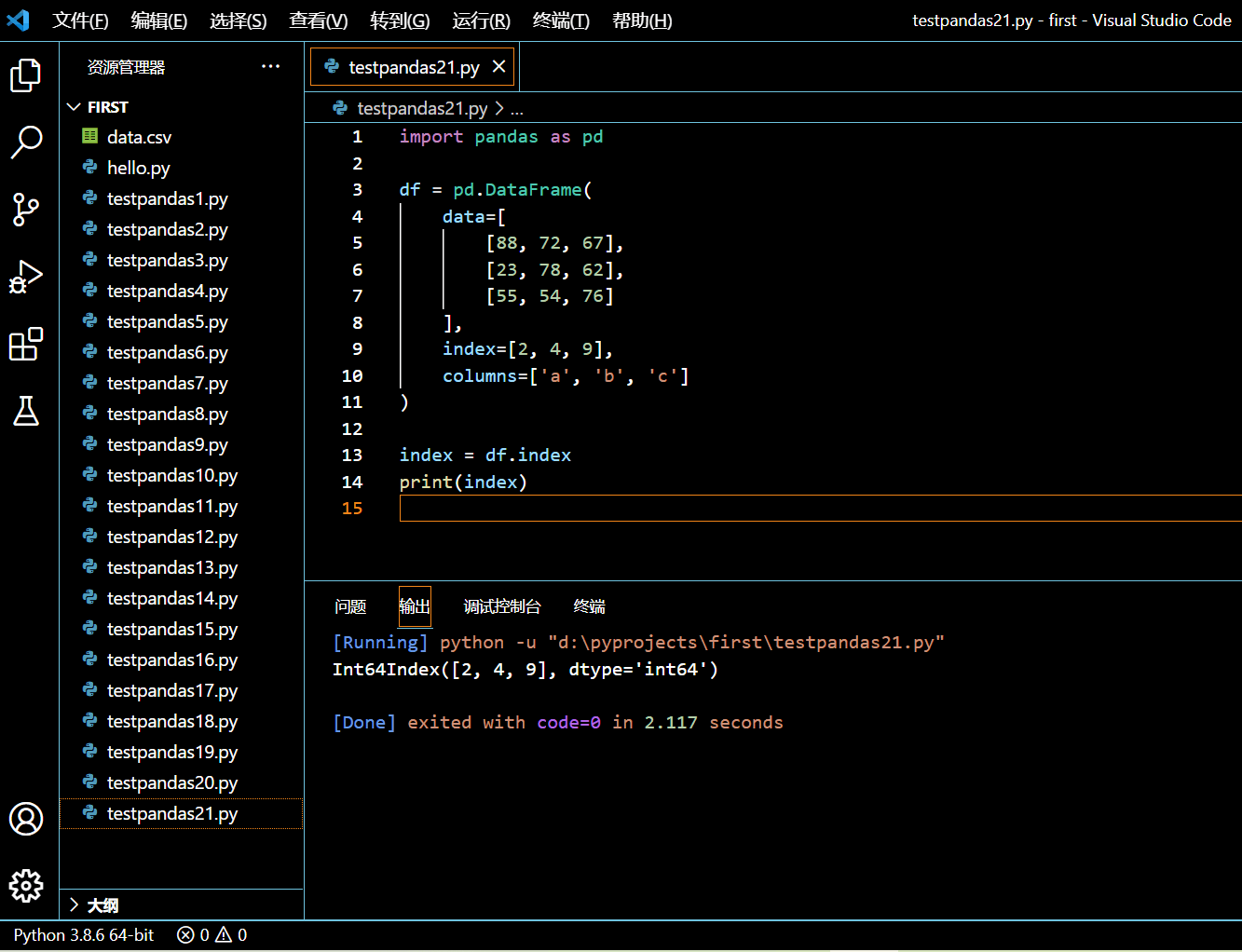
接下来我们考虑一下另外一个我们为 DataFrame 指定了自定义索引的例子,然后使用 DataFrame.index 拿到这个 DataFrame 的索引。
import pandas as pd
df = pd.DataFrame(
data=[
[88, 72, 67],
[23, 78, 62],
[55, 54, 76]
],
index=[2, 4, 9],
columns=['a', 'b', 'c']
)
index = df.index
print(index)
执行和输出:
3.7.1. 小结
在本小节中,我们了解到了如何使用 DataFrame.index 属性来获取 DataFrame 的索引。
3.8. 怎样判断 Pandas DataFrame 对象是空的?
在 Pandas 里,要验证一个 DataFrame 是否是空的,可以使用 DataFrame.empty 属性。
DataFrame.empty 将返回一个布尔值来指明当前 DataFrame 是空或是非空。如果该 DataFrame 是空的,将返回 True。如果该 DataFrame 不是空的,那么将返回 False。
3.8.1. 空 DataFrame
在本示例中,我们将初始化一个空 DataFrame,并使用 DataFrame.empty 属性来校验该 DataFrame 是否为空。
import pandas as pd
# initialize a dataframe
df = pd.DataFrame()
isempty = df.empty
print('Is the DataFrame empty :', isempty)
执行和输出:
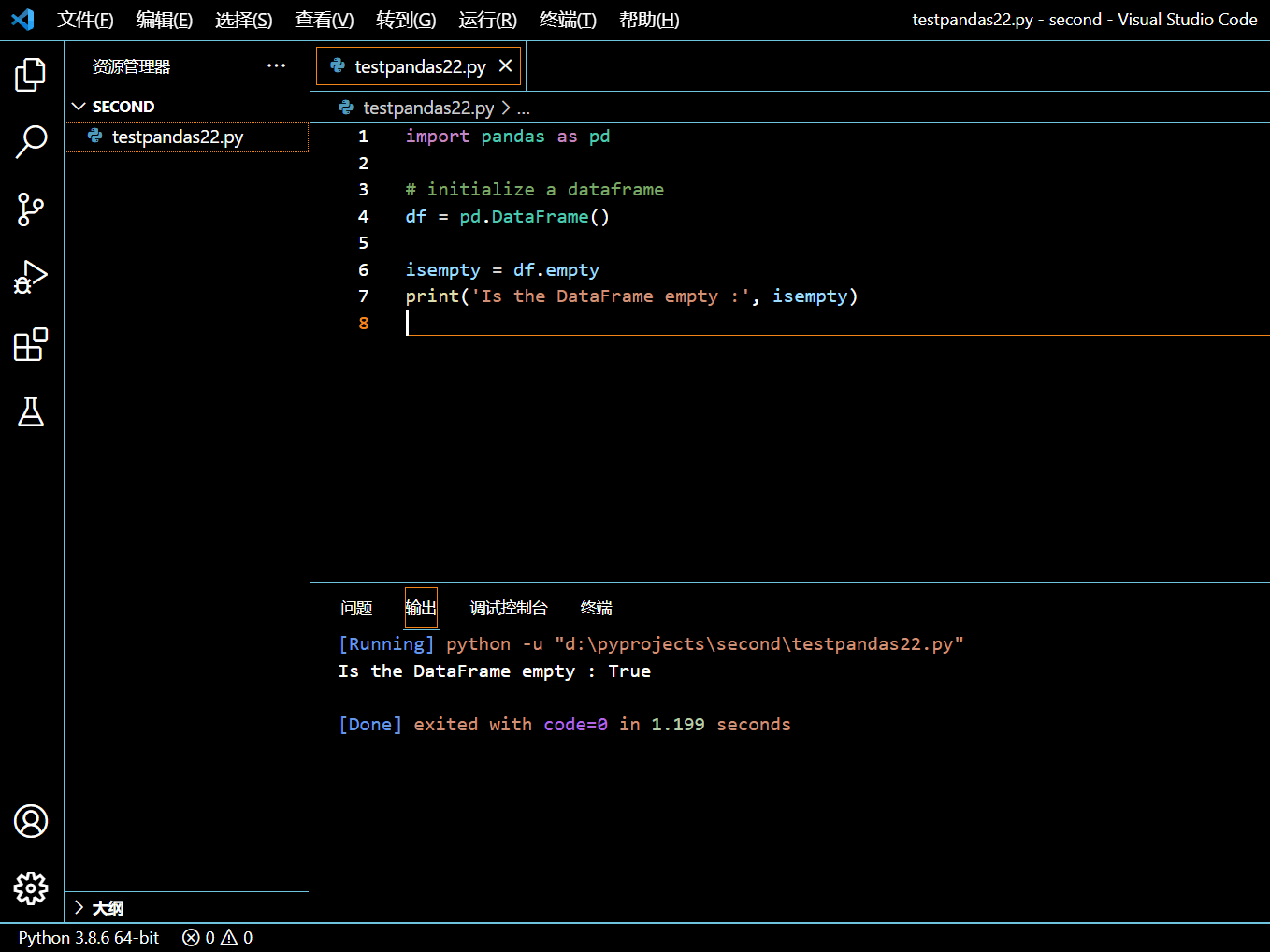
df = pd.DataFrame() 初始化了一个空的 DataFrame。之后由 df.empty 判断该 DataFrame 是否为空。由于该 DataFrame 是空的,我们将得到 True 的布尔结果。
3.8.2. 非空 DataFrame
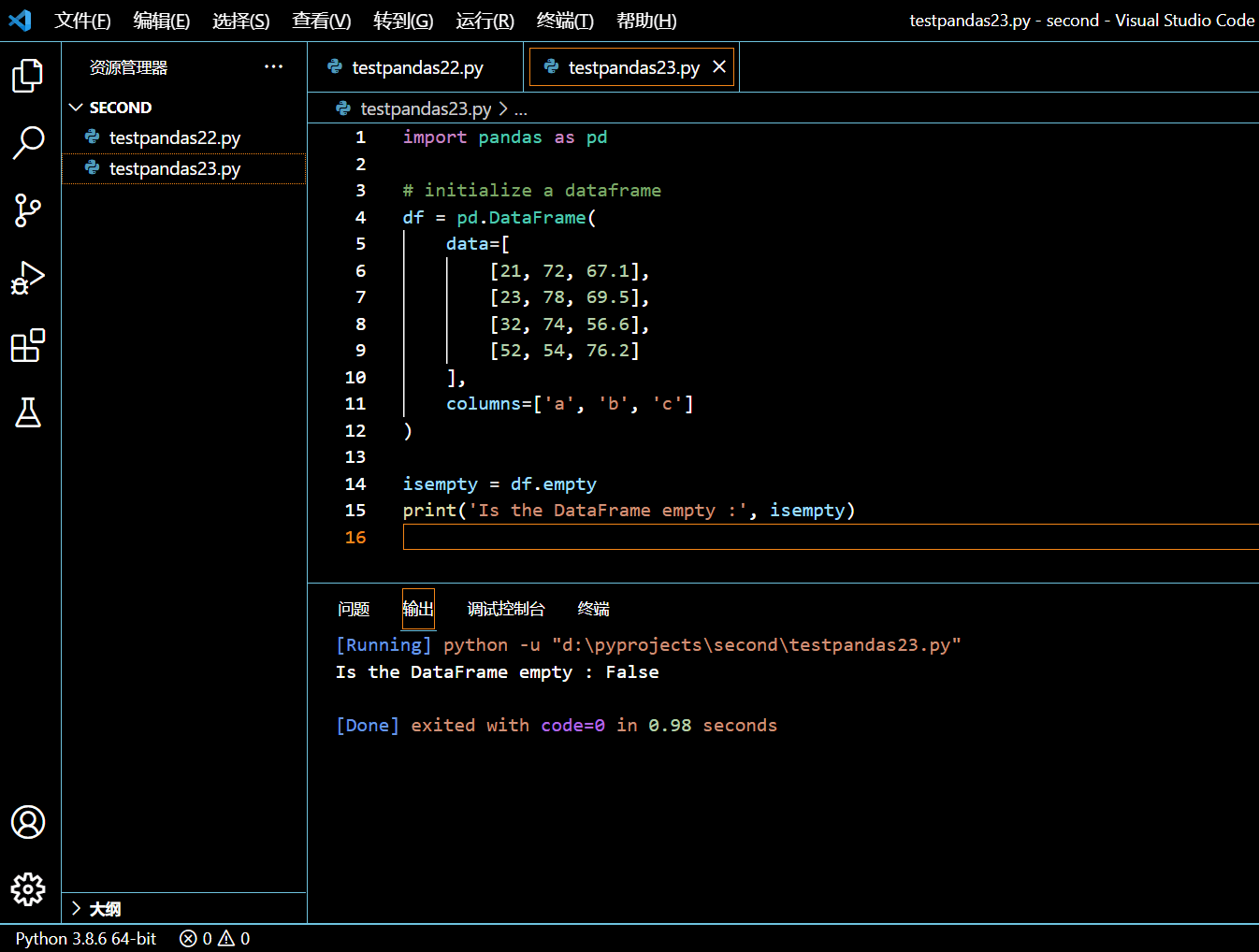
在接下来的示例中,我们将初始化一个多行的 DataFrame 并校验 DataFrame.empty 属性是否会返回 False。
import pandas as pd
# initialize a dataframe
df = pd.DataFrame(
data=[
[21, 72, 67.1],
[23, 78, 69.5],
[32, 74, 56.6],
[52, 54, 76.2]
],
columns=['a', 'b', 'c']
)
isempty = df.empty
print('Is the DataFrame empty :', isempty)
执行和输出:
3.8.3. 小结
在本小节中,我们了解到了如何校验一个 Pandas DataFrame 是否为空。
3.9. 如何拿到 Pandas DataFrame 的轴数
可以调用 DataFrame.ndim 属性来获取 Pandas DataFrame 对象的轴数或数组维度。DataFrame.ndim 将返回一个代表本 DataFrame 中轴数的整型数据。
调用一个 DataFrame ndim 属性的语法是
DataFrame.ndim
3.9.1. 拿到 DataFrame 的轴数
在本示例中,我们将创建一个 DataFrame,然后我们用 DataFrame.ndim 来获取到本 DataFrame 中的轴数。
import pandas as pd
df = pd.DataFrame(
data=[
['abc', 22, 22.6],
['xyz', 25, 23.2],
['pqr', 31, 30.5]
],
columns=['name', 'age', 'bmi']
)
number_of_axes = df.ndim
print(f'Number of axes in this DataFrame = {number_of_axes}')
执行和输出:
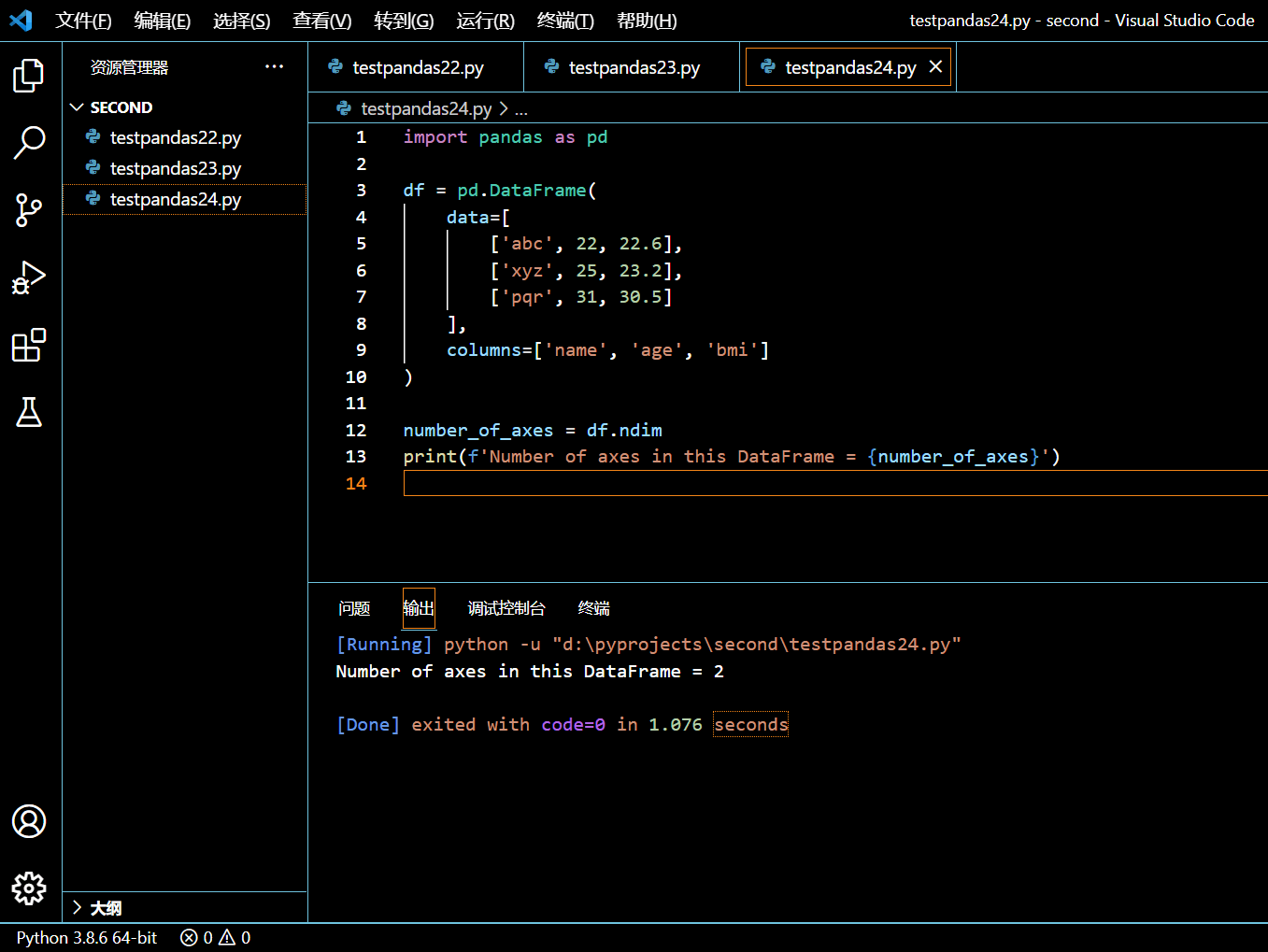
由于我们的 DataFrame 只有两轴,所以 ndim 属性返回 2。
3.9.2. 小结
本节中,我们了解到了如何使用 DataFrame.ndim 属性来拿到一个 DataFrame 中的轴数。
3.10. 访问单个数据
有两种办法可以访问一个 DataFrame 中的单个数据:
方法 1:DataFrame.at[index, column_name] 属性返回由索引表示所在行、列名表示所在列的那个单个元素的值
方法2:或者也可以使用 DataFrame.iat(row_position, column_position) 直接访问行位置 row_position、列位置 column_position 所表示位置的值,与行或列的标签无关。
在本节中,我们将使用 DataFrame.at() 和 DataFrame.iat() 来访问 DataFrame 中的单个元素的值。
3.10.1. DataFrame.at 自定义索引
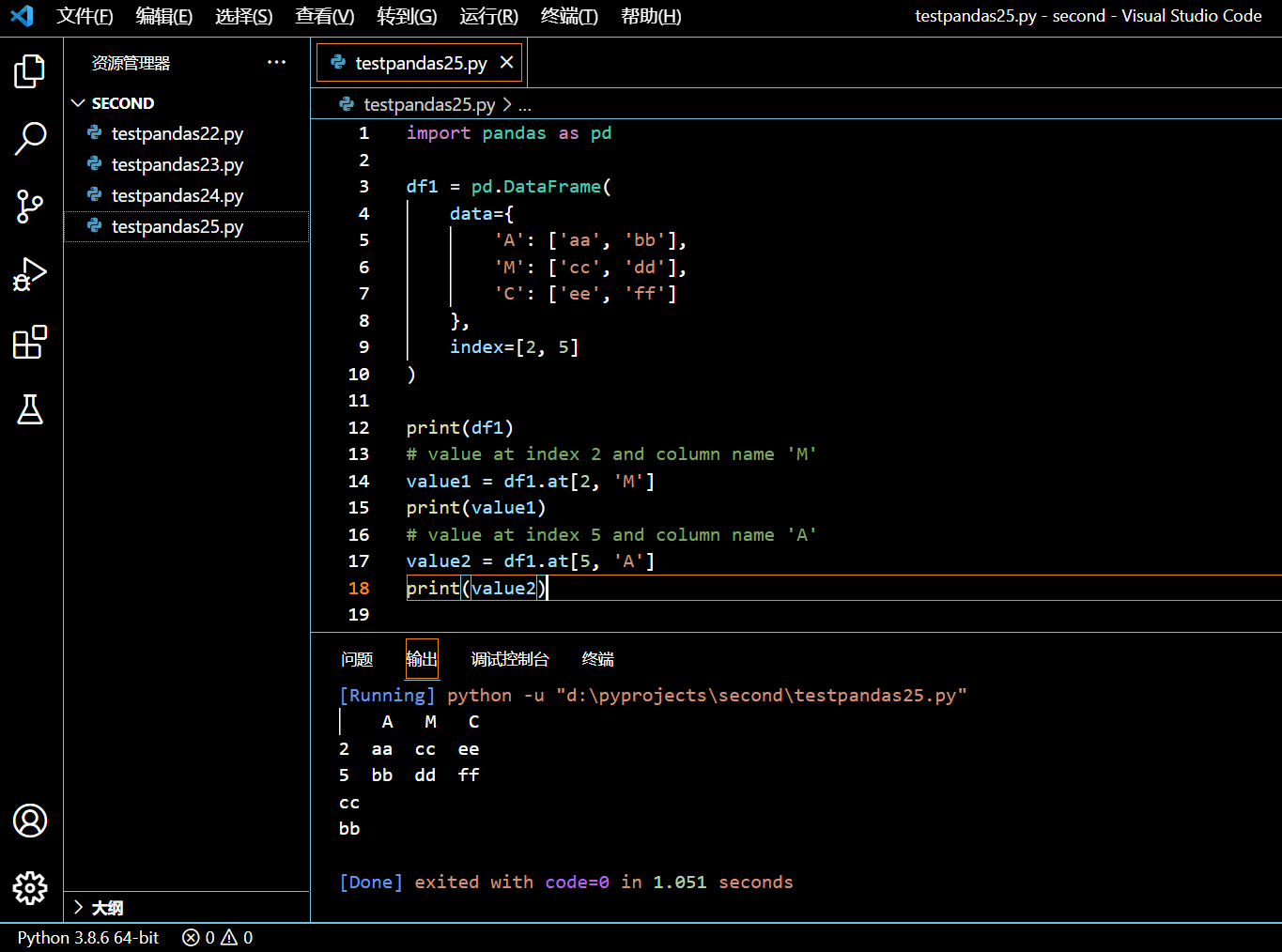
在接下来的示例中,我们将初始化一个 DataFrame 并使用 DataFrame.at 属性去访问一个值。
import pandas as pd
df1 = pd.DataFrame(
data={
'A': ['aa', 'bb'],
'M': ['cc', 'dd'],
'C': ['ee', 'ff']
},
index=[2, 5]
)
print(df1)
# value at index 2 and column name 'M'
value1 = df1.at[2, 'M']
print(value1)
# value at index 5 and column name 'A'
value2 = df1.at[5, 'A']
print(value2)
执行和输出:
3.10.2. DataFrame.at 无自定义索引
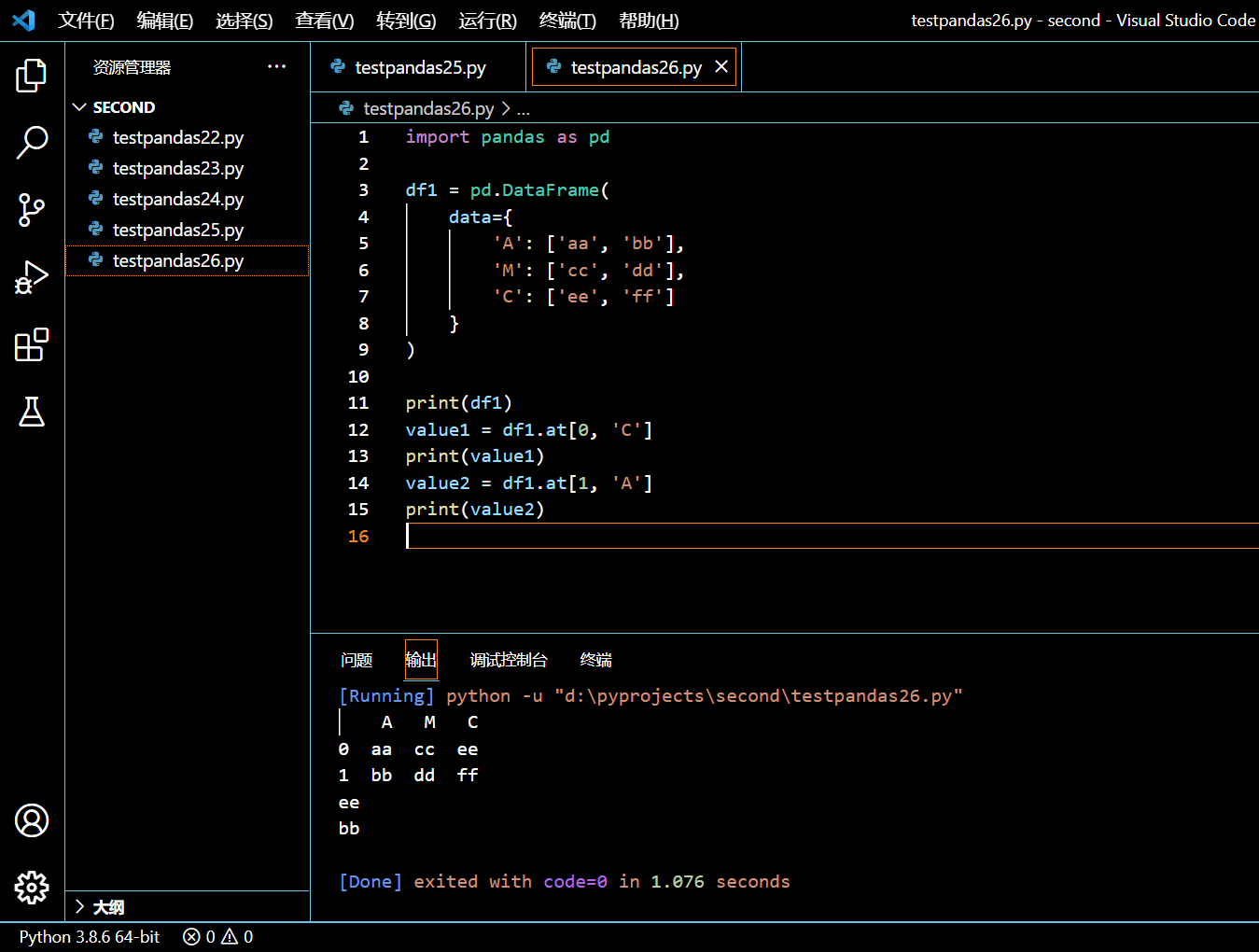
在本示例中,我们将创建一个没有自定义索引的 DataFrame。如果没有提供索引,你可以认为索引是从 0 开始,并且以行递进增 1。
import pandas as pd
df1 = pd.DataFrame(
data={
'A': ['aa', 'bb'],
'M': ['cc', 'dd'],
'C': ['ee', 'ff']
}
)
print(df1)
value1 = df1.at[0, 'C']
print(value1)
value2 = df1.at[1, 'A']
print(value2)
执行和输出:
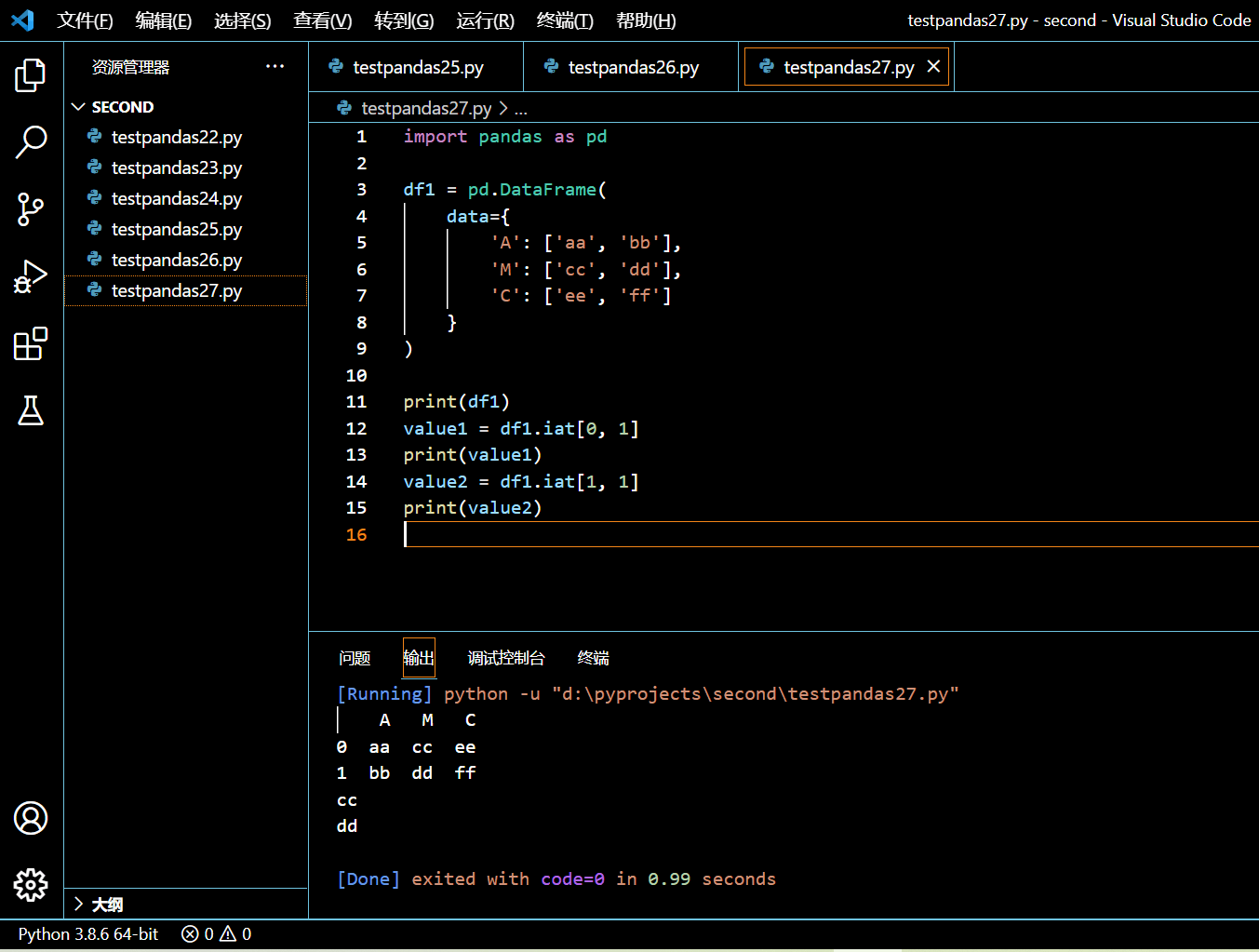
3.10.3. DataFrame.iat
在接下来的示例中,我们将创建一个没有自定义索引的 DataFrame。如果没有提供索引,你可以认为索引是从 0 开始,并且以行递进增 1。
import pandas as pd
df1 = pd.DataFrame(
data={
'A': ['aa', 'bb'],
'M': ['cc', 'dd'],
'C': ['ee', 'ff']
}
)
print(df1)
value1 = df1.iat[0, 1]
print(value1)
value2 = df1.iat[1, 1]
print(value2)
执行和输出:
3.10.4. 小结
在本节中,我们了解到了如何获取 DataFrame 中的单个值。
3.11. 如何获取 Pandas 中元素的个数?
可以通过调用 DataFrame.size 属性来拿到一个 Pandas DataFrame 中所包含元素的个数。DataFrame.size 属性将返回一个表示该 DataFrame 中元素个数的整型数据。或者说,size 属性返回行数乘以列数。
调用 DataFrame size 属性的语法为:
DataFrame.size
3.11.1. 获取 DataFrame 中元素数
在接下来的示例中,我们将创建一个 DataFrame 并使用 DataFrame.size 属性来拿到它所包含的元素个数。
import pandas as pd
df = pd.DataFrame(
data=[
['abc', 22, 22.6],
['xyz', 25, 23.1],
['pqr', 31, 30.5]
],
columns=['name', 'age', 'bmi']
)
print(df)
number_of_elements = df.size
print(f"Number of elements in this DataFrame = {number_of_elements}")
执行和输出:
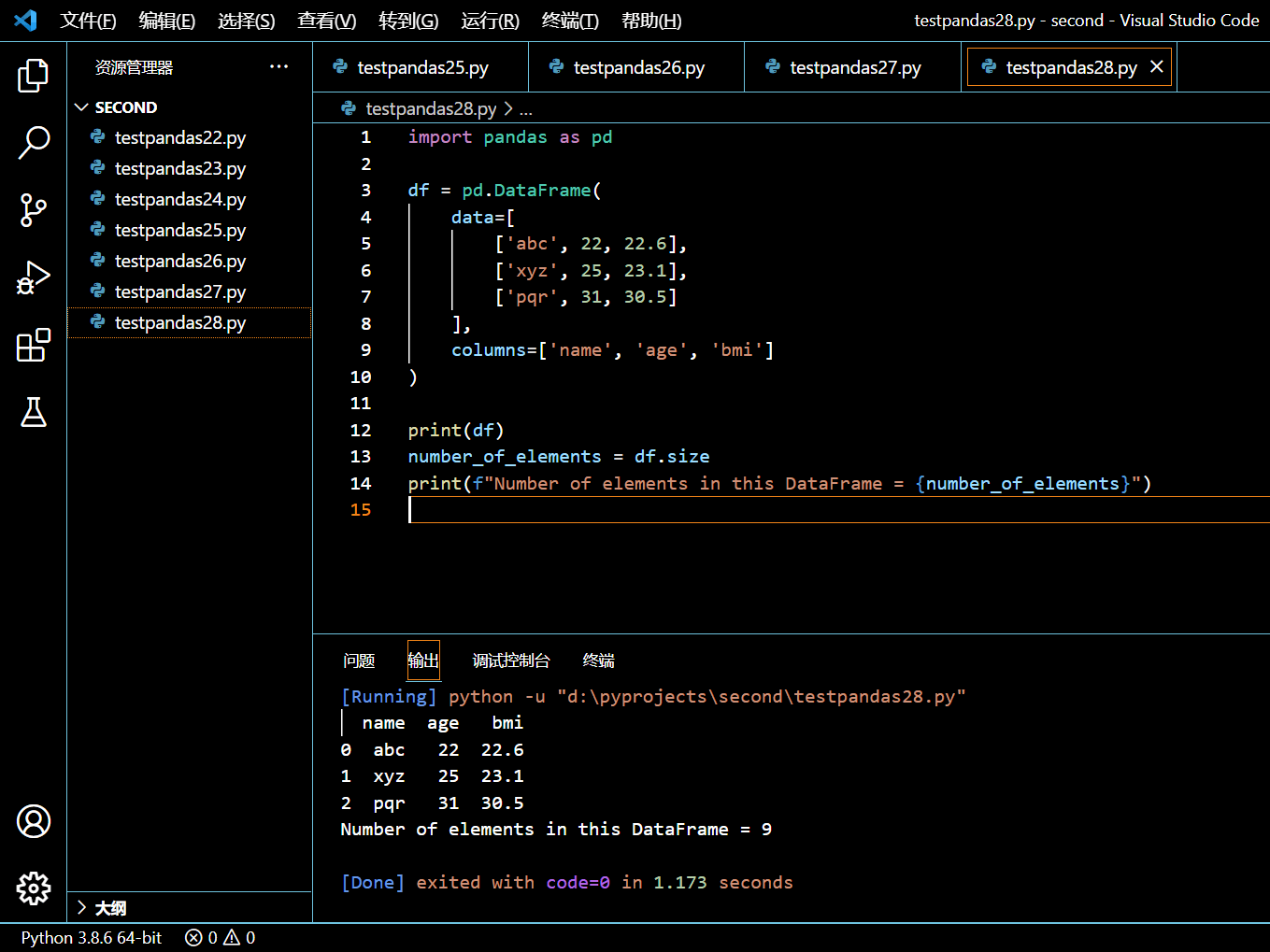
由于该 DataFrame 中有三行三列,所以 size 属性返回 3 * 3 = 9
3.11.2. 小结
在本节中,我们了解到了如何使用 DataFrame.size 来拿到 DataFrame 中元素数。
3.12. 如何拿到 Pandas DataFrame 的形状?
可以使用 DataFrame.shape 拿到 Pandas DataFrame 的形状。属性 shape 返回一个表示该 DataFrame 维度的元组。返回格式为 (rows, columns)。
在本节,我们将了解到如何拿到这个形状,亦即,DataFrame 的行数和列数。
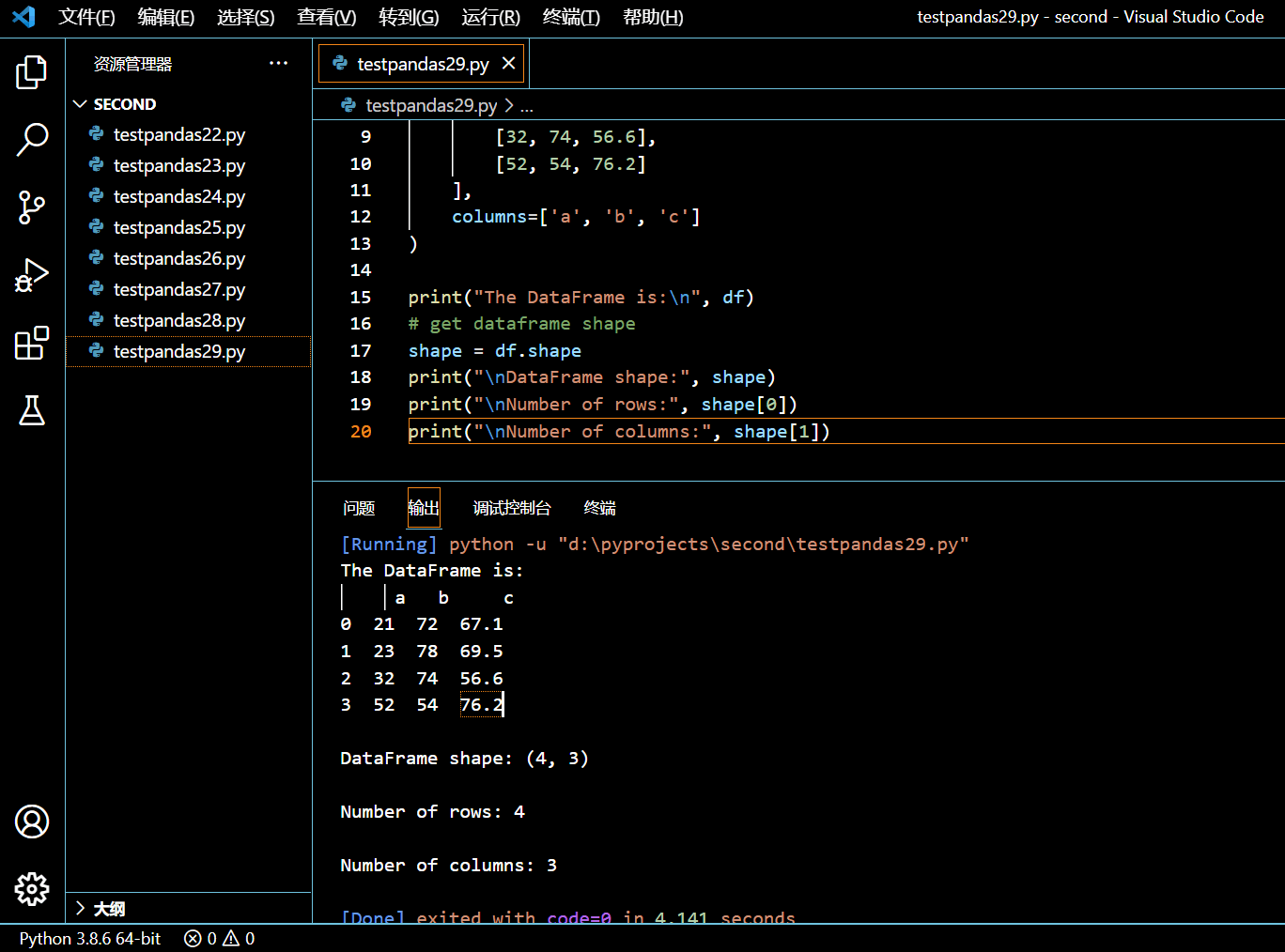
3.12.1. DataFrame 形状
在接下来的示例中,我们来探索如何得到 DataFrame 的形状。此外,你还能通过索引得到行数或列数。
import pandas as pd
import numpy as np
# initialize a dataframe
df = pd.DataFrame(
data=[
[21, 72, 67.1],
[23, 78, 69.5],
[32, 74, 56.6],
[52, 54, 76.2]
],
columns=['a', 'b', 'c']
)
print("The DataFrame is:\n", df)
# get dataframe shape
shape = df.shape
print("\nDataFrame shape:", shape)
print("\nNumber of rows:", shape[0])
print("\nNumber of columns:", shape[1])
执行和输出:
3.12.2. 空 DataFrame 的形状
在接下来的示例中,我们将初始化一个空的 DataFrame,然后试着获取它的形状。当然,DataFrame.shape 将会返回 (0, 0)。
import pandas as pd
# initialize a dataframe
df = pd.DataFrame()
print('The DataFrame is:\n', df)
# get dataframe shape
shape = df.shape
print('DataFrame shape:', shape)
print('Number of rows:', shape[0])
print('Number of columns:', shape[1])
执行和输出:
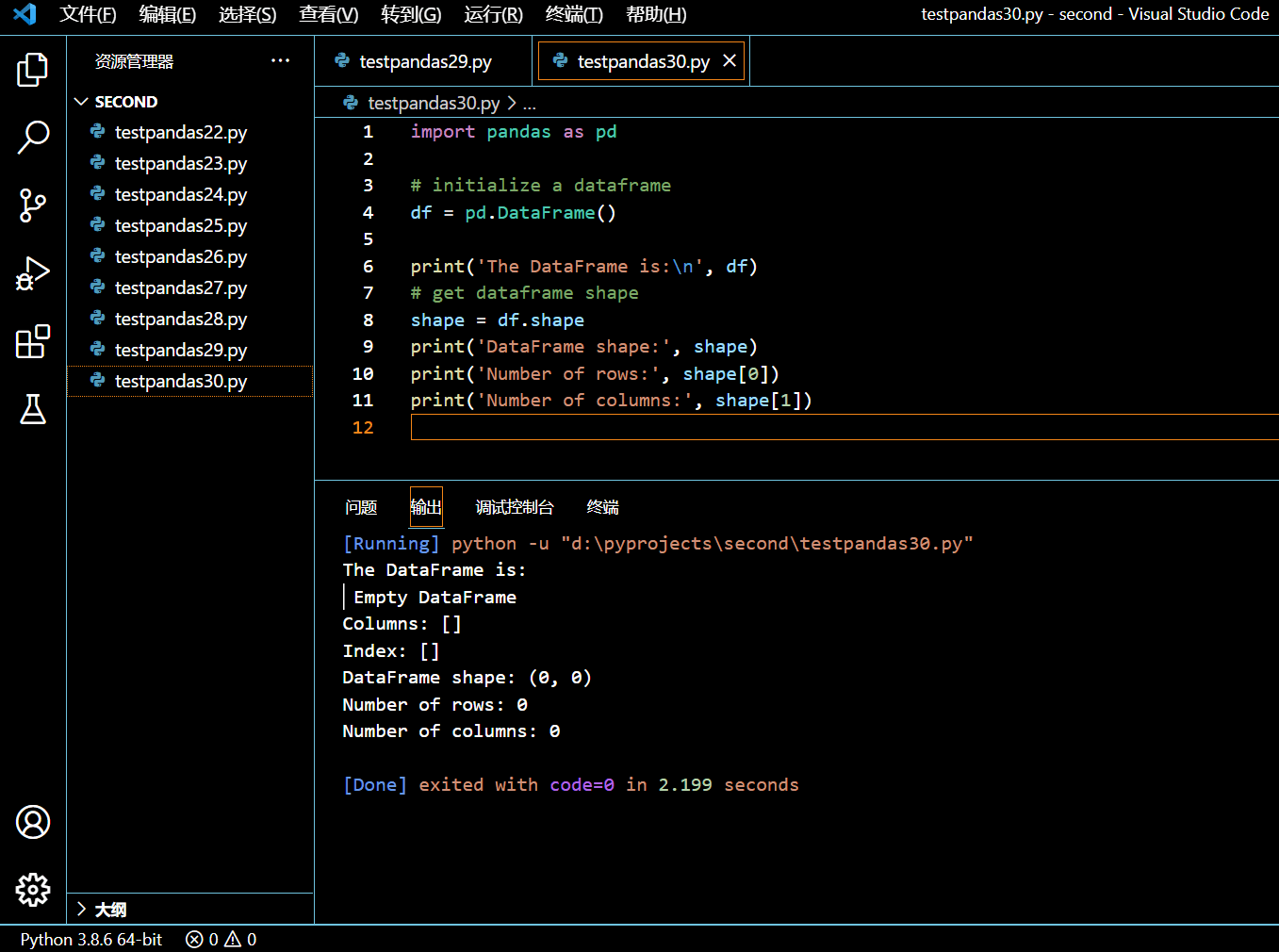
行数和列数都是零。
3.12.3. 小结
本节,我们了解到了如何获取 DataFrame 的形状,亦即,行数和列数。
3.13. 如何连接 Pandas 里的 DataFrame?
你可以将两个或多个具有相似列的 Pandas DataFrame 连接起来。连接 DataFrame 通常使用 pandas.concat() 方法。
在本节中,我们将了解如何将具有相似或不同列的 DataFrame 连接起来。
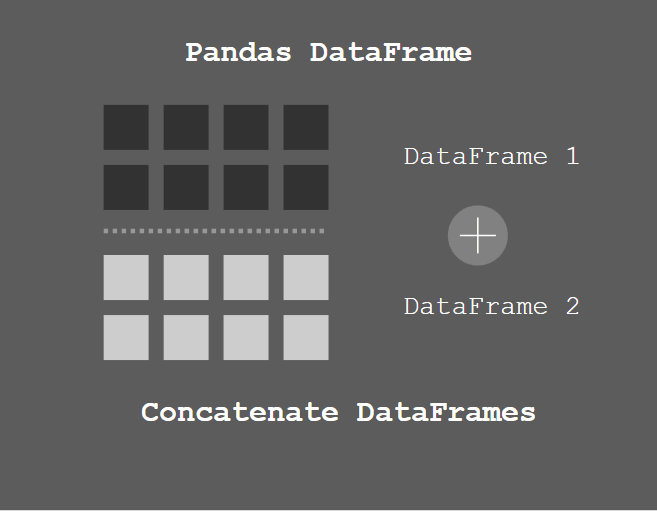
3.13.1. pandas.concat() 方法的语法
pandas.concat() 的语法是为:
pandas.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, sort=None, copy=True)
3.13.2. 连接相似行的 DataFrame
在接下来的示例中,我们将使用 concat() 函数将两个具有同样列名的 DataFrame 连接起来。
import pandas as pd
df_1 = pd.DataFrame(
data=[
['Somu', 68, 84, 78, 96],
['Kiku', 74, 56, 88, 85],
['Ajit', 77, 73, 82, 87]
],
columns=['name', 'physics', 'chemistry', 'algebra', 'calculus']
)
df_2 = pd.DataFrame(
data=[
['Amol', 72, 67, 91, 83],
['Lini', 78, 69, 87, 92]
],
columns=['name', 'physics', 'chemistry', 'algebra', 'calculus']
)
frames = [df_1, df_2]
# concatenate dataframes
df = pd.concat(objs=frames, sort=False)
# print dataframe
print("df_1\n-------\n", df_1)
print("df_2\n-------\n", df_2)
print("df\n-------\n", df)
执行和输出:
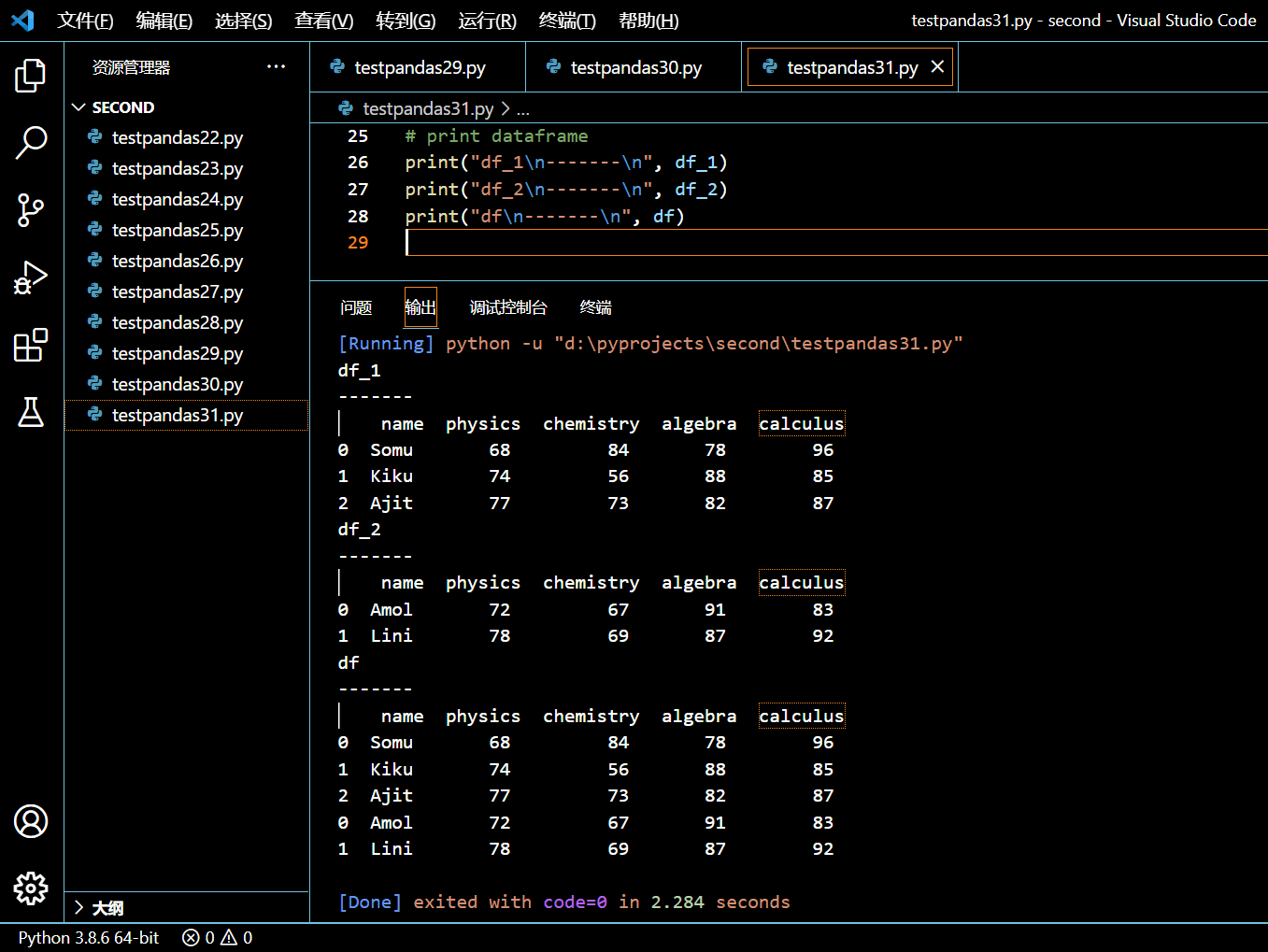
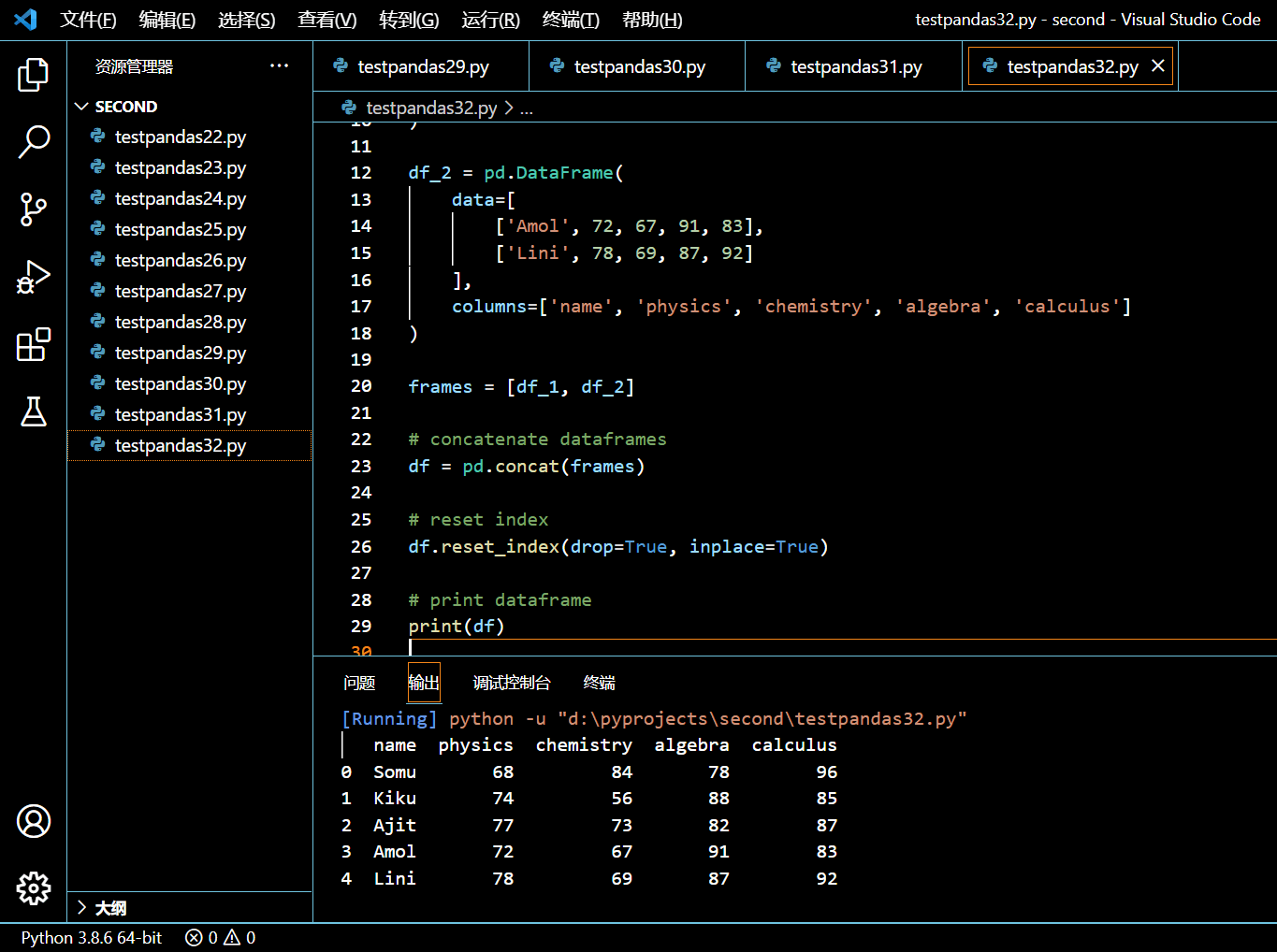
可见俩 DataFrame 被连起来了。但它的索引是无序的。你可以使用 reset_index() 函数对新索引进行重置。
import pandas as pd
df_1 = pd.DataFrame(
data=[
['Somu', 68, 84, 78, 96],
['Kiku', 74, 56, 88, 85],
['Ajit', 77, 73, 82, 87]
],
columns=['name', 'physics', 'chemistry', 'algebra', 'calculus']
)
df_2 = pd.DataFrame(
data=[
['Amol', 72, 67, 91, 83],
['Lini', 78, 69, 87, 92]
],
columns=['name', 'physics', 'chemistry', 'algebra', 'calculus']
)
frames = [df_1, df_2]
# concatenate dataframes
df = pd.concat(frames)
# reset index
df.reset_index(drop=True, inplace=True)
# print dataframe
print(df)
执行和输出:
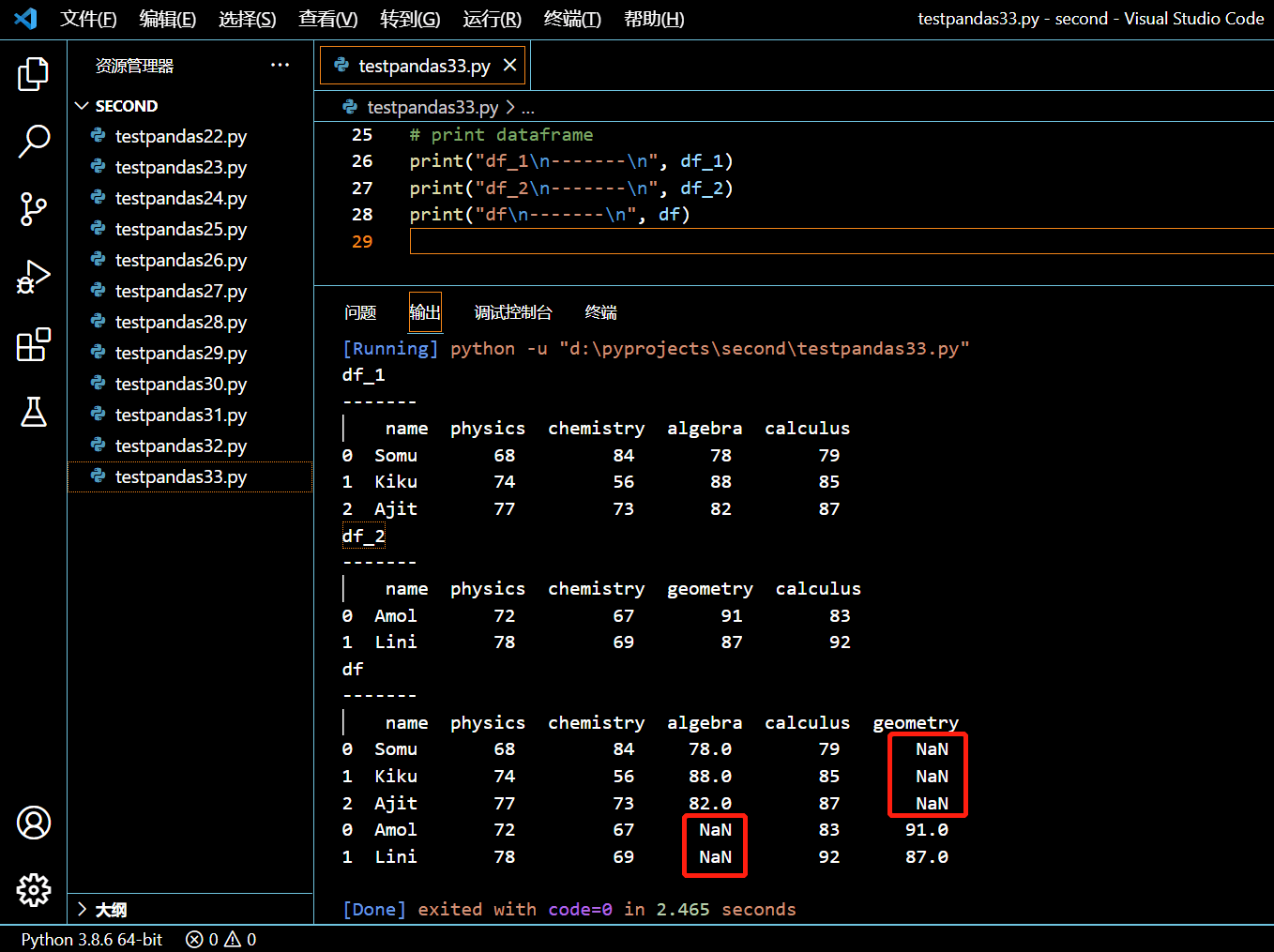
3.13.3. 连接具有不同列的俩 DataFrame
在接下来的示例中,我们将连接两个不同列的 DataFrame。两个 DataFrame 各自有一列数据不同于彼此,其他列一样。
pandas.concat() 函数将把俩 DataFrame 依据列名连起来形成一个新的 DataFrame。如果原来 DataFrame 中在新 DataFrame 中的某列中没有数据,那么新 DataFrame 中会将其以 NaN 填充。
import pandas as pd
df_1 = pd.DataFrame(
data=[
['Somu', 68, 84, 78, 79],
['Kiku', 74, 56, 88, 85],
['Ajit', 77, 73, 82, 87]
],
columns=['name', 'physics', 'chemistry', 'algebra', 'calculus']
)
df_2 = pd.DataFrame(
data=[
['Amol', 72, 67, 91, 83],
['Lini', 78, 69, 87, 92]
],
columns=['name', 'physics', 'chemistry', 'geometry', 'calculus']
)
frames = [df_1, df_2]
# concatenate dataframes
df = pd.concat(frames, sort=False)
# print dataframe
print("df_1\n-------\n", df_1)
print("df_2\n-------\n", df_2)
print("df\n-------\n", df)
执行和输出:
3.13.4. 小结
通过本节示例,我们了解到了如何将两个或多个 DataFrame 连接成一个新的 DataFrame。
3.14. 如何进行 DataFrame 的追加?
pandas.DataFrame.append() 函数将新建一个 DataFrame,该 DataFrame 中,第二个 DataFrame 中的行将被放在调用者 DataFrame 的后面。注意,本方法返回的是一个新的 DataFrame,append() 函数的调用 DataFrame 和被调用 DataFrame 的内容不会变动。
3.14.1. DataFrame 数据追加
在接下来的示例中,我们将创建两个 DataFrame,并且将第二个的数据追加到第二个。
import pandas as pd
df_1 = pd.DataFrame(
data=[
['Somu', 64, 88, 73, 43],
['Kiku', 73, 87, 63, 99],
['Ajit', 77, 73, 78, 69]
],
columns=['name', 'physics', 'chemistry', 'algebra', 'calculus']
)
df_2 = pd.DataFrame(
data=[
['Amol', 72, 67, 88, 73],
['Lini', 78, 84, 93, 72]
],
columns=['name', 'physics', 'chemistry', 'algebra', 'calculus']
)
frames = [df_1, df_2]
# append dataframes
df = df_1.append(other=df_2, ignore_index=False)
# print dataframe
print("df_1\n-------\n", df_1)
print("\ndf_2\n-------\n", df_2)
print("\ndf\n-------\n", df)
执行和输出:
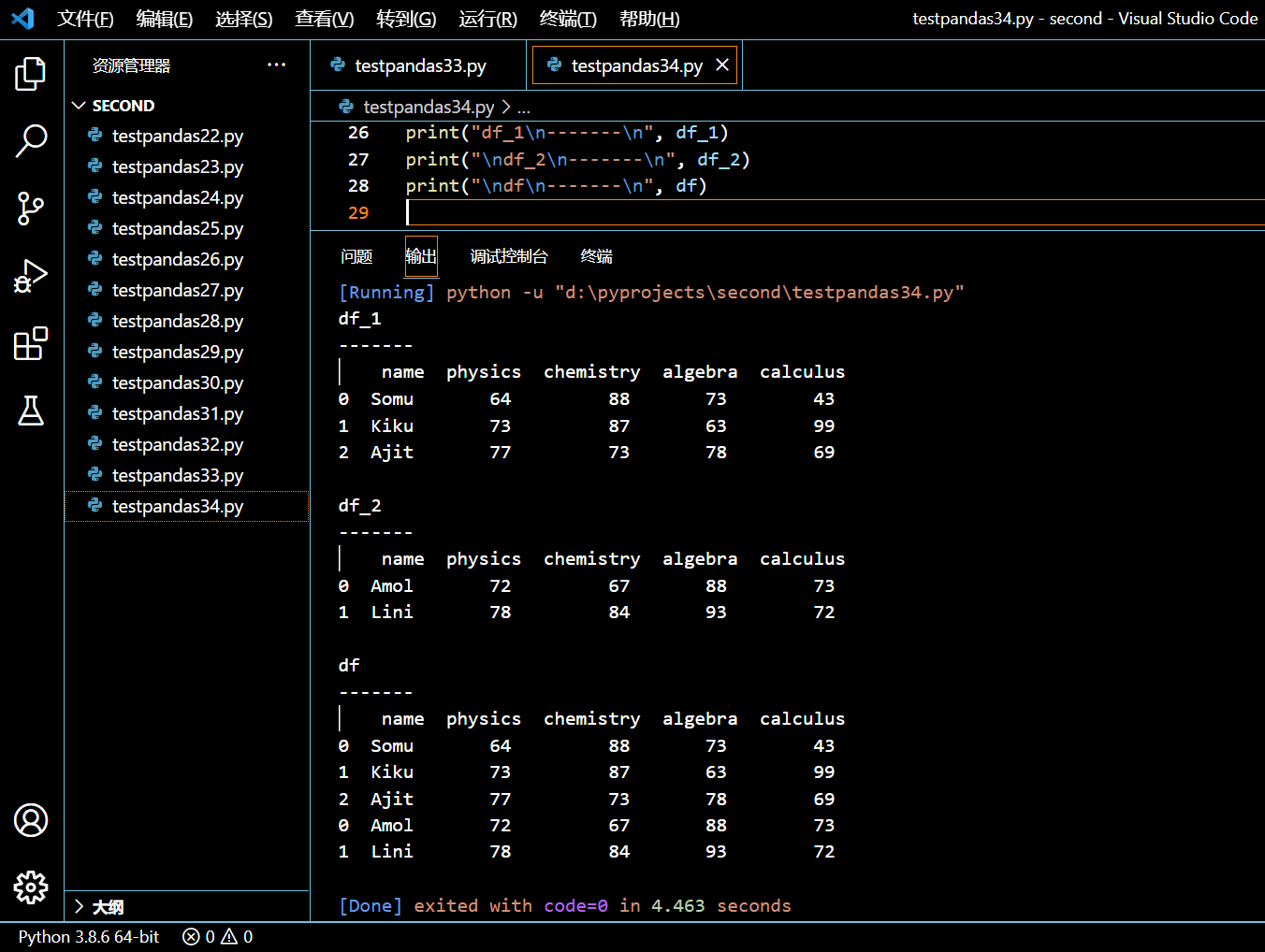
可见,df_1 和 df_2 都没有受到影响,append 函数只是将追加后的 DataFrame 返回给调用方而已。另外我们将 ignore_index=False 传给 append,这将保留原来的索引。如果我们传递 ignore_index=Ture,那么新的输出将会是(注意查看索引列,与上图进行对比):
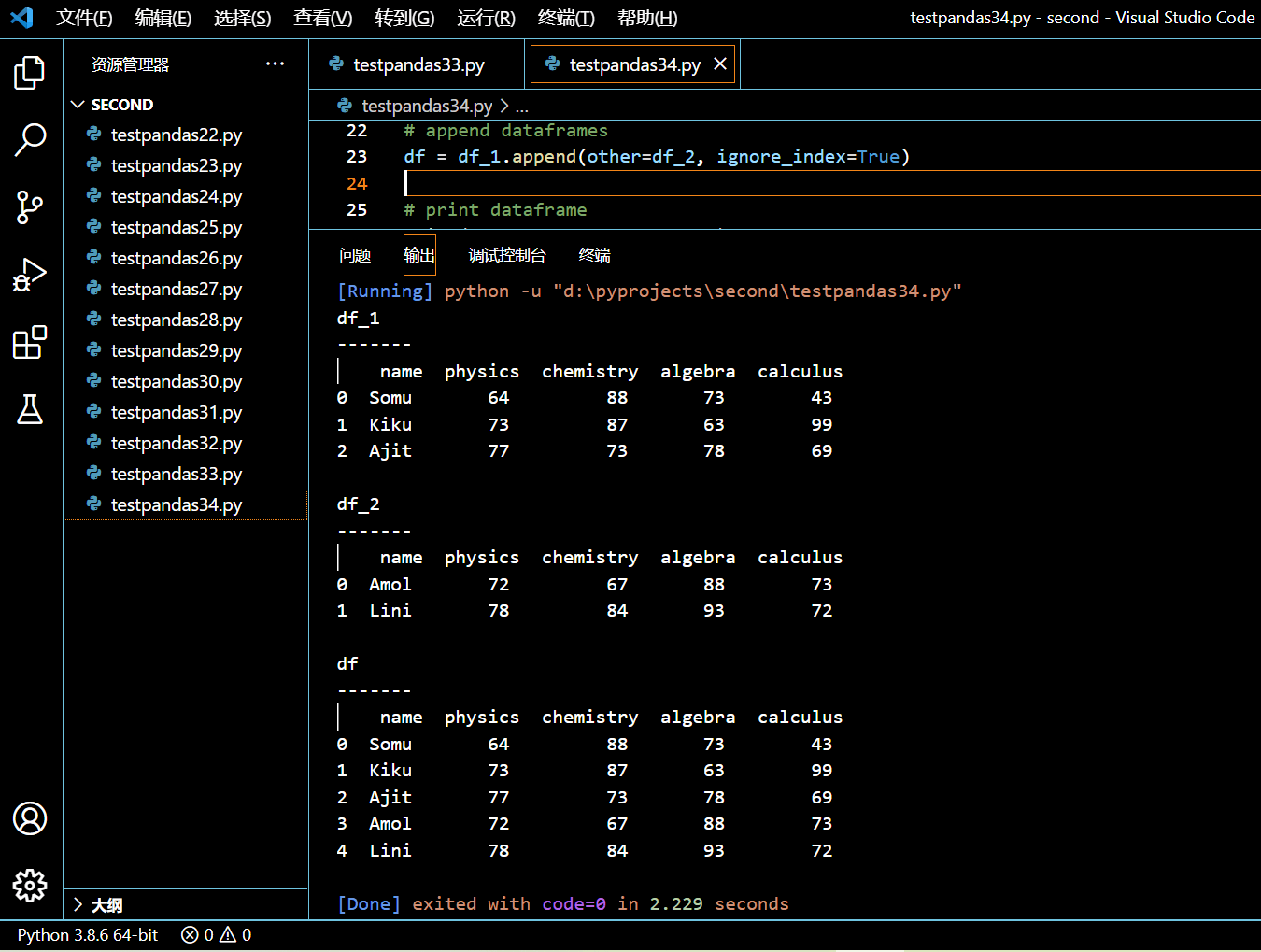
3.14.2. 追加有不同列的 DataFrame
接下来,我们将对两个具有不同列的 DataFrame 进行追加。
import pandas as pd
df_1 = pd.DataFrame(
data=[
['Somu', 68, 84, 78, 96],
['Kiku', 74, 56, 88, 85],
['Ajit', 77, 73, 82, 87]
],
columns=['name', 'physics', 'chemistry', 'algebra', 'calculus']
)
df_2 = pd.DataFrame(
data=[
['Amol', 72, 67, 91, 83],
['Lini', 78, 69, 87, 92]
],
columns=['name', 'physics', 'chemistry', 'science', 'calculus']
)
# append the dataframes
df = df_1.append(other=df_2, ignore_index=True, sort=False)
# print dataframe
print("df_1\n-------\n", df_1)
print("\ndf_2\n-------\n", df_2)
print("\ndf-------\n", df)
执行和输出:
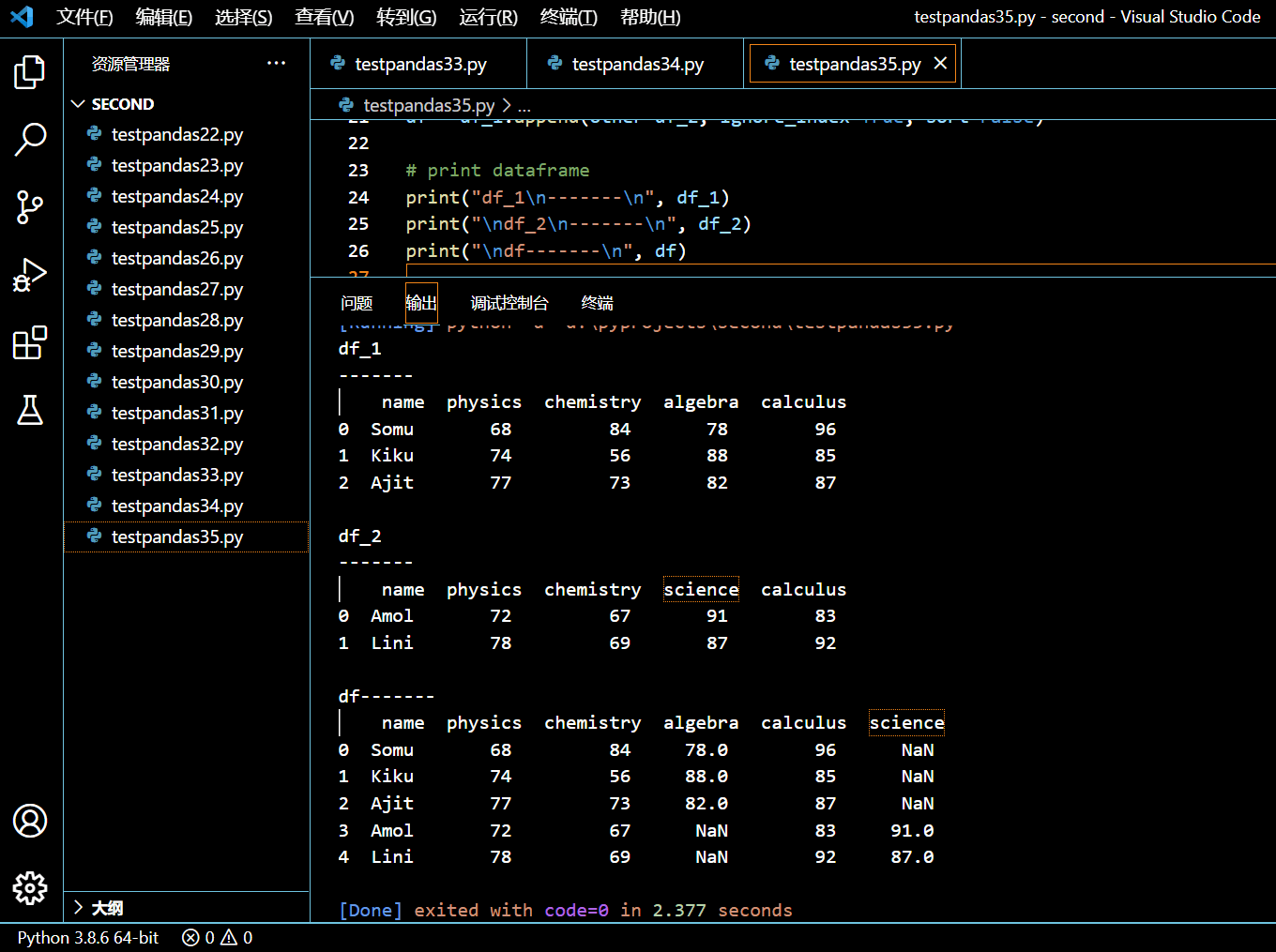
类似于 concatenate 函数,有不同列,空值置为 NaN,非空值置为浮点型。
3.14.3. 小结
通过本节的学习我们了解了如何通过 append() 方法对 DataFrame 进行追加。
3.15. 如何对 Pandas DataFrame 里的数据进行查询?
可以使用 pandas.DataFrame.query() 方法来根据列的有关条件查询 DataFrame 的相关行。
默认情况下,query() 函数将返回一个包含有过滤行的 DataFrame。你也可以传递 inplace=True 参数给该函数以修改原始 DataFrame。
3.15.1. 根据单列条件查询 DataFrame
本示例中,我们将查询满足布尔表达式过滤后的行所组成的 DataFrame。
import pandas as pd
# initialize a dataframe
df = pd.DataFrame(
data=[
[21, 72, 67],
[23, 78, 62],
[32, 74, 56],
[73, 88, 67],
[32, 74, 56],
[43, 78, 69],
[32, 74, 54],
[52, 54, 76]
],
columns=['a', 'b', 'c']
)
# query single column
df1 = df.query('a > 50')
# print the dataframe
print("df\n-------\n", df)
print("\ndf1\n-------\n", df1)
执行和输出:
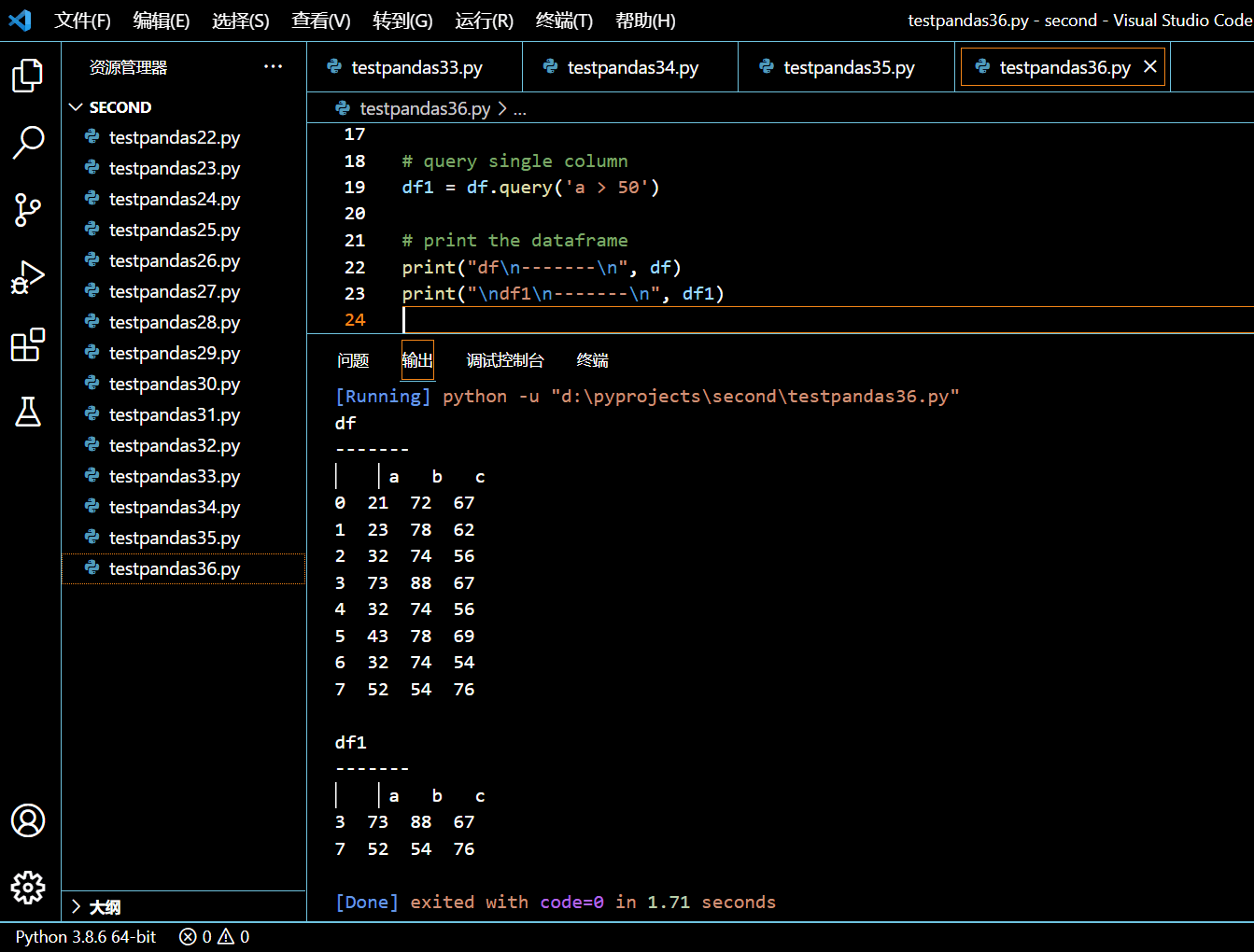
3.15.2. 使用 AND 操作符对 DataFrame 进行多列条件查询
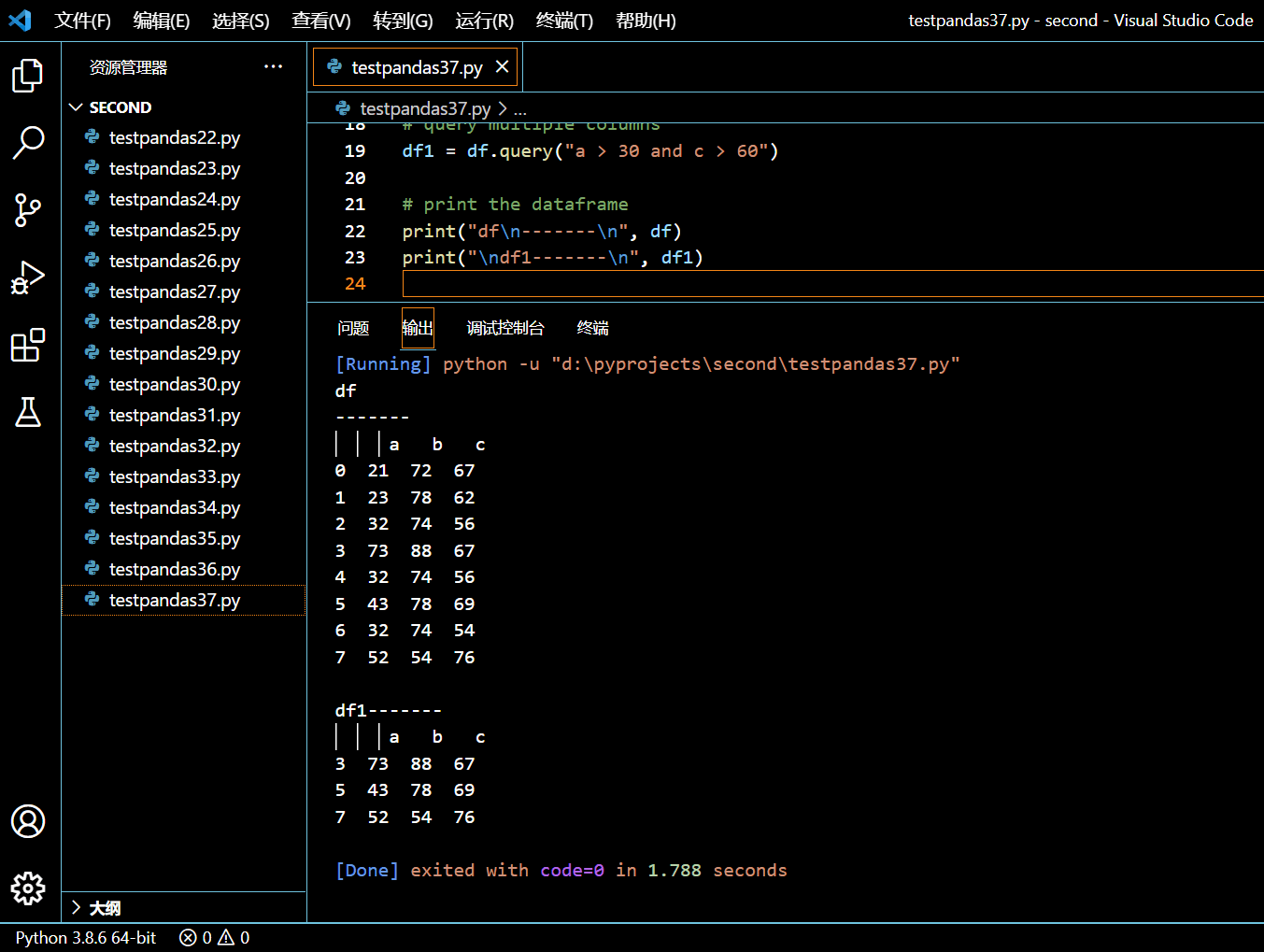
接下来的示例中,我们将使用 AND 操作符来进行多列条件查询。
import pandas as pd
# initialize a dataframe
df = pd.DataFrame(
data=[
[21, 72, 67],
[23, 78, 62],
[32, 74, 56],
[73, 88, 67],
[32, 74, 56],
[43, 78, 69],
[32, 74, 54],
[52, 54, 76]
],
columns=['a', 'b', 'c']
)
# query multiple columns
df1 = df.query("a > 30 and c > 60")
# print the dataframe
print("df\n-------\n", df)
print("\ndf1-------\n", df1)
执行和输出:
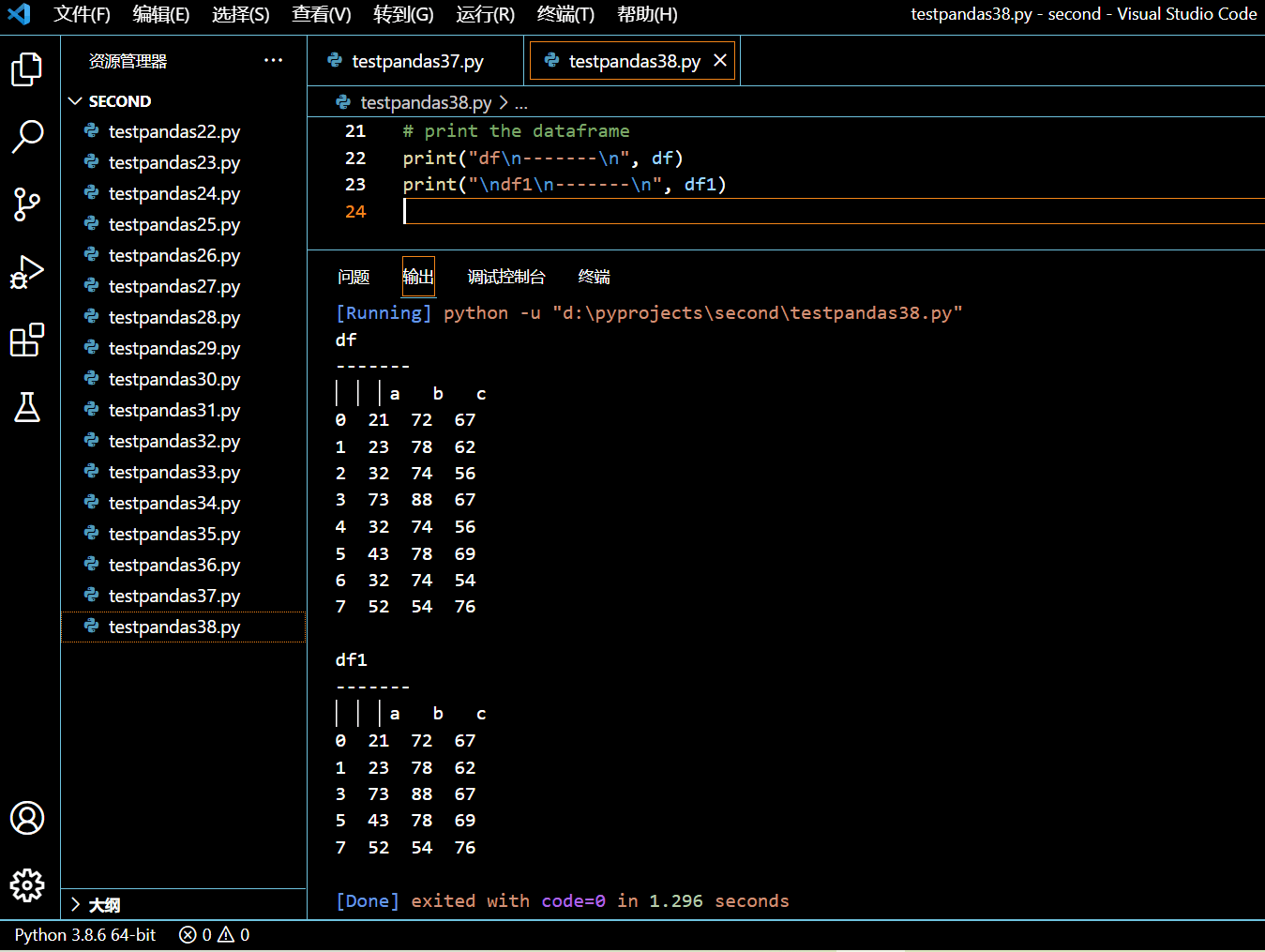
3.15.3. 使用 OR 操作符对 DataFrame 进行多列条件查询
在接下来的示例中,我们来尝试使用 OR 操作符进行多列条件检索。
import pandas as pd
# initialize a dataframe
df = pd.DataFrame(
data=[
[21, 72, 67],
[23, 78, 62],
[32, 74, 56],
[73, 88, 67],
[32, 74, 56],
[43, 78, 69],
[32, 74, 54],
[52, 54, 76]
],
columns=['a', 'b', 'c']
)
# query multiple columns
df1 = df.query('a > 50 or c > 60')
# print the dataframe
print("df\n-------\n", df)
print("\ndf1\n-------\n", df1)
执行和输出:
3.15.4. 查询时使用 inplace 参数
我们可以传递 inplace=True 参数来修改当前正在查询的 DataFrame。
import pandas as pd
# initialize a dataframe
df = pd.DataFrame(
data=[
[21, 72, 67],
[23, 78, 62],
[32, 74, 56],
[73, 88, 67],
[32, 74, 56],
[43, 78, 69],
[32, 74, 54],
[52, 54, 76]
],
columns=['a', 'b', 'c']
)
print("df init as:\n", df)
# query dataframe with inplace true
df.query("a > 50 and c > 60", inplace=True)
print("\ndf after inplace:\n", df)
执行和输出:
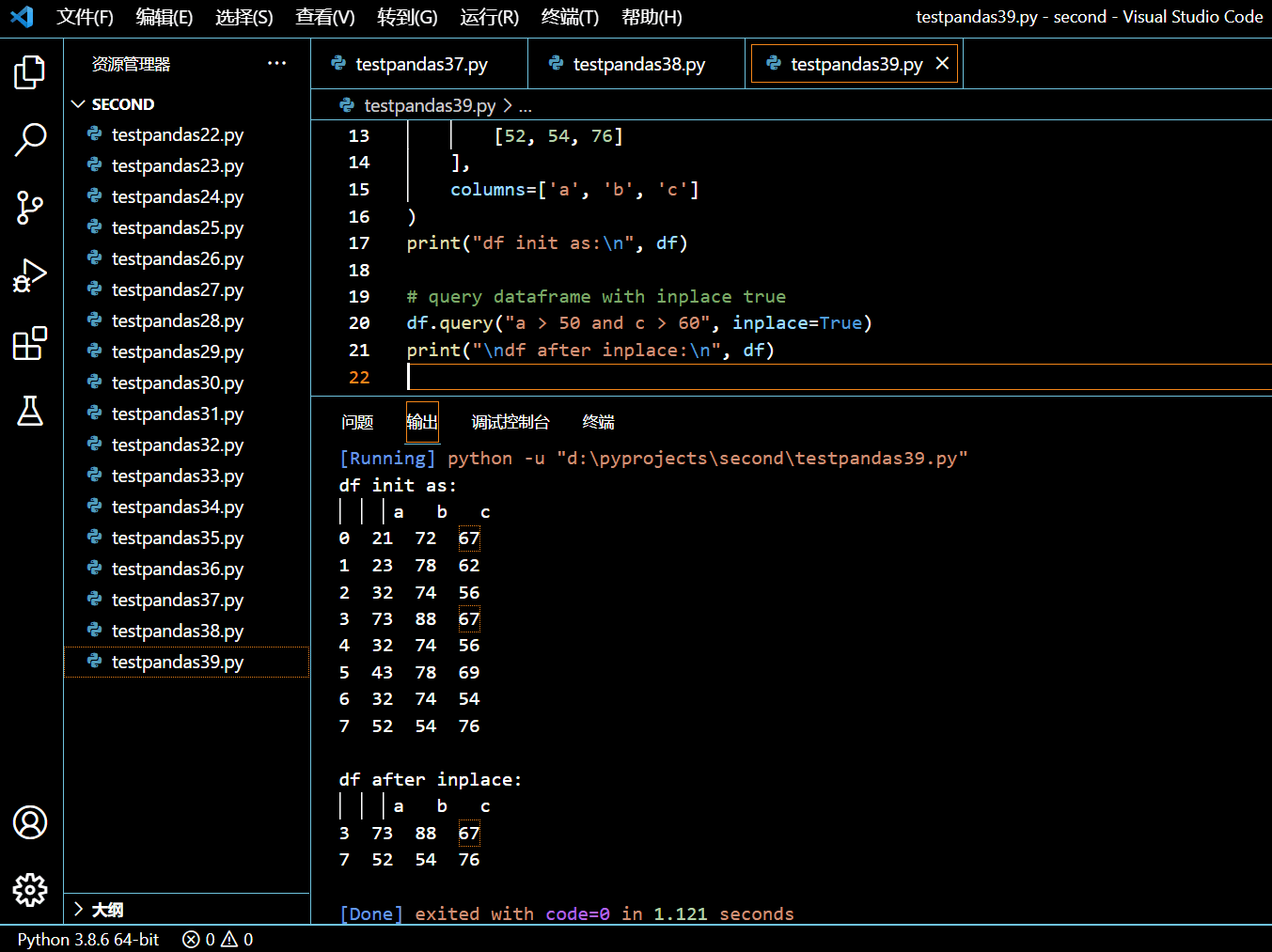
可见,inplace 参数的作用是把不符合条件的过滤掉,留下的是符合条件的。
3.15.5. 小结
本节我们了解到了如何对 DataFrame 进行按列条件查询。
3.16. 如何重置 Pandas DataFrame 的索引?
在你对 DataFrame 进行连接、排序、追加或重新排列时,它的索引将被打乱或无序。
可以使用 pandas.DataFrame.reset_index() 方法对 DataFrame 的索引进行重置。
3.16.1. reset_index() 的语法
DataFrame.reset_index() 函数的语法如下:
DataFrame.reset_index(level=None, drop=False, inplace=False, col_level=0, col_fill='')
要重置索引的话,需要传入参数 drop=True 和 inplace=True。
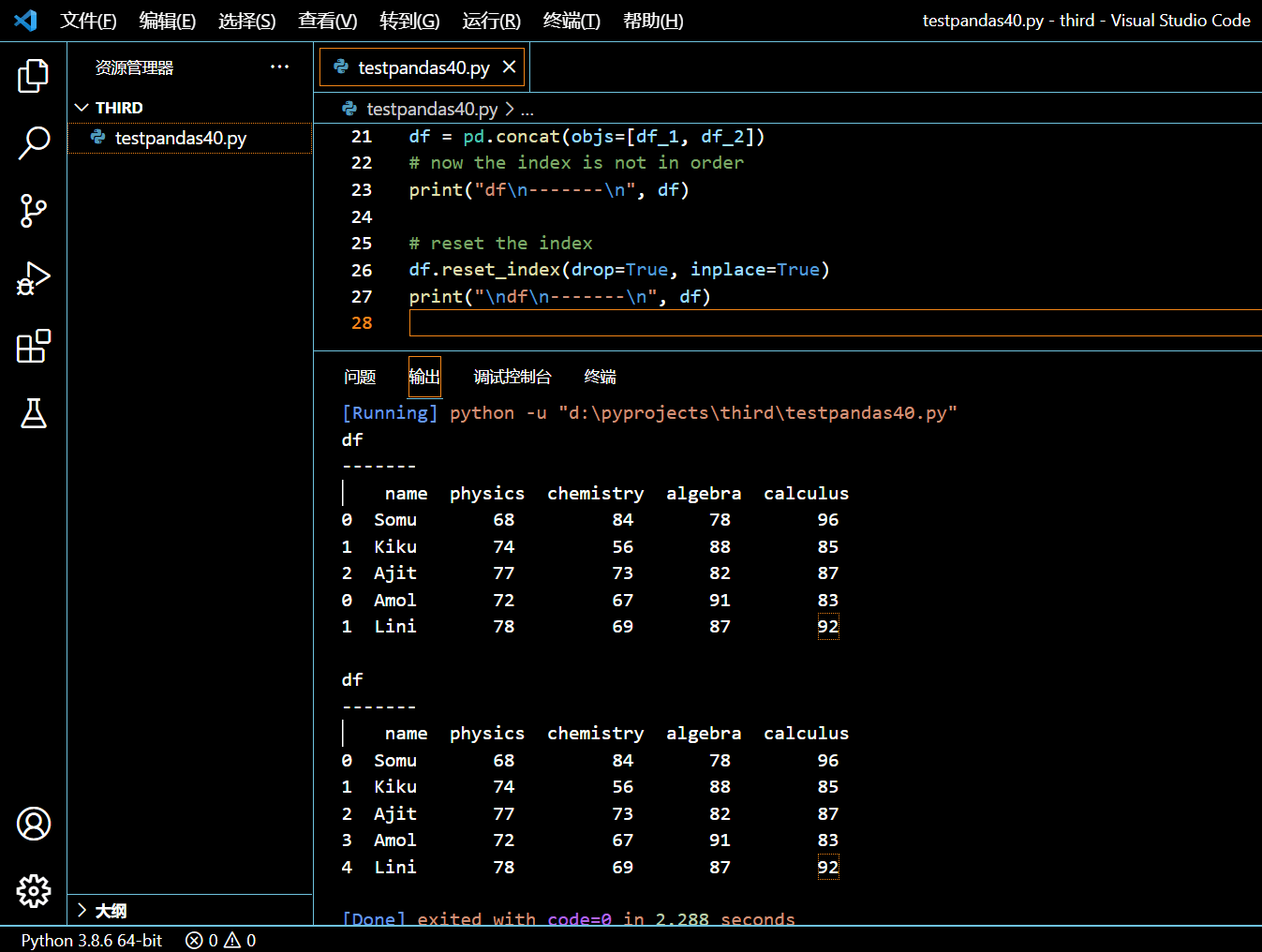
3.16.2. 使用 reset_index() 重置 DataFrame 的索引
本示例中,我们将连接两个 DataFrame,然后用 reset_index() 来将得到的 DataFrame 的索引进行重新排序。
import pandas as pd
df_1 = pd.DataFrame(
data=[
['Somu', 68, 84, 78, 96],
['Kiku', 74, 56, 88, 85],
['Ajit', 77, 73, 82, 87]
],
columns=['name', 'physics', 'chemistry', 'algebra', 'calculus']
)
df_2 = pd.DataFrame(
data=[
['Amol', 72, 67, 91, 83],
['Lini', 78, 69, 87, 92]
],
columns=['name', 'physics', 'chemistry', 'algebra', 'calculus']
)
# concatenate dataframes
df = pd.concat(objs=[df_1, df_2])
# now the index is not in order
print("df\n-------\n", df)
# reset the index
df.reset_index(drop=True, inplace=True)
print("\ndf\n-------\n", df)
执行和输出:
3.16.3. 使用 concat() 重置 DataFrame 索引
当然,你也可以使用 concat() 函数本身就可以重置索引。将 ignore_index=True 传给 concat() 函数即可,无需另外再调 reset_index()。
执行和输出:

此外,如果你只有一个 DataFrame 并且索引是乱的,你可以只将该 DataFrame 传给 concat() 函数的列表参数,进行索引重置。
import pandas as pd
df_1 = pd.DataFrame(
data=[
['Somu', 68, 84, 78, 96],
['Kiku', 74, 56, 88, 85],
['Ajit', 77, 73, 82, 87]
],
columns=['name', 'physics', 'chemistry', 'algebra', 'calculus']
)
df_2 = pd.DataFrame(
data=[
['Amol', 72, 67, 91, 83],
['Lini', 78, 69, 87, 92]
],
columns=['name', 'physics', 'chemistry', 'algebra', 'calculus']
)
# concatenate
df = pd.concat([df_1, df_2])
# now the index is not in order
print("df after first concat:\n", df)
# reset the index
df = pd.concat([df], ignore_index=True)
print("df after second concat:\n", df)
执行和输出:
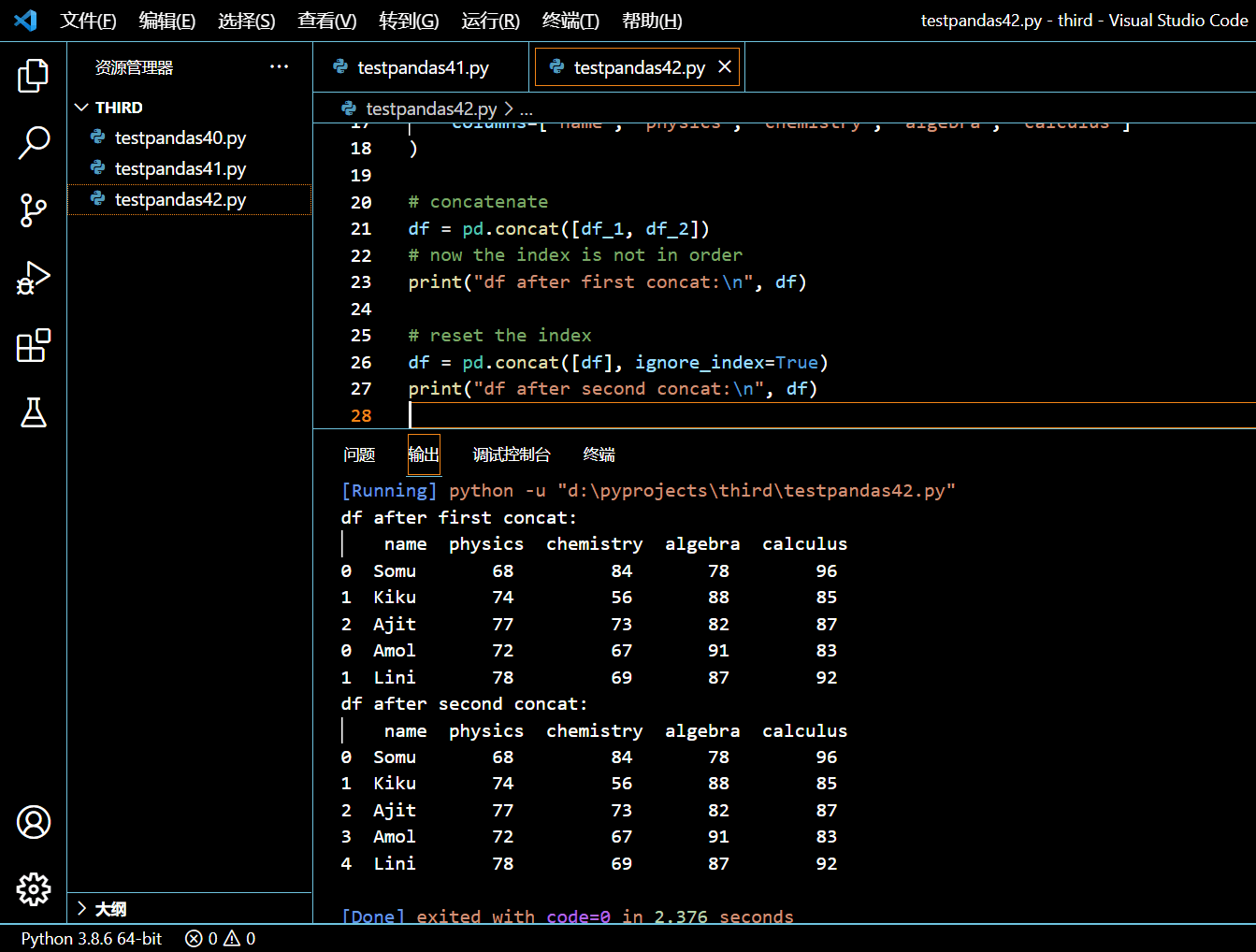
可见两次 concat 起的作用其实都是连接,不同的是第二次是自己连自己,而且赋予了 ignore_index 参数。
3.16.4. 小结
本节我们了解到了如何重置 Pandas DataFrame 的索引。
3.17. 如何将 Pandas DataFrame 翻译成 HTML 表格?
你可以将 DataFrame 转换为 HTML 里的表格,这样可以在 web 页面里展现 DataFrame。
要将 Pandas DataFrame 翻译为 HTML 表格,可以使用 pandas.DataFrame.to_html() 方法。
整个 DataFrame 都被转换为 html 的
3.17.1. 将 DataFrame 翻译成 HTML 表格
本示例中,我们将初始化一个 DataFrame 并将其翻译成 HTML 表格。
import pandas as pd
# create dataframe
df_marks = pd.DataFrame(
{
'name': ['Somu', 'Kiku', 'Amol', 'Lini'],
'physics': [68, 74, 77, 78],
'chemistry': [84, 56, 73, 69],
'algebra': [78, 88, 82, 87]
}
)
# render dataframe as html
html = df_marks.to_html()
print(html)
执行后控制台输出结果如下:
<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th></th>
<th>name</th>
<th>physics</th>
<th>chemistry</th>
<th>algebra</th>
</tr>
</thead>
<tbody>
<tr>
<th>0</th>
<td>Somu</td>
<td>68</td>
<td>84</td>
<td>78</td>
</tr>
<tr>
<th>1</th>
<td>Kiku</td>
<td>74</td>
<td>56</td>
<td>88</td>
</tr>
<tr>
<th>2</th>
<td>Amol</td>
<td>77</td>
<td>73</td>
<td>82</td>
</tr>
<tr>
<th>3</th>
<td>Lini</td>
<td>78</td>
<td>69</td>
<td>87</td>
</tr>
</tbody>
</table>
接下来我们将这些 html 数据写入一个文件中:
import pandas as pd
# create dataframe
df_marks = pd.DataFrame(
{
'name': ['Somu', 'Kiku', 'Amol', 'Lini'],
'physics': [68, 74, 77, 78],
'chemistry': [84, 56, 73, 69],
'algebra': [78, 88, 82, 87]
}
)
# render dataframe as html
html = df_marks.to_html()
# write html to file
text_file = open(file="index.html", mode="W")
text_file.write(html)
text_file.close
执行这个程序,index.html 将会在当前程序工作目录下生成。
打开生成的 html 文件:
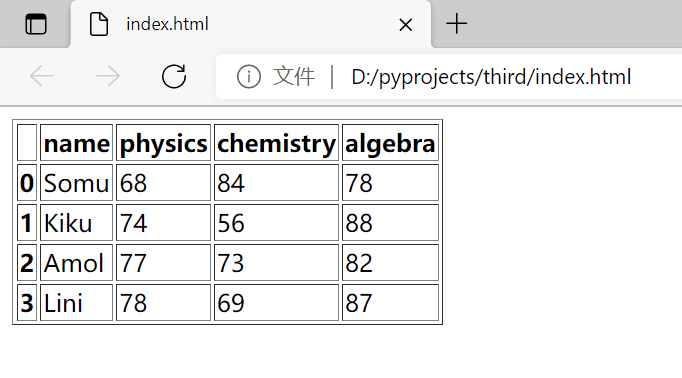
3.17.2. 小结
本节我们了解了如何将一个 Pandas DataFrame 翻译/转换成一个 HTML 表格。
3.18. 如何将 Pandas DataFrame 写到 Excel 表格?
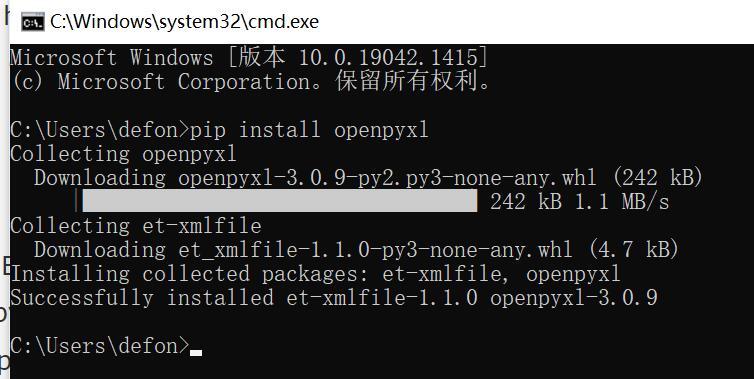
可以用 pandas.DataFrame.to_excel() 方法将 DataFrame 写入 excel 文件。
使用该方法的前提条件是你已安装了 openpyxl 模块。可以使用 pip 命令来安装 openpyxl:
pip install openpyxl
3.18.1. 将 DataFrame 写入 Excel 文件
你可以在不提及任何 sheet 名称的情况下将 DataFrame 写入 Excel 文件。执行步骤如下:
- 准备好 DataFrame。本示例中我们将初始化一个拥有多行多列的 DataFrame。
- 使用目标 excel 文件名创建一个 excel writer。
- 调用 DataFrame 的 to_excel() 函数并将 excel writer 作为参数传递给它。
- 使用 excel writer 的 save() 方法保存 excel 文件。
import pandas as pd
# create dataframe
df_marks = pd.DataFrame(
{
'name': ['Somu', 'Kiku', 'Amol', 'Lini'],
'physics': [68, 74, 77, 78],
'chemistry': [84, 56, 73, 69],
'algebra': [78, 88, 82, 87]
}
)
# create excel writer object
writer = pd.ExcelWriter('output.xlsx')
# write dataframe to excel
df_marks.to_excel(excel_writer=writer)
# save the excel
writer.save()
print('Dataframe is written successfully to excel file.')
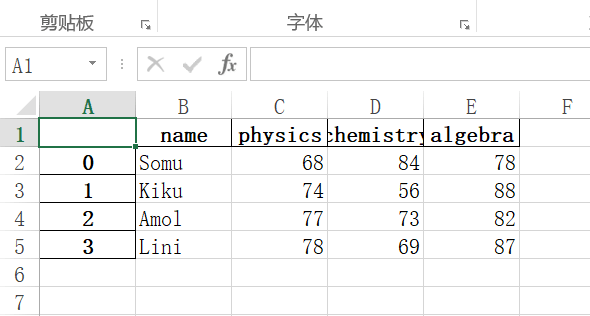
执行以上程序,一个 excel 文件将被在程序工作目录下创建。
打开该 excel 文件,你会发现索引、列名、行数据都已被写入文件:
3.18.2. 将 DataFrame 写入指定 excel sheet 中
通过以下步骤将 DataFrame 写到指定 excel sheet 中:
- 准备好你的 DataFrame。
- 使用目标输出 excel 文件名创建一个 excel writer。
- 调用该 DataFrame 的 to_excel() 函数,并将 writer 以及指定的 excel sheet 名作为参数传给它。
- 使用 excel writer 的 save() 方法保存该 excel 文件。
import pandas as pd
# create dataframe
df_marks = pd.DataFrame(
data={
'name': ['Somu', 'Kiku', 'Amol', 'Lini'],
'physics': [68, 74, 77, 78],
'chemistry': [84, 56, 73, 69],
'algebra': [78, 88, 82, 87]
}
)
# create excel writer
writer = pd.ExcelWriter("output2.xlsx")
# write dataframe to excel sheet named 'marks'
df_marks.to_excel(excel_writer=writer, sheet_name="marks")
# save the excel file
writer.save()
print("Dataframe is written successfully to excel file")
执行该程序后在程序工作目录下发现了新生成的 output2.xlsx,打开该文件,注意观察 sheet 名,它已被命名为我们传递给 to_excel() 函数的 sheet_name 参数的值:
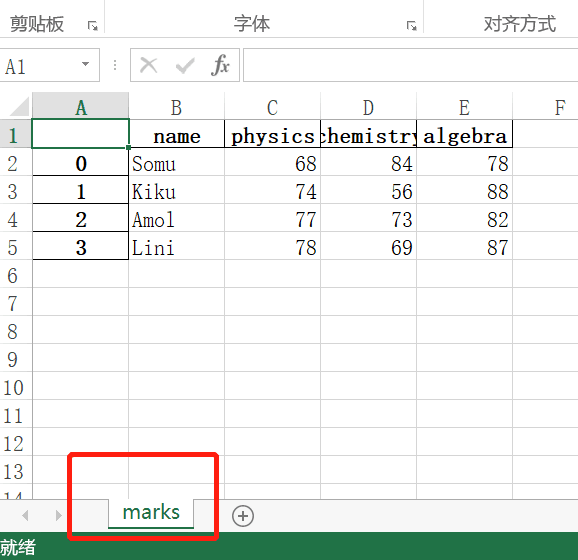
3.18.3. 小结
本节我们了解掌握了怎样将一个 Pandas DataFrame 写入到 excel 表格中。
3.19. 最大值 - max() 函数
要找到一个 Panda DataFrame 里的最大值,可以使用 pandas.DataFrame.max() 方法。通过该方法,你可以找到基于 axis 的最大值:按行或按列、或者整个 DataFrame 的最大值。
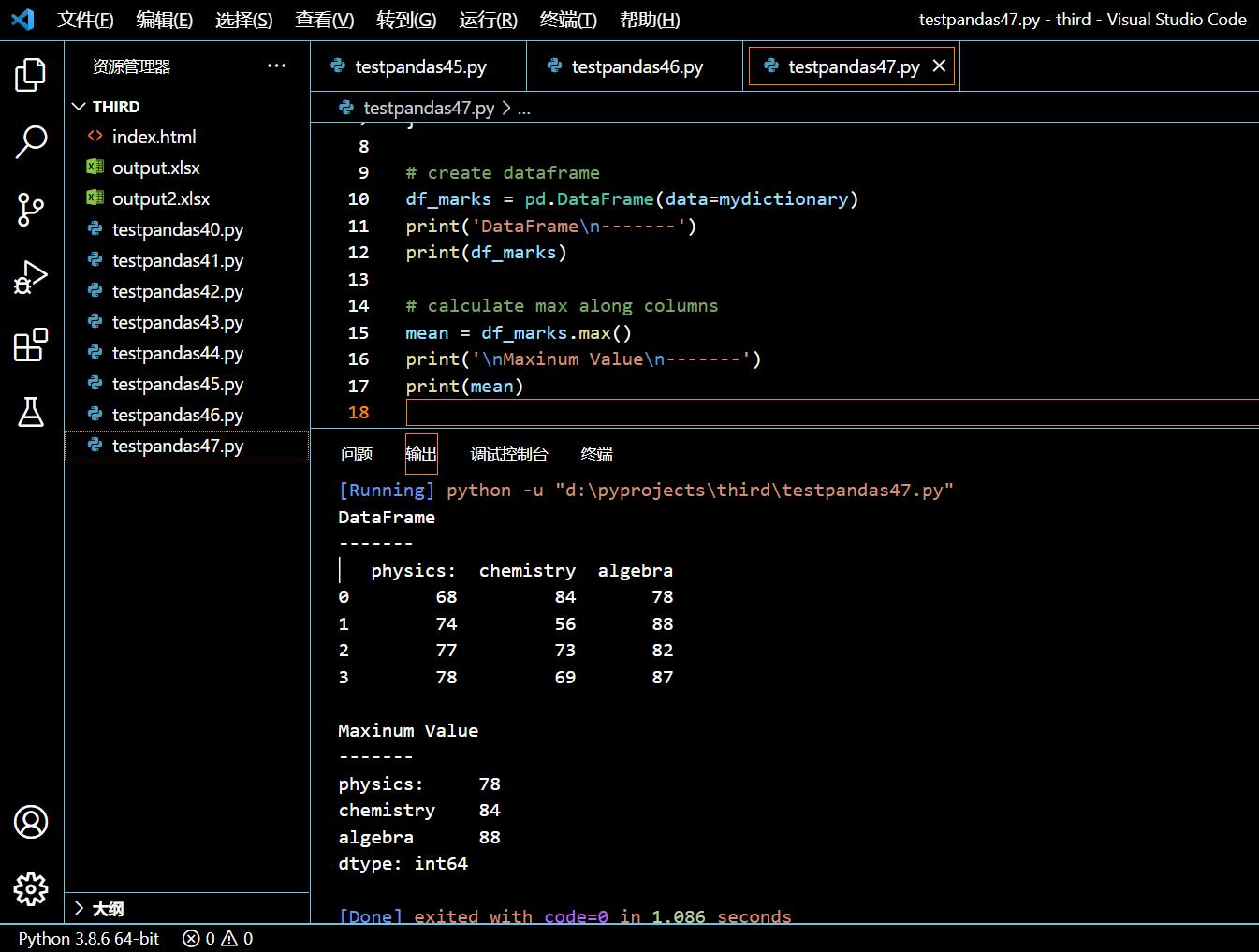
3.19.1. 找出 DataFrame 每列的最大值
本示例中,我们将计算出每一列的最大值。我们将了解学生们每一科的最高分。
import pandas as pd
mydictionary = {
'physics:': [68, 74, 77, 78],
'chemistry': [84, 56, 73, 69],
'algebra': [78, 88, 82, 87]
}
# create dataframe
df_marks = pd.DataFrame(data=mydictionary)
print('DataFrame\n-------')
print(df_marks)
# calculate max along columns
mean = df_marks.max()
print('\nMaxinum Value\n-------')
print(mean)
执行和输出:
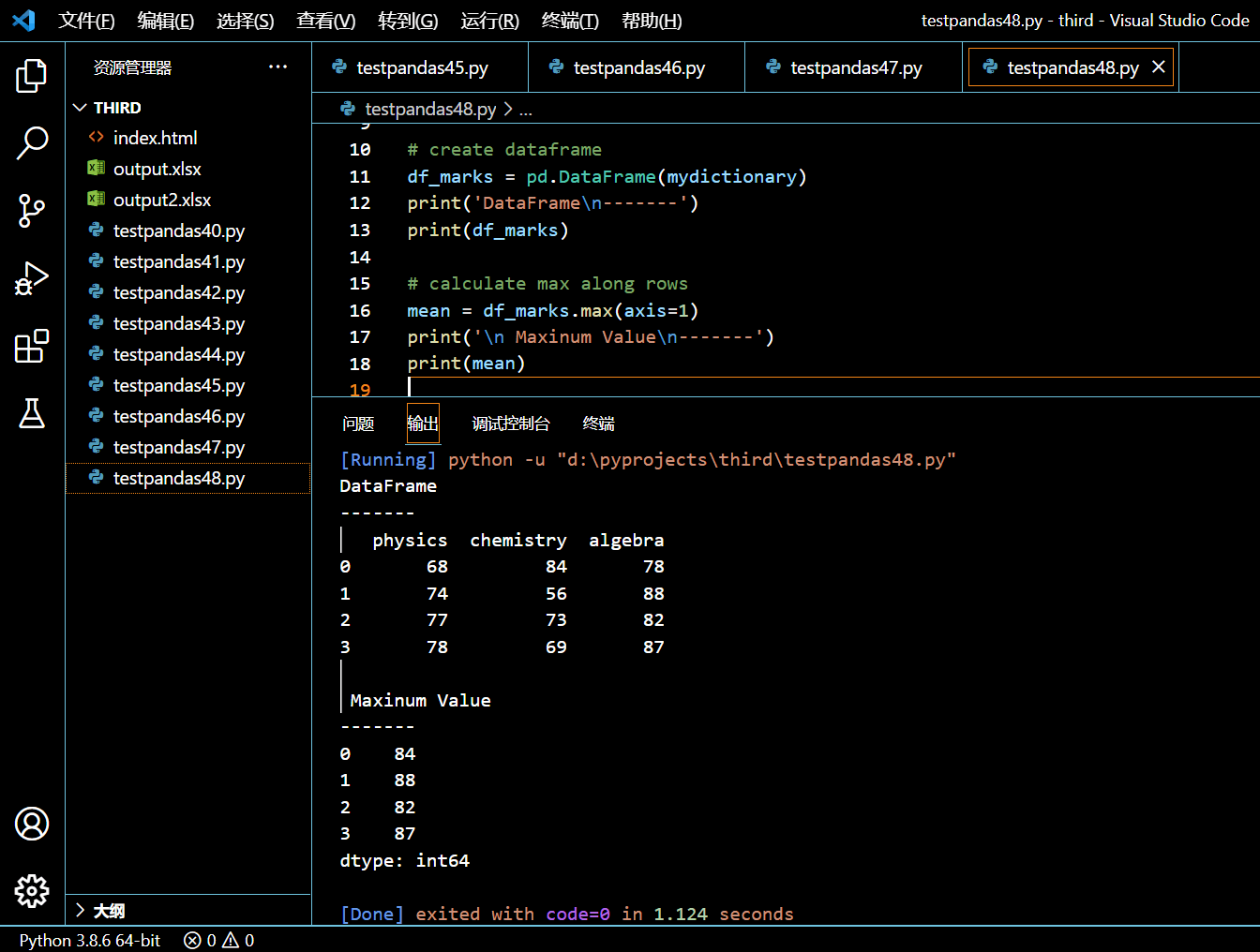
3.19.2. 根据行找到最大值
在接下来的示例中,我们将根据行找到 DataFrame 的每行的最大值。这意味着统计某同学个人在所有科目中的最高分。
import pandas as pd
mydictionary = {
'physics': [68, 74, 77, 78],
'chemistry': [84, 56, 73, 69],
'algebra': [78, 88, 82, 87]
}
# create dataframe
df_marks = pd.DataFrame(mydictionary)
print('DataFrame\n-------')
print(df_marks)
# calculate max along rows
mean = df_marks.max(axis=1)
print('\n Maxinum Value\n-------')
print(mean)
执行和输出:
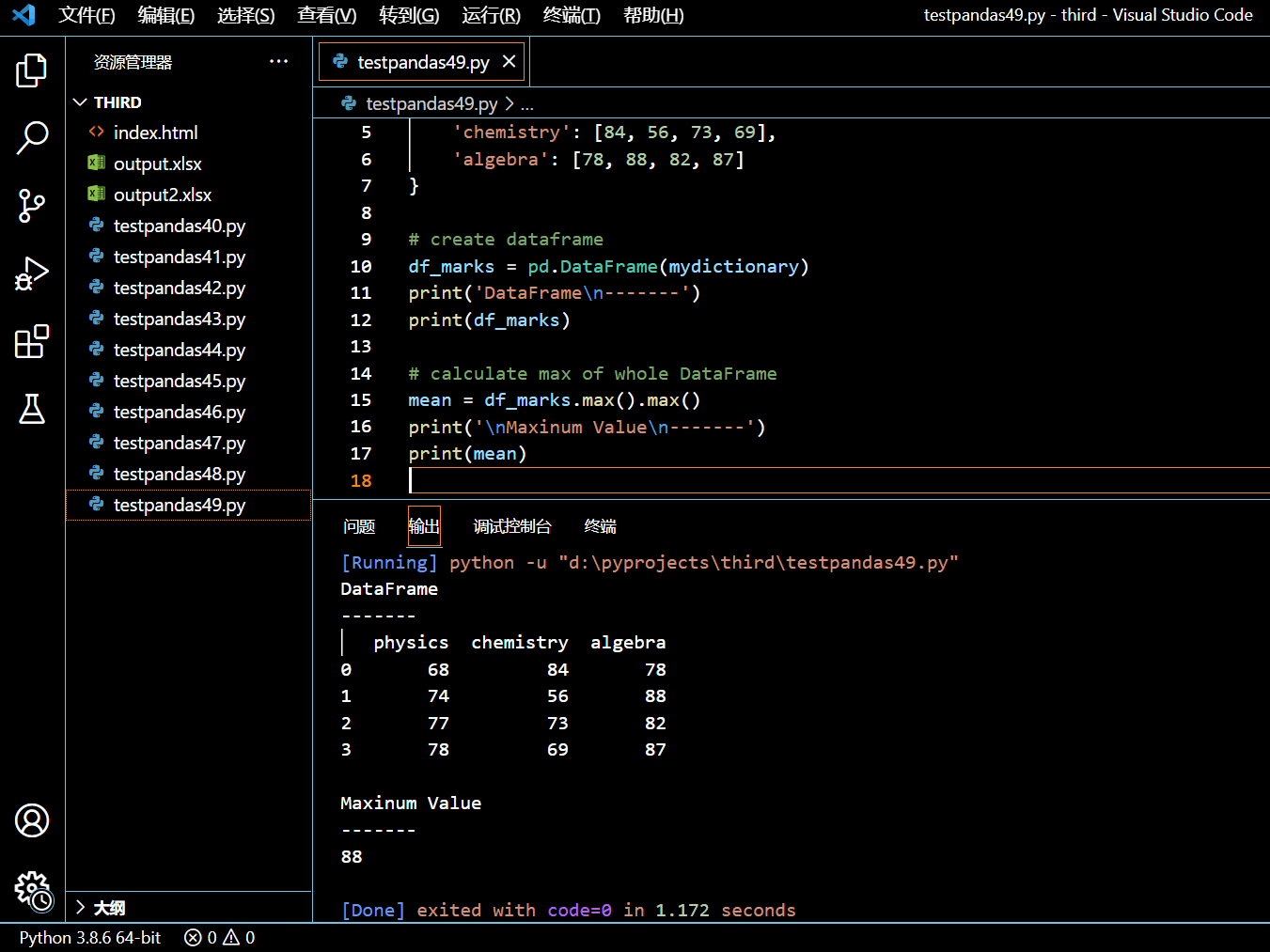
3.19.3. 整个 DataFrame 的最大值
在接下来的示例中,我们将找出整个 DataFrame 里的最大值,跟行或列无关。
在之前的示例中,我们分别找到了每行或每列的最大值。那么将 max() 函数提供给以上示例中 max() 函数的结果后,我们将得到整个 DataFrame 的最大值。
import pandas as pd
mydictionary = {
'physics': [68, 74, 77, 78],
'chemistry': [84, 56, 73, 69],
'algebra': [78, 88, 82, 87]
}
# create dataframe
df_marks = pd.DataFrame(mydictionary)
print('DataFrame\n-------')
print(df_marks)
# calculate max of whole DataFrame
mean = df_marks.max().max()
print('\nMaxinum Value\n-------')
print(mean)
执行和输出:
3.19.4. 小结
在本节中,我们了解到了如何拿到整个 DataFrame 里的最大值、拿到每一列的最大值、拿到每一行的最大值。
3.20. 如何拿到 Pandas DataFrame 的平均值?
要计算一个 Pandas DataFrame 的平均值,你可以使用 pandas.DataFrame.mean() 方法。通过 mean() 方法,你可以计算基于 axis,或者整个 DataFrame 的平均值。
3.20.1. DataFrame 每一列的平均值
本示例中,我们将计算每一列的平均值。也就是说我们要了解到每个学生所有科目的平均值。
import pandas as pd
mydictionary = {
'names': ['Somu', 'Kiku', 'Amol', 'Lini'],
'physics': [68, 74, 77, 78],
'chemistry': [84, 56, 73, 69],
'algebra': [78, 88, 82, 87]
}
# create dataframe
df_marks = pd.DataFrame(mydictionary)
print('DataFrame\n-------')
print(df_marks)
# calculate mean
mean = df_marks.mean()
print('\nMean\n-------')
print(mean)
执行和输出:
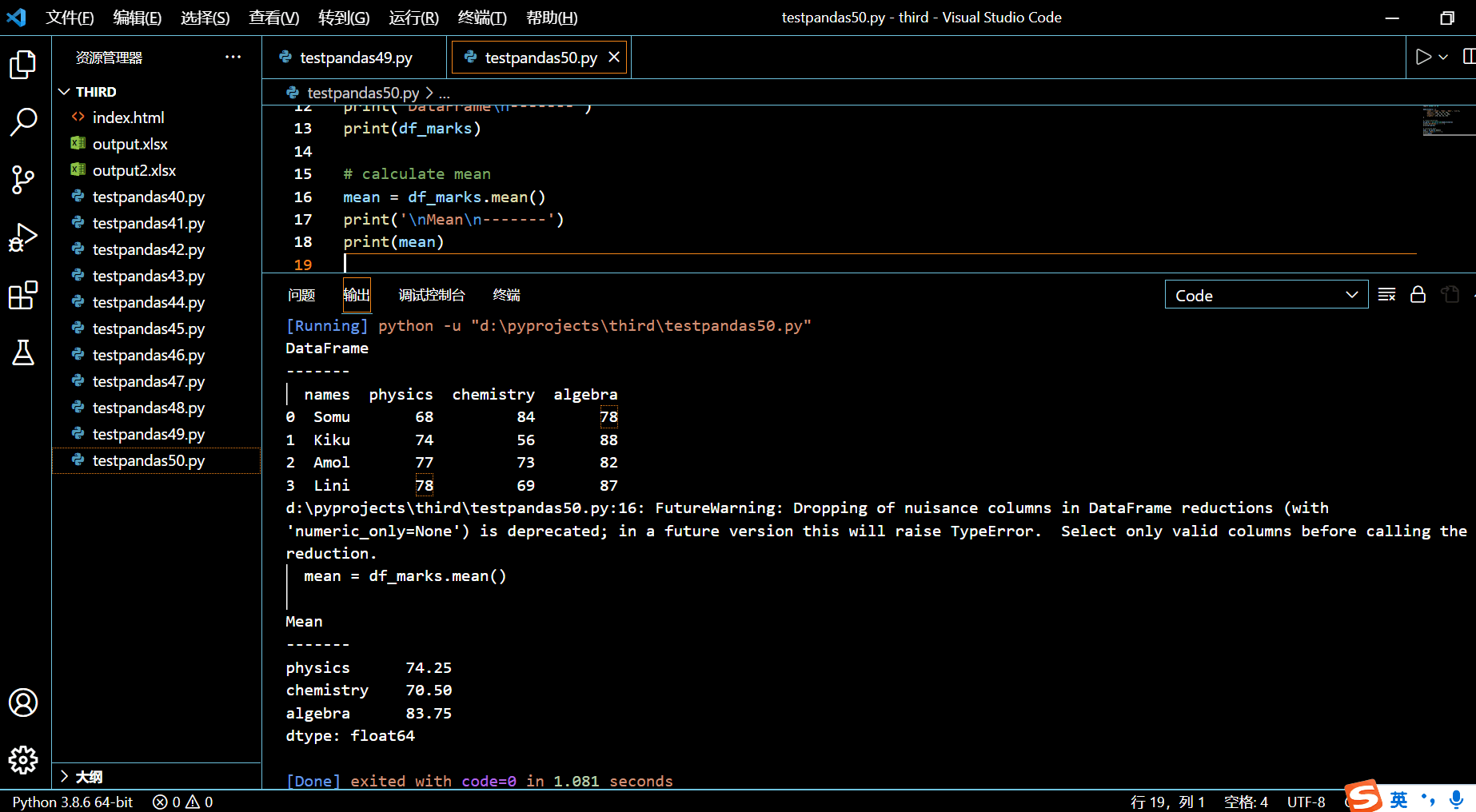
mean() 返回一个 Pandas Series。这是 mean() 函数的默认行为。对于这种情况,无需传递任何参数给 mean() 函数。或者你也可以显式传递 axis=0 给 mean() 以要求按列计算:
df_marks.mean(axis=0)
3.20.2. DataFrame 每一列的平均值
在接下来的示例中,我们将来计算整个 DataFrame 里数字的平均值。
在前面的示例中,我们看到了 mean() 函数默认返回每一列的平均值并返回一个 Pandas Series。继续调用返回 Series 的 mean(),然后就可以得到整个 DataFrame 的平均值了。
import pandas as pd
mydictionary = {
'names': ['Somu', 'Kiku', 'Amol', 'Lini'],
'physics': [68, 74, 77, 78],
'chemistry': [84, 56, 73, 69],
'algebra': [78, 88, 82, 87]
}
# create dataframe
df_marks = pd.DataFrame(data=mydictionary)
print('DataFrame\n-------')
print(df_marks)
# calculate mean of the whole Dataframe
mean = df_marks.mean().mean()
print('\nMean\n-------')
print(mean)
执行和输出:
3.20.3. 按行计算 DataFrame 的平均值
接下来的示例中,我们将按行,也就是 axis=1,来计算平均值。本示例的意义在于计算出了每位同学所有科目的平均分。
import pandas as pd
mydictionary = {
'names': ['Somu', 'Kiku', 'Amol', 'Lini'],
'physics': [68, 74, 77, 78],
'chemistry': [84, 56, 73, 69],
'algebra': [78, 88, 82, 87]
}
# create dataframe
df_marks = pd.DataFrame(mydictionary)
print('DataFrame\n--------')
print(df_marks)
# calculate mean along rows
mean = df_marks.mean(axis=1)
print('\nMean\n-------')
print(mean)
# display names and average marks
print('\nAverage marks or percentage for each student')
print(pd.concat([df_marks['names'], mean], axis=1))
执行和输出:
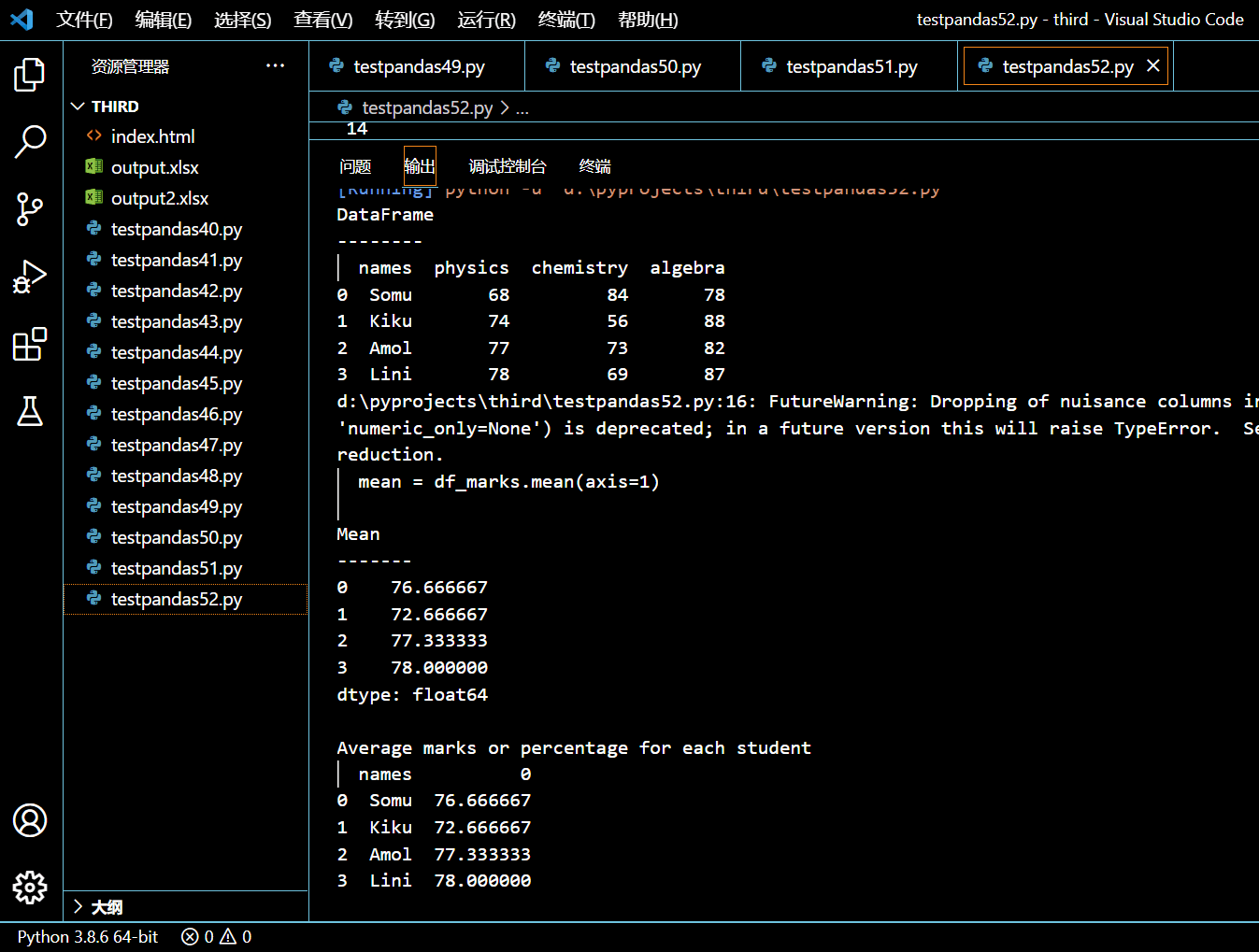
3.20.4. 小结
本节我们了解了如何计算整个 DataFrame 的平均值、按列的平均值、按行的平均值。
3.21. 如何将 DataFrame 的 NaN 填充以默认值?
DataFrame.fillna() 方法把 DataFrame 中的 NA 或 NaN 值填充(或取代)以指定值。
fillna() 方法可用于填充整个 DataFrame 中的 NaN值,也可以指定列,或者对要填充的数量进行限制,或者指定要填充的 axis。
3.21.1. DataFrame.fillna() 的语法
DataFrame.fillna() 方法的语法如下:
DataFrame.fillna(self, value=None, method=None, axis=None, inplace=False, limit=None, downcast=None) → Union[ForwardRef(‘DataFrame’), NoneType][source]
其中,
- value 可以是 scalar、字典、Pandas Series 或者 DataFrame。
- method 可以这些值 {'backfill', 'bfill', 'pad', 'ffill', None}。
- axis 索引的话取值 0 或 'index';列的话取值 1 或 'columns'。
- inplace 是一个布尔值参数。如果设置为 True,那么就在原来的 DataFrame 上修改;如果为 False,将会返回一个修改后内容的新的 DataFrame。
- limit 可以取整型数据或者置空。它表示向前/向后填充的连续 NaN 值的最大数量值。该参数仅在已指定 method 时有效。
- downcast 可以取值一个字典类型或置空。
这些参数都是自说明代码,上面我们为它们提供了可以传递的可能值。但我们还需要详尽的示例来具体了解 fillna() 的使用。
3.21.2. ataFrame.fillna() 将 NaN 值替换为 0
这是 fillna() 方法的一个基本用法,但会是了解该方法使用的一个好的起点。
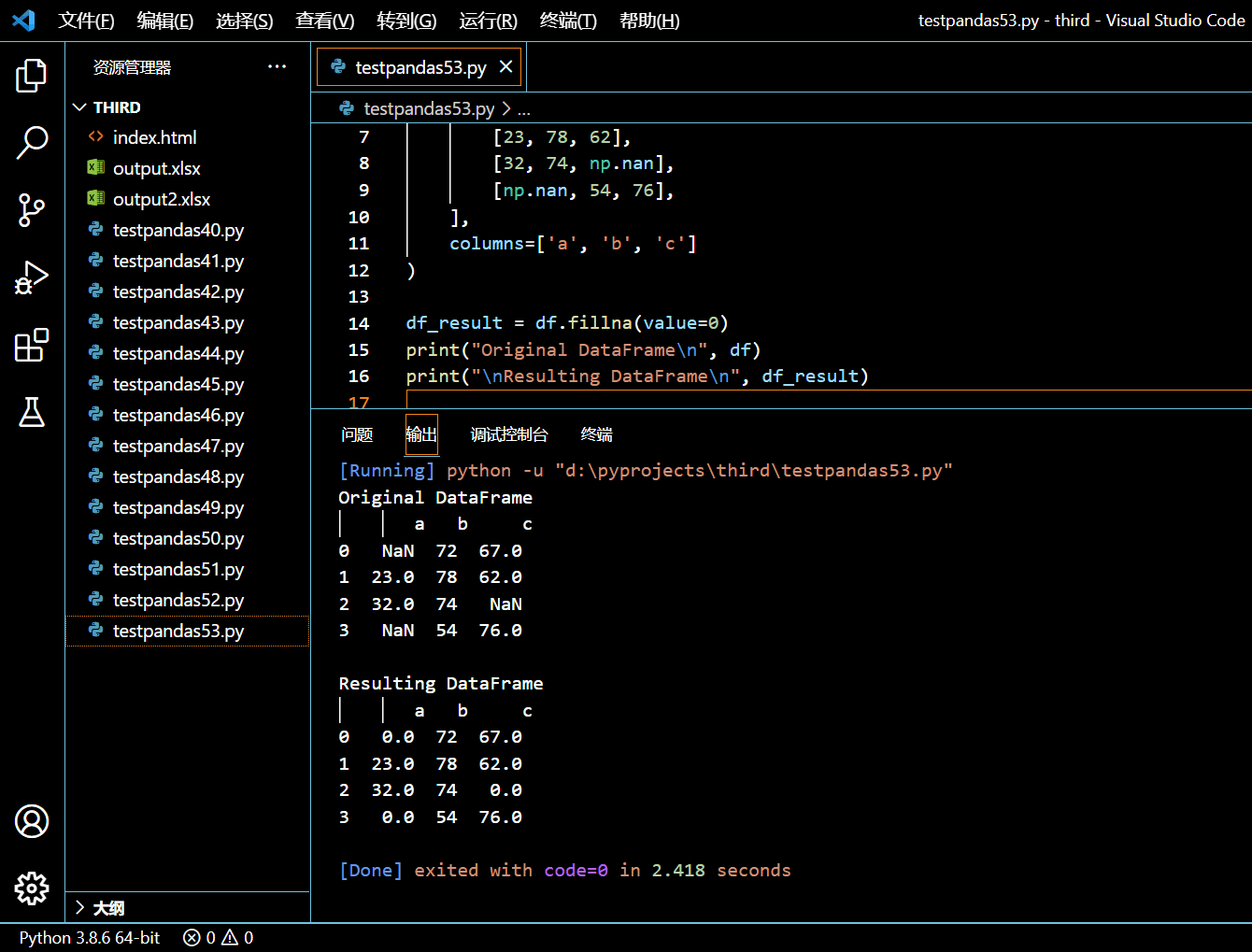
在接下来的程序中,我们将创建一个含有 NaN 值的 DataFrame。然后我们将使用 fillna() 方法把这些 NaN 值替换为 0。我们把 0 值传递给 fillna() 里的 value 参数。
import pandas as pd
import numpy as np
df = pd.DataFrame(
data=[
[np.nan, 72, 67],
[23, 78, 62],
[32, 74, np.nan],
[np.nan, 54, 76],
],
columns=['a', 'b', 'c']
)
df_result = df.fillna(value=0)
print("Original DataFrame\n", df)
print("\nResulting DataFrame\n", df_result)
执行和输出:
3.21.3. DataFrame.fillna() 根据不同的列将 NaN 值替换为不同的值
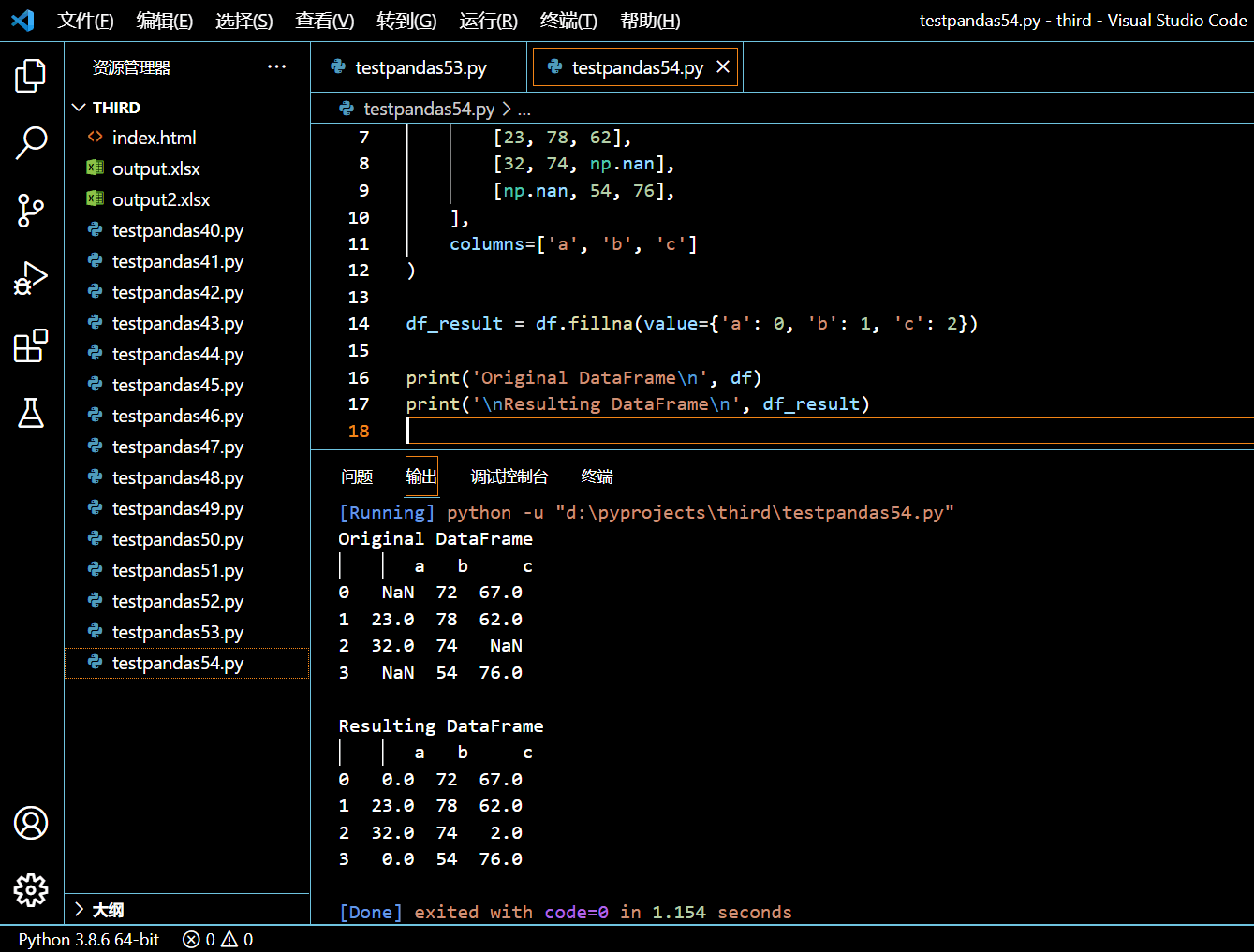
value 参数也可以取值于一个字典。该字典中是一系列的列名和替换值对。指定列的 NaN 值将被指定的值所替代。
在接下来的示例中,我们将创建一个含有 NaN 值的 DataFrame。之后,我们使用 fillna() 方法对于不同的列里的 NaN 值替换以不同值。我们将用承载有这些列名和目标值的字典作为参数传入。
import pandas as pd
import numpy as np
df = pd.DataFrame(
data=[
[np.nan, 72, 67],
[23, 78, 62],
[32, 74, np.nan],
[np.nan, 54, 76],
],
columns=['a', 'b', 'c']
)
df_result = df.fillna(value={'a': 0, 'b': 1, 'c': 2})
print('Original DataFrame\n', df)
print('\nResulting DataFrame\n', df_result)
执行和输出:
3.21.4. inplace=True 参数
默认情况下,fillna() 方法返回承载修改后数据的一个新的 DataFrame。但是,如果你想直接修改原始 DataFrame 里的数据,传 True 给 inplace 参数。
import pandas as pd
import numpy as np
df = pd.DataFrame(
data=[
[np.nan, 72, 67],
[23, np.nan, 62],
[32, 74, np.nan],
[np.nan, 54, 76],
],
columns=['a', 'b', 'c']
)
print("Original DataFrame\n", df)
df.fillna(value=0, inplace=True)
print("\nModified DataFrame\n", df)
执行和输出:
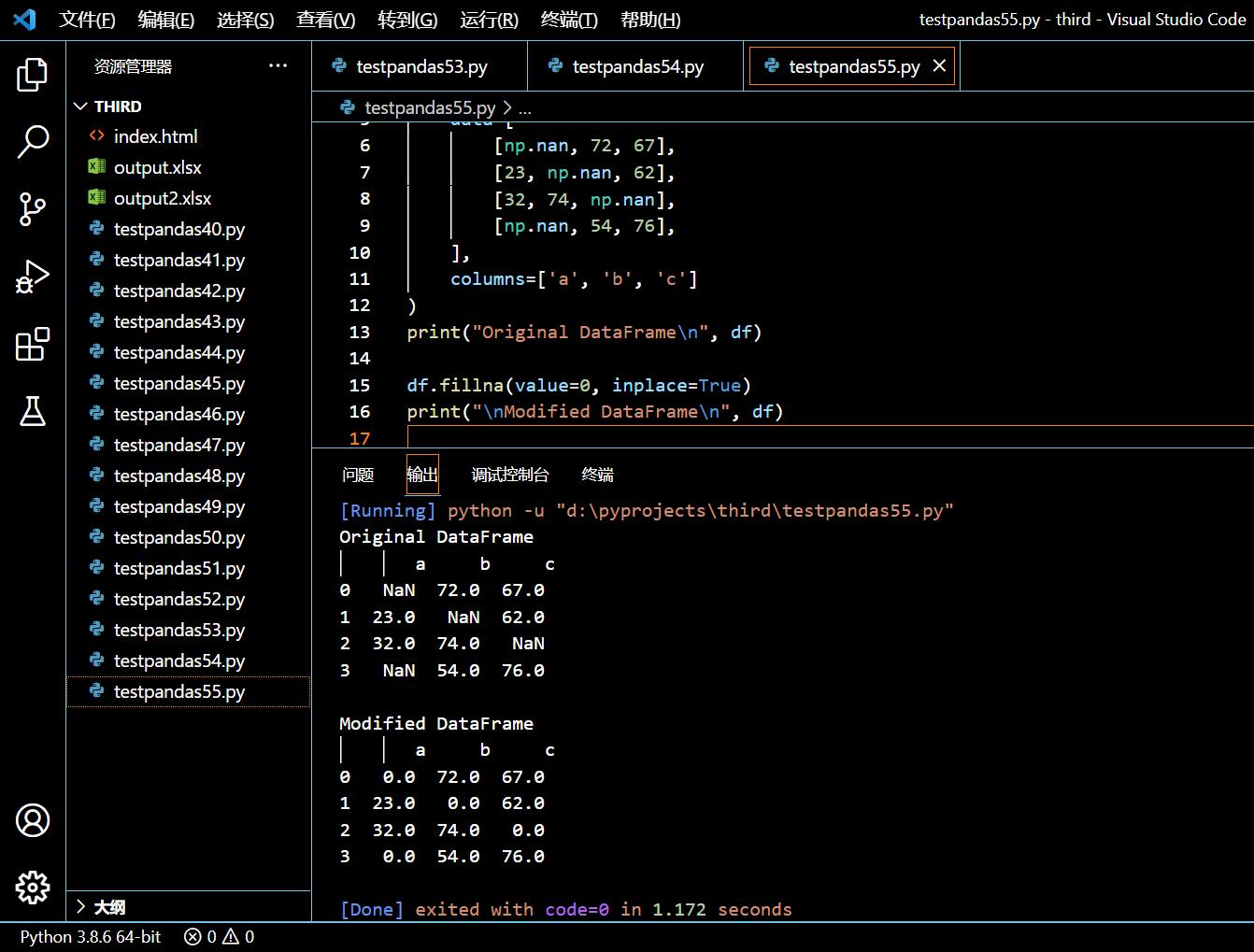
3.21.5. 小结
本节我们了解了 DataFrame.fillna() 方法的用法。
3.22. 获取轴信息
要获取索引、列名、数据类型之类的轴信息,可以使用 DataFrame.axes 属性。
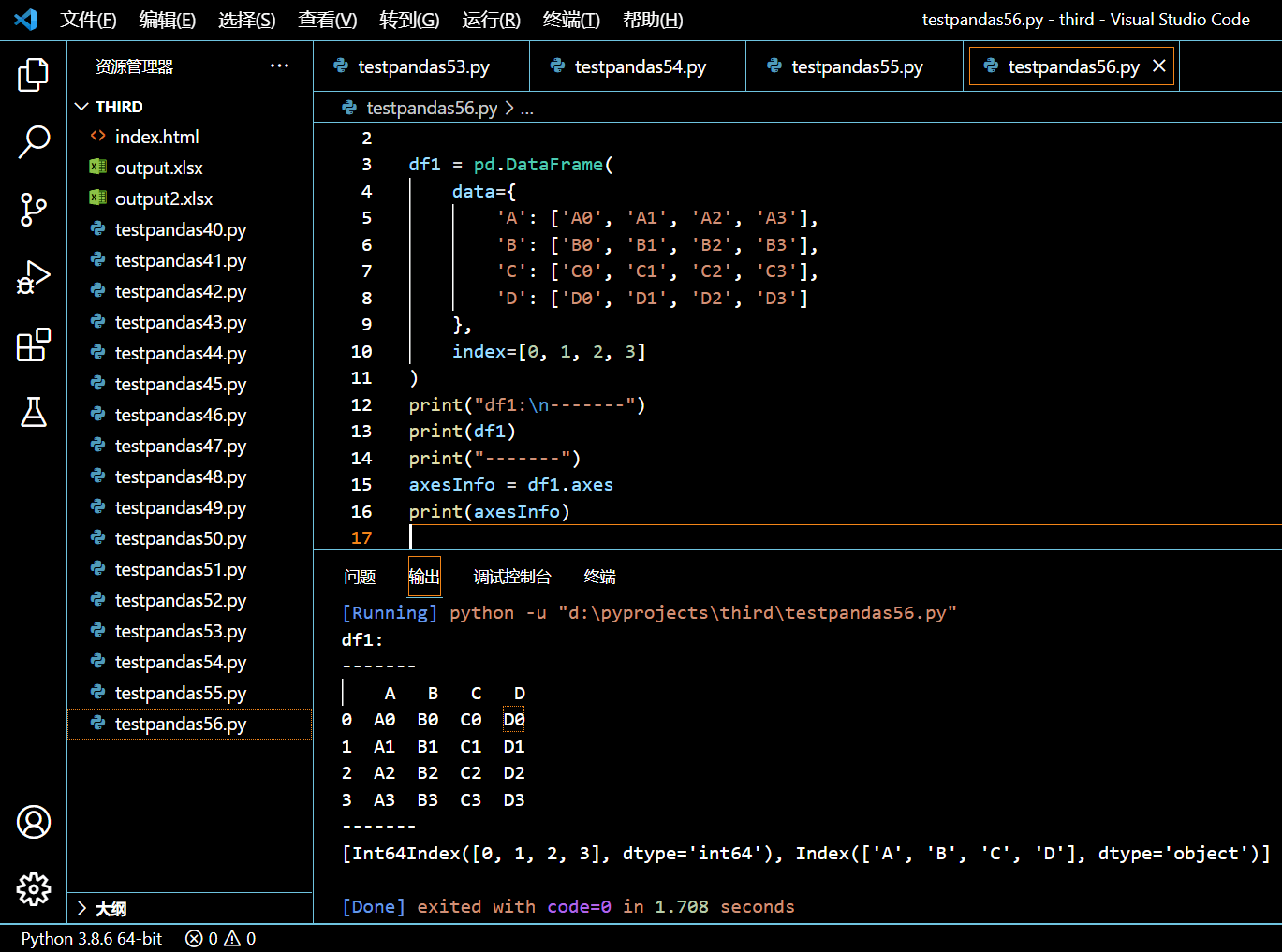
3.22.1. 示例一
本示例中,我们将初始化一个多行的 DataFrame,然后调用它的 axes 属性。
import pandas as pd
df1 = pd.DataFrame(
data={
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']
},
index=[0, 1, 2, 3]
)
print("df1:\n-------")
print(df1)
print("-------")
axesInfo = df1.axes
print(axesInfo)
执行和输出:
3.22.2. 示例二
在接下来的示例中,我们将初始化一个不指明索引的 DataFrame,然后观察 DataFrame.axes 的返回。
import pandas as pd
df1 = pd.DataFrame(
data={
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']
}
)
print("df1:\n-------")
print(df1)
print("-------")
axesInfo = df1.axes
print(axesInfo)
执行和输出:
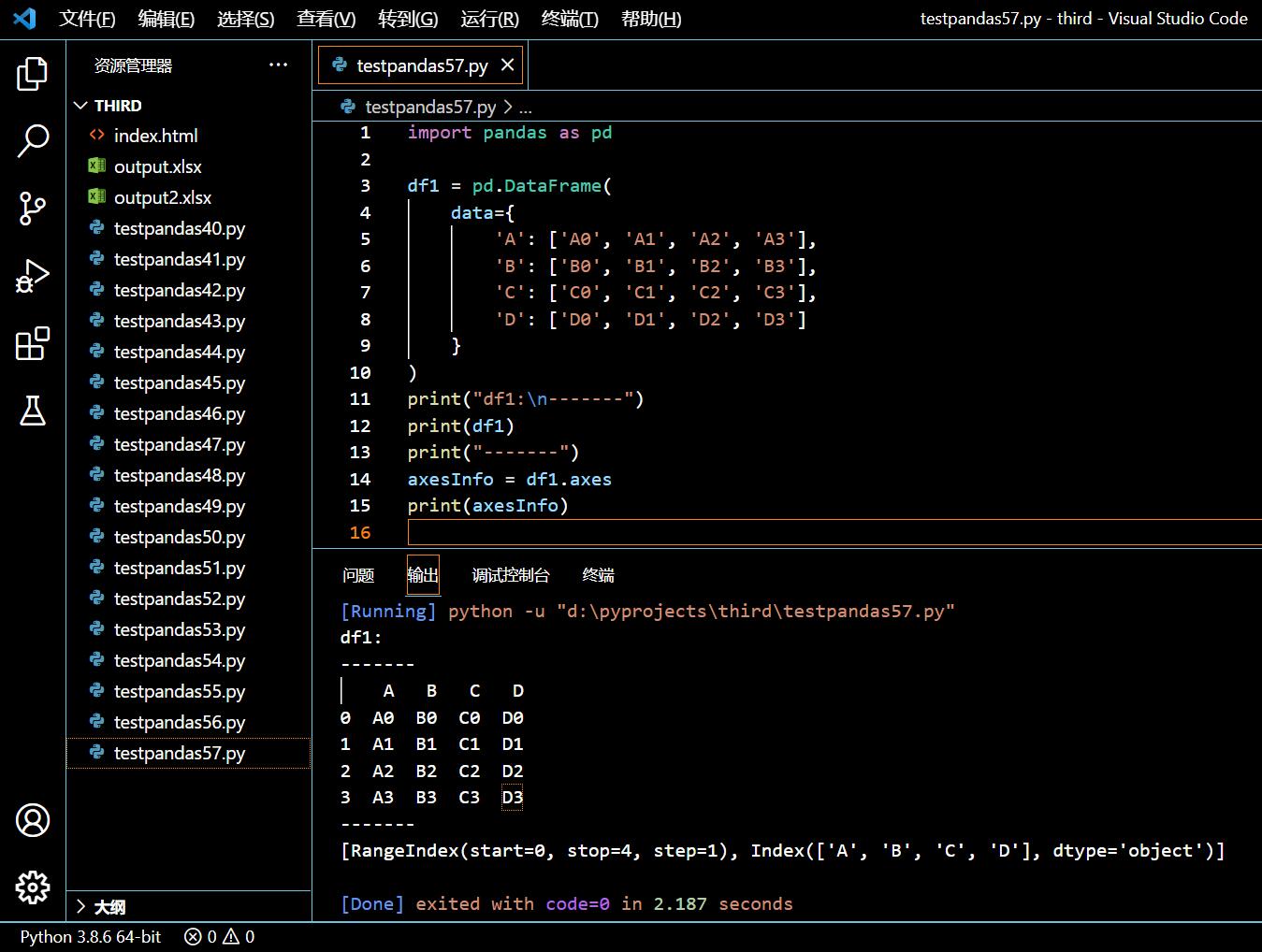
可见,如果我们在初始化 DataFrame 时不提供索引,DataFrame 将使用默认索引。
3.22.3. 小结
本节我们了解到了如何使用 DataFrame 类的 axes 属性来获取一个 DataFrame 的 axes 的相关信息。
3.23. 内连接
关于 SQL join 连接可以参考博客《(手把手教你写 SQL Join 联接)[https://blog.csdn.net/defonds/article/details/5910005]》。内连接其实是左连接、右连接结果集的交集。也就是,两张表相交基于的字段在两张表里都不为空,符合条件的结果才会拿出来进行连接。
你可以在连接两个 DataFrame 的时候进行内连接,进而得到它们相交的结果。
concat() 函数进行内连接的语法如下所示:
pd.concat([df1, df2], axis=1, join='inner')
内连接的结果是两个 DataFrame 沿指定轴相交。
3.23.1. axis=1 内连接
本示例中,我们将新建两个 DataFrame,然后找到它们关于 axis=1 的内连接。
import pandas as pd
df1 = pd.DataFrame(
data={
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']
},
index=[0, 1, 2, 3]
)
df2 = pd.DataFrame(
data={
'B': ['B2', 'B3', 'B4', 'B5'],
'D': ['D2', 'D3', 'D4', 'D5'],
'F': ['F2', 'F3', 'F4', 'F5']
},
index=[2, 3, 4, 5]
)
print("df1:\n-------\n")
print(df1)
print("\ndf2:\n-------\n")
print(df2)
result = pd.concat(objs=[df1, df2], axis=1, join="inner")
print("\nresult:\n-------\n")
print(result)
执行和输出:
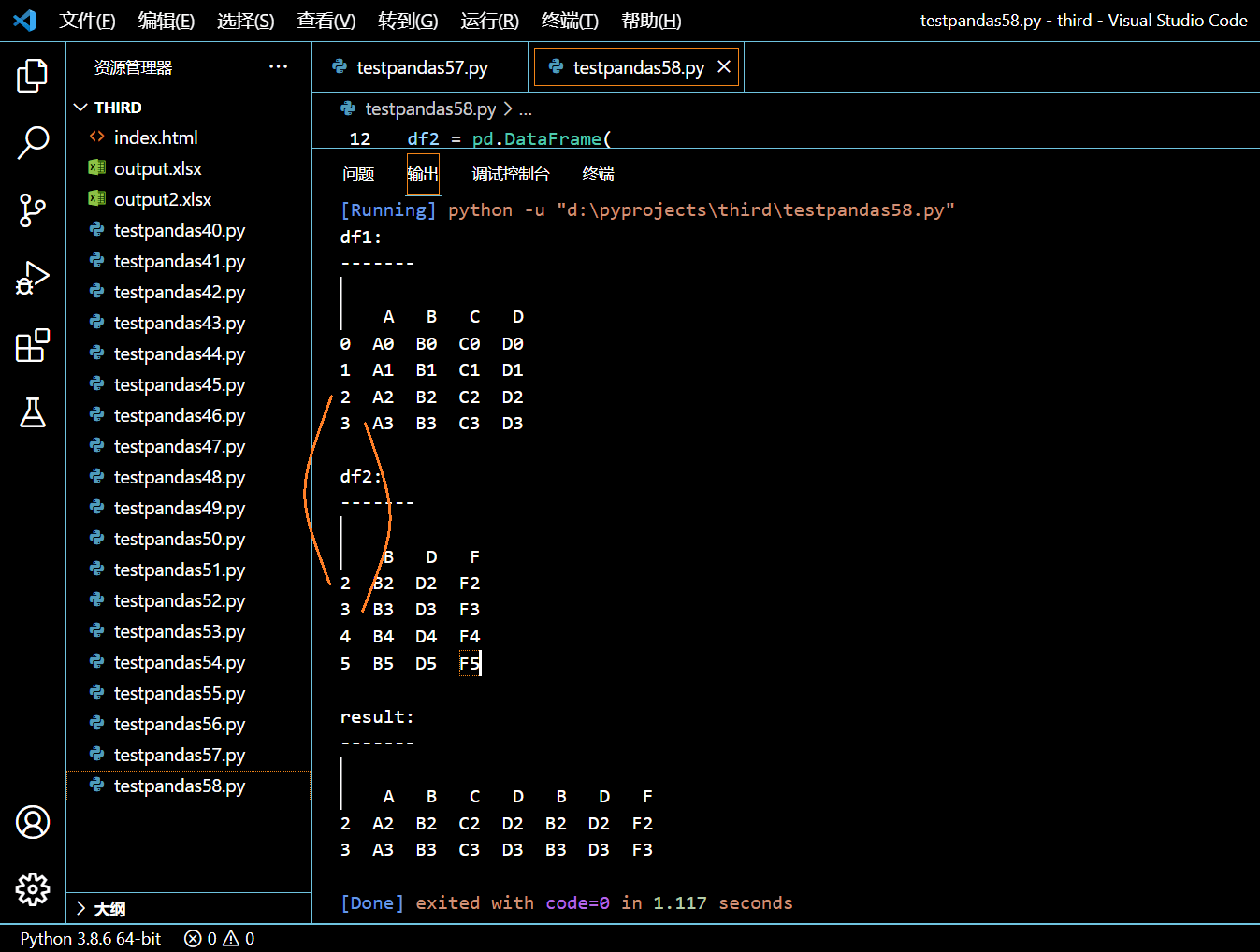
可见 axis=1 时的内连接,是根据每行索引进行匹配连接。
3.23.2. axis=0 内连接
接下来我们依然以上面的数据,尝试 axis=0 的内连接。
import pandas as pd
df1 = pd.DataFrame(
data={
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']
},
index=[0, 1, 2, 3]
)
df2 = pd.DataFrame(
data={
'B': ['B2', 'B3', 'B4', 'B5'],
'D': ['D2', 'D3', 'D4', 'D5'],
'F': ['F2', 'F3', 'F4', 'F5']
},
index=[2, 3, 4, 5]
)
print("df1:\n-------\n")
print(df1)
print("\ndf2:\n-------\n")
print(df2)
result = pd.concat(objs=[df1, df2], axis=0, join="inner")
print("\nresult:\n-------\n")
print(result)
执行和输出:
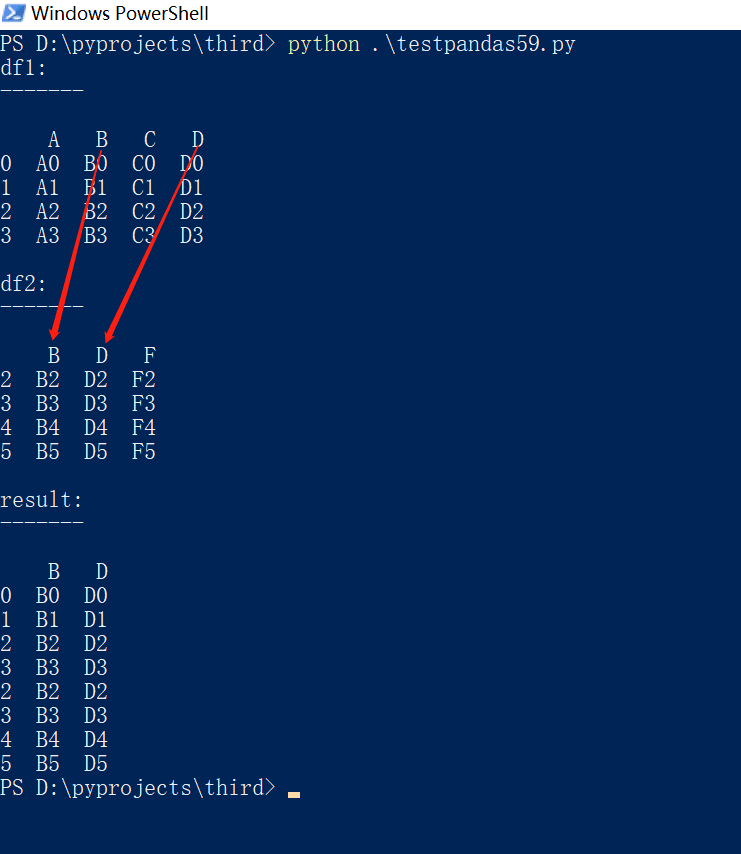
可见 axis=0 时的内连接,是根据每列索引进行匹配连接。
3.23.3. 两个以上 DataFrame 的内连接
接下来的示例中,我们将来尝试 3 个 DataFrame 的内连接。
import pandas as pd
df1 = pd.DataFrame(
data={
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']
},
index=[0, 1, 2, 3]
)
df2 = pd.DataFrame(
data={
'B': ['B2', 'B3', 'B4', 'B5'],
'D': ['D2', 'D3', 'D4', 'D5'],
'F': ['F2', 'F3', 'F4', 'F5']
},
index=[2, 3, 4, 5]
)
df3 = pd.DataFrame(
data={
'D': ['D3', 'D4', 'D5'],
'G': ['G3', 'G4', 'G5']
},
index=[3, 4, 5]
)
print("df1:\n-------\n")
print(df1)
print("\ndf2:\n-------\n")
print(df2)
print("\ndf3:\n-------\n")
print(df3)
result = pd.concat(objs=[df1, df2, df3], axis=1, join="inner")
print("\nresult:\n-------\n")
print(result)
执行和输出:

3.23.4. 小结
本节我们了解了如何使用连接函数对两个或多个 DataFrame 进行基于 axis 的内连接。
4. Pandas DataFrame 单元格操作篇
4.1. 如何检查 Pandas 里单元格的值是否为 NaN?
NaN = Not a Number。Pandas 使用 numpy.nan 作为 NaN 值。
要检查 Pandas 内某一特定位置是否为 NaN,将该值作为参数调用 numpy.isnan() 函数:
numpy.isnan(value)
如果该值 equals numpy.nan,该表达式返回 True,否则返回 False。
4.1.1. 检查 Pandas DataFrame 某单元格的值是否为 NaN
本示例中,我们将新建一个包含有 NaN 值的 DataFrame,然后检查其特定位置的值是否为 NaN。
import pandas as pd
import numpy as np
df = pd.DataFrame(
data=[
[np.nan, 72, 67],
[23, 78, 62],
[32, 74, np.nan],
[np.nan, 54, 76]
],
columns=['a', 'b', 'c']
)
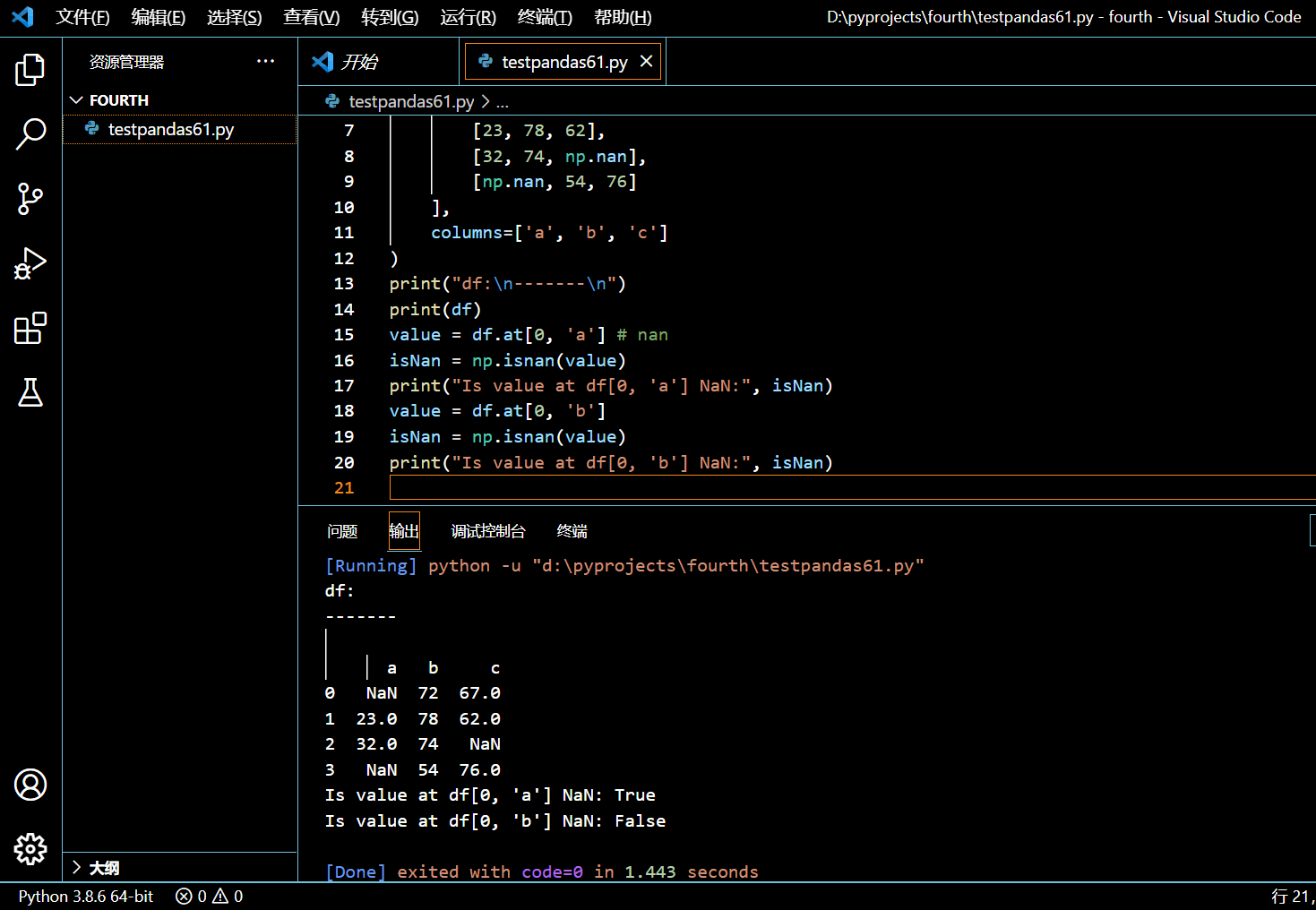
print("df:\n-------\n")
print(df)
value = df.at[0, 'a'] # nan
isNan = np.isnan(value)
print("Is value at df[0, 'a'] NaN:", isNan)
value = df.at[0, 'b']
isNan = np.isnan(value)
print("Is value at df[0, 'b'] NaN:", isNan)
执行和输出:
4.1.2. 迭代检查 Pandas DataFrame 中单元格的值是否为 NaN
在接下来的示例中,我们仍将创建一个包含有多个 NaN 值的 DataFrame。然后我们对该 DataFrame 进行遍历并挨个检查每个单元格是否为 NaN。
import pandas as pd
import numpy as np
df = pd.DataFrame(
data=[
[np.nan, 72, 67],
[23, 78, 62],
[32, 74, np.nan],
[np.nan, 54, 76]
]
)
print("df:\n-------\n")
print(df)
for i in range(df.shape[0]): # iterate over rows
for j in range(df.shape[1]): # iterate over columns
value = df.at[i, j] # get cell value
print(np.isnan(value), end="\t")
print()
执行和输出:
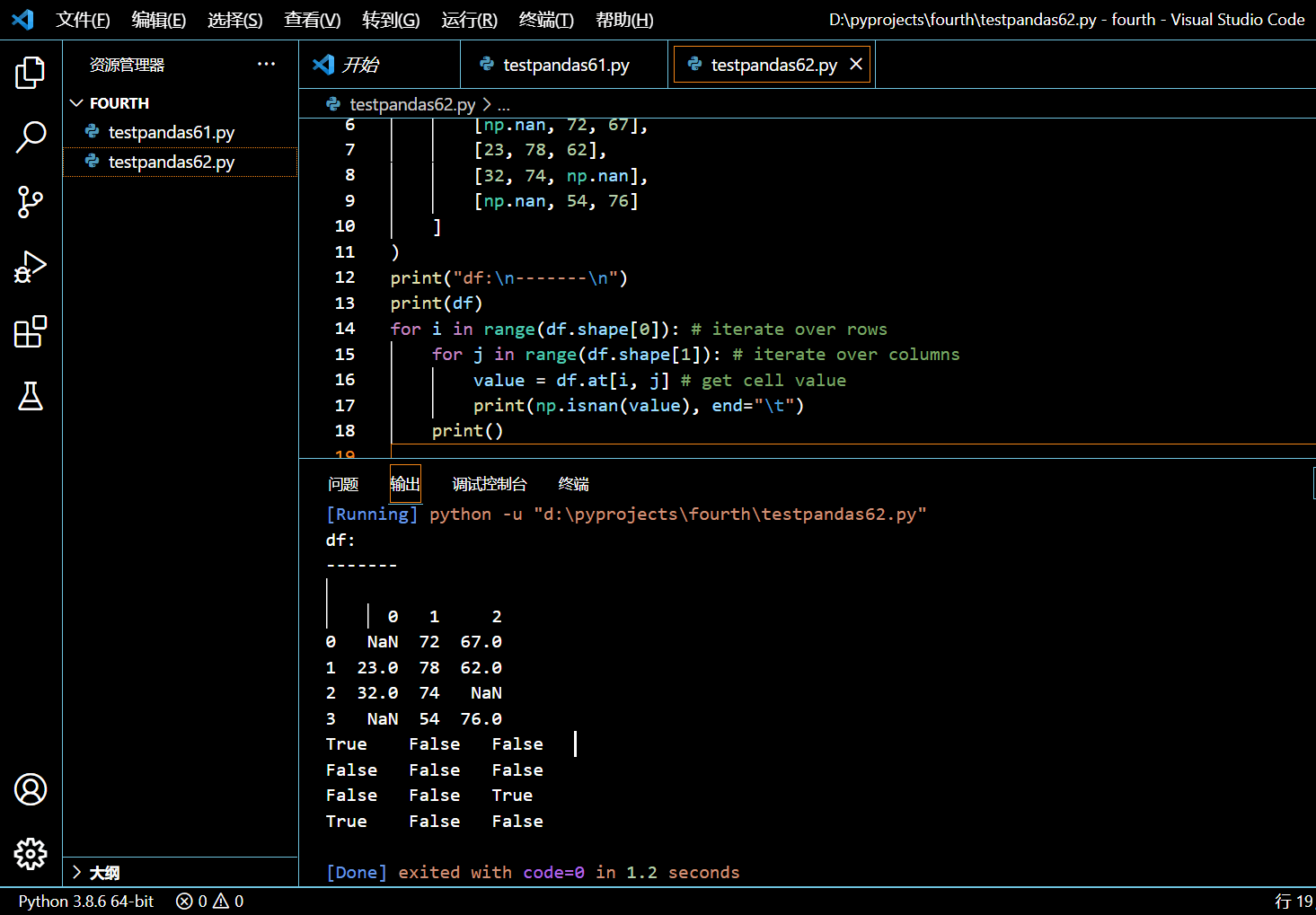
4.1.3. 小结
本节我们了解到了如何使用 numpy.isnan() 函数来检查 Pandas 里特定单元格的值是否为 NaN。
4.2. 如何遍历 Pandas DataFrame 里的单元格?
接下来,我们来了解一下如何遍历一个 Pandas DataFrame 里单元格的值。
方法 1:通过 DataFrame 的维度,使用嵌套 for 循环遍历单元格。
方法 2:使用 DataFrame.iterrows() 来遍历 DataFrame 的行;然后对于每一行使用 Series.items() 来遍历其中的元素。
4.2.1. 通过 DataFrame.shape 遍历 Pandas DataFrame 中的单元格
接下来的示例中,我们将使用一个嵌套的 for 循环来遍历 Pandas DataFrame 里的行和列。我们将借助 DataFrame.shape 来得到 DataFrame 里的行数和列数。然后我们再用 DataFrame.at() 来访问具体单元格的值。
import pandas as pd
import numpy as np
df = pd.DataFrame(
data=[
[1, 2, 3],
[4, 5, 6],
[7, 8, 9],
[10, 11, 12]
]
)
print("df:\n-------\n")
print(df)
for i in range(df.shape[0]): # iterate over rows
for j in range(df.shape[1]): # iterate over columns
value = df.at[i, j] # get cell value
print(value, end="\t")
print()
执行和输出:
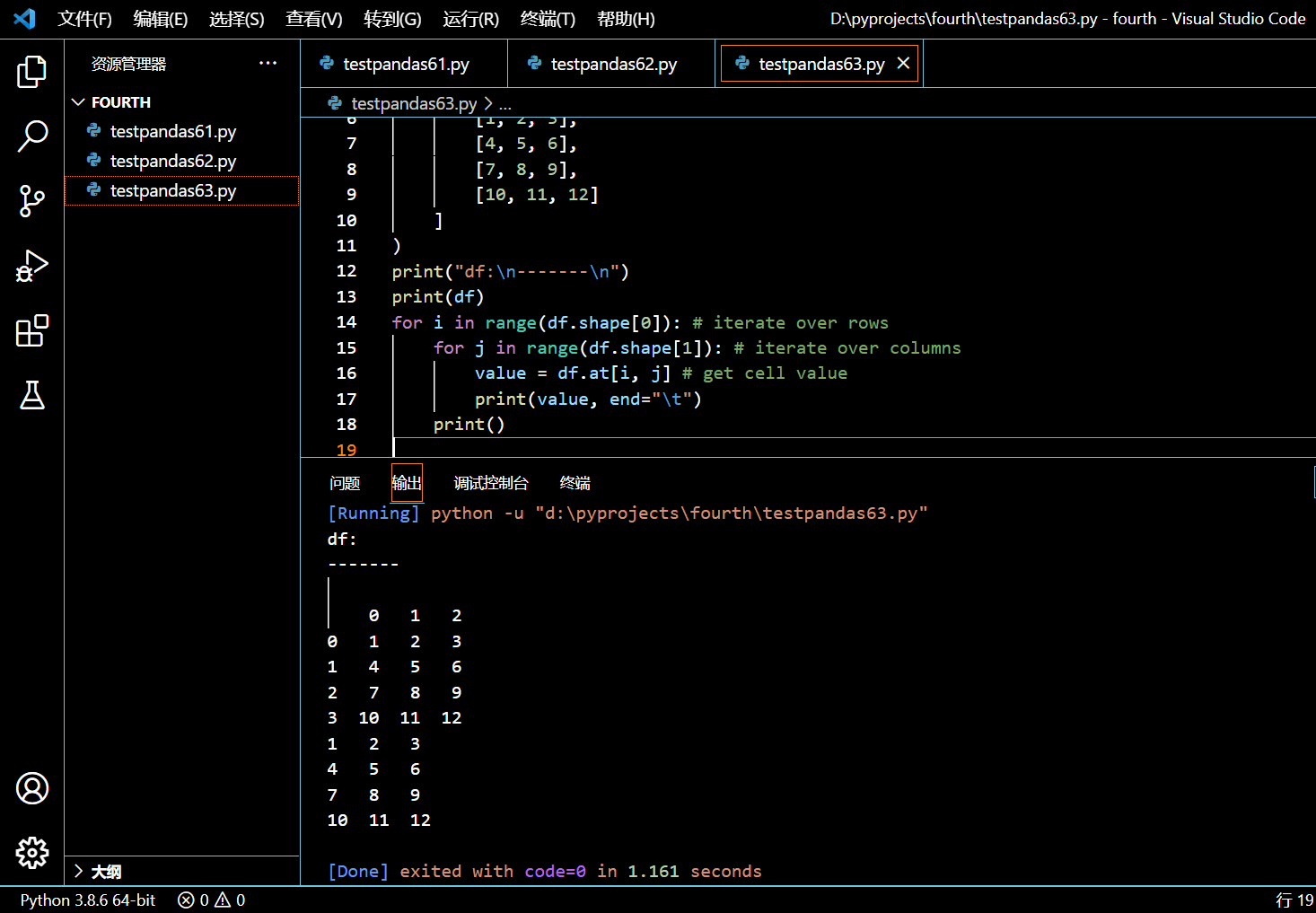
4.2.2. 通过 DataFrame.iterrows() 遍历 Pandas 里的单元格
接下来的示例中,我们使用 DataFrame.iterrows() 来遍历所有的行;对于每一行,也就是上一步的一个 Series,我们将通过 Series.items() 来遍历它。
import pandas as pd
import numpy as np
df = pd.DataFrame(
data=[
[1, 2, 3],
[4, 5, 6],
[7, 8, 9],
[10, 11, 12]
]
)
for rowIndex, row in df.iterrows(): # iterate over rows
for columnIndex, value in row.items():
print(value, end="\t")
print()
执行和输出:
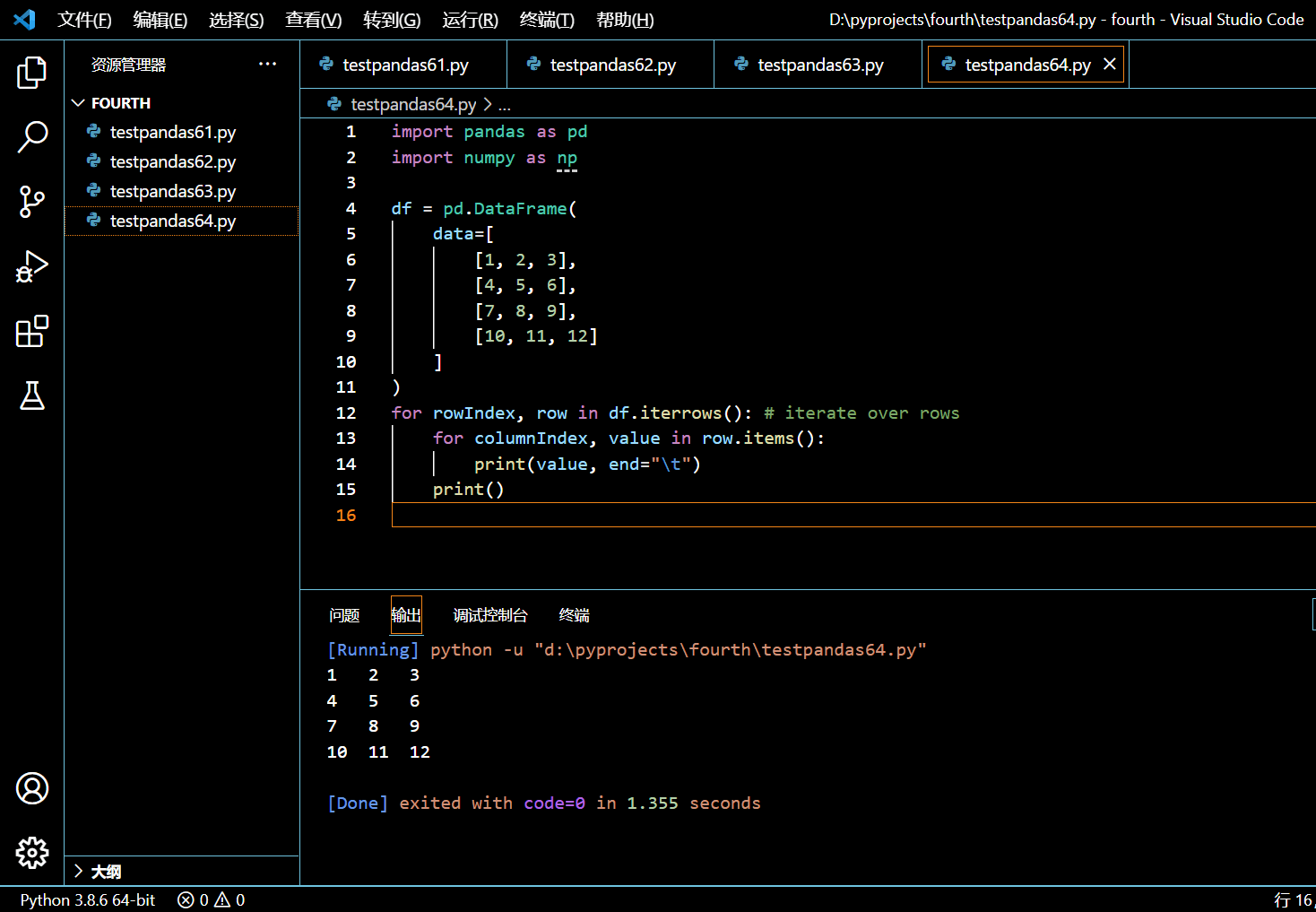
如上示例,我们还拿到了行索引和列索引。
4.2.3. 小结
本节我们通过示例了解到了如何对 DataFrame 里的单元格进行遍历。
5. Pandas DataFrame 列操作篇
5.1. 怎样获取 Pandas DataFrame 的列名?
要拿到 DataFrame 的列名,可以使用 DataFrame.columns 属性,使用该属性的语法如下:
DataFrame.columns
columns 属性将返回一个 Index 类型的对象。然后我们就可以使用 Python 中任意一种循环技术(参考博客《简单 Python 快乐之旅之:Python 基础语法之循环关键字的使用例子》)来访问各个列名了。
5.1.1. 打印 DataFrame 列名
本示例中,我们将拿到 DataFrame 的列名并将其打印。
import pandas as pd
# initialize a dataframe
df = pd.DataFrame(
data=[
['Amol', 72, 67, 91],
['Lini', 78, 69, 87],
['Kiku', 74, 56, 88],
['Ajit', 56, 76, 78]
],
columns=['name', 'physics', 'chemistry', 'algebra']
)
# get the dataframe columns
cols = df.columns
print(cols)
执行和输出:

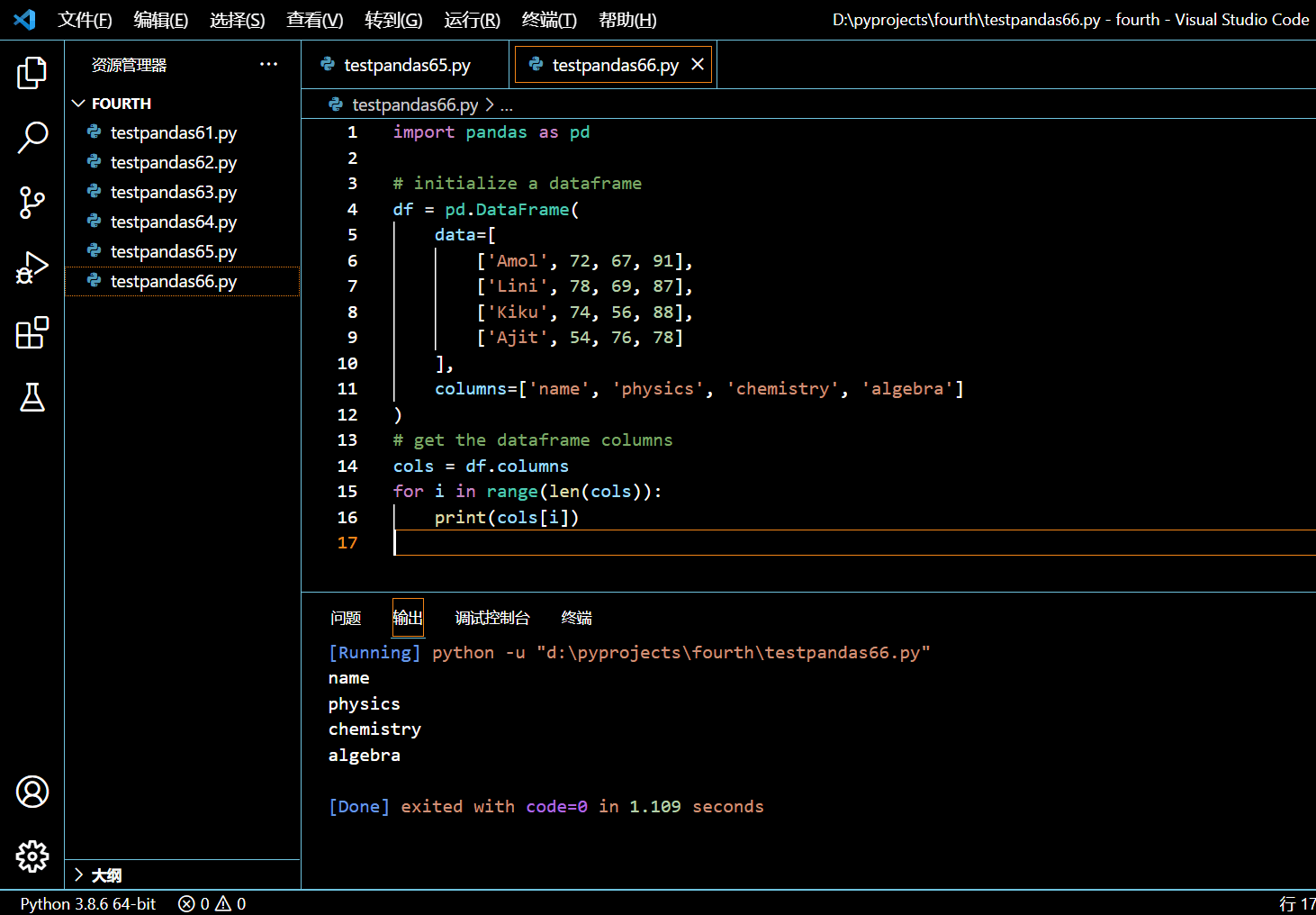
5.1.2. 使用索引访问各个列名
可以使用 Index 对象来访问各个列名。
import pandas as pd
# initialize a dataframe
df = pd.DataFrame(
data=[
['Amol', 72, 67, 91],
['Lini', 78, 69, 87],
['Kiku', 74, 56, 88],
['Ajit', 54, 76, 78]
],
columns=['name', 'physics', 'chemistry', 'algebra']
)
# get the dataframe columns
cols = df.columns
for i in range(len(cols)):
print(cols[i])
执行和输出:
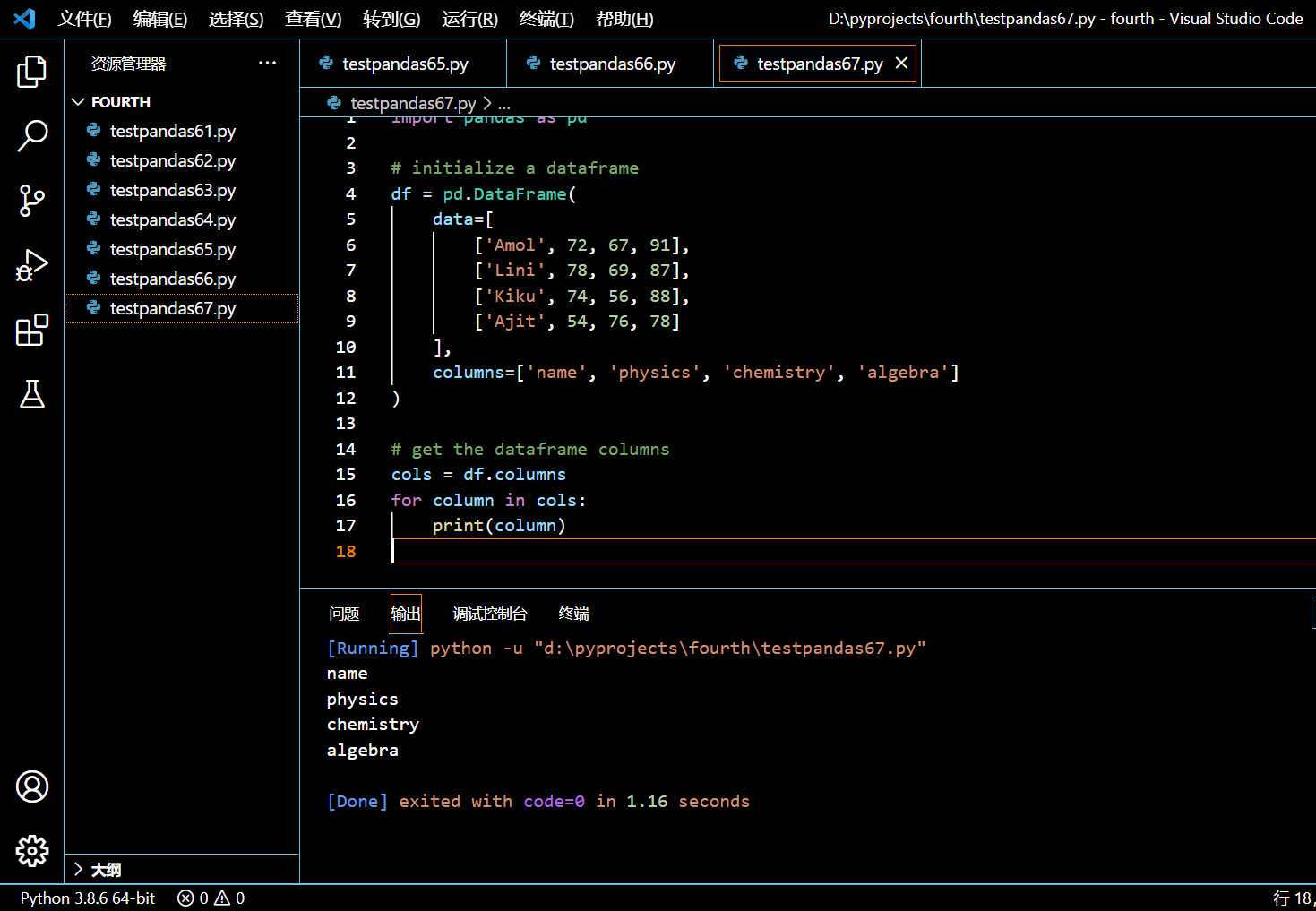
5.1.3. 使用 for 循环访问各个列名
你也可以使用 for 循环来遍历 DataFrame 的列名。
import pandas as pd
# initialize a dataframe
df = pd.DataFrame(
data=[
['Amol', 72, 67, 91],
['Lini', 78, 69, 87],
['Kiku', 74, 56, 88],
['Ajit', 54, 76, 78]
],
columns=['name', 'physics', 'chemistry', 'algebra']
)
# get the dataframe columns
cols = df.columns
for column in cols:
print(column)
执行和输出:
5.1.4. 小结
本节我们通过 DataFrame.column 属性来获取到各个列名。
5.2. 如何修改 Pandas DataFrame 的列标签?
要修改或重命名 Pandas DataFrame 的列标签,只需要将新的列标签(数组)分配给 DataFrame 列名即可。
5.2.1. 语法
分配新列名的语法如下:
dataframe.columns = new_columns
new_columns 应该是一个数组,其长度要和 DataFrame 的列数一样大。
5.2.2. 对 DataFrame 列标签进行修改
本示例中,我们将创建带有一些初始列名的 DataFrame,然后通过分配 columns 属性对这些列名进行改变。
import pandas as pd
import numpy as np
df_marks = pd.DataFrame(
data=[
['Somu', 68, 84, 78, 69],
['Kiku', 74, 56, 88, 85],
['Amol', 77, 73, 82, 87],
['Lini', 78, 69, 87, 92]
],
columns=['name', 'physics', 'chemistry', 'algebra', 'calculus']
)
print("Original DataFrame\n-------")
print(df_marks)
# rename columns
df_marks.columns = ['name', 'physics', 'biology', 'geometry', 'calculus']
print("\n\nColumns renamed\n-------")
print(df_marks)
执行和输出:
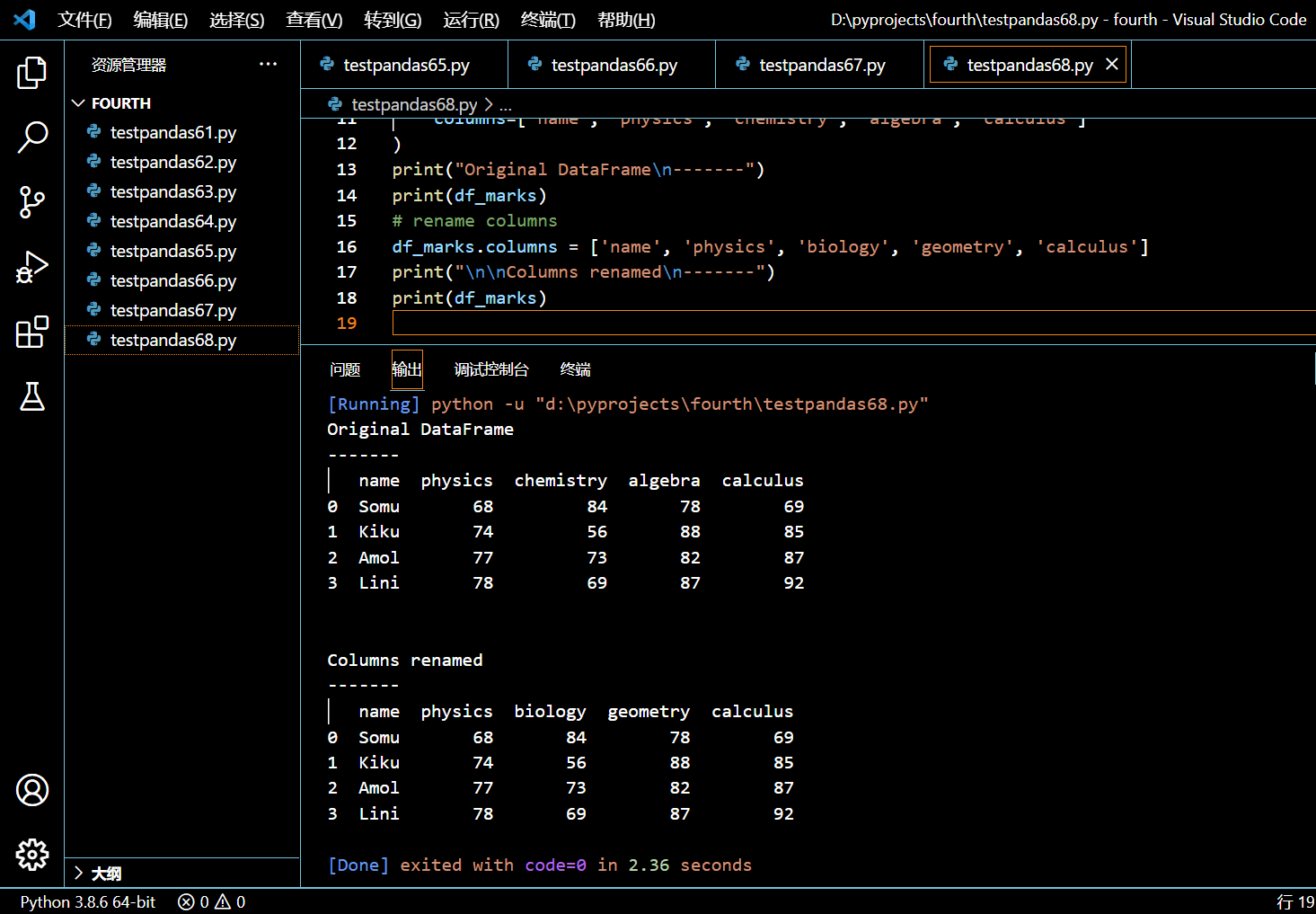
可见 DataFrame 已经被应用于新的列标签。
5.2.3. 小结
本节我们了解到了如何对 DataFrame 的列标签进行修改。
5.3. 怎样得到 Pandas 中每列的数据类型?
要得到 Pandas DataFrame 里每列的数据类型,调用 DataFrame.dtypes 属性。DataFrame.dtypes 属性返回含有每个列数据类型的一个 pandas.Series 类型的对象。
使用 DataFrame dtype 属性的语法如下:
DataFrame.dtypes
在接下来的程序中,我们使用特定数据和列名创建了一个 DataFrame,然后使用 DataFrame.dtypes 拿到每列的数据类型。
import pandas as pd
df = pd.DataFrame(
data=[
['abc', 22],
['xyz', 25],
['pqr', 31]
],
columns=['name', 'age']
)
print("df\n-------\n")
print(df)
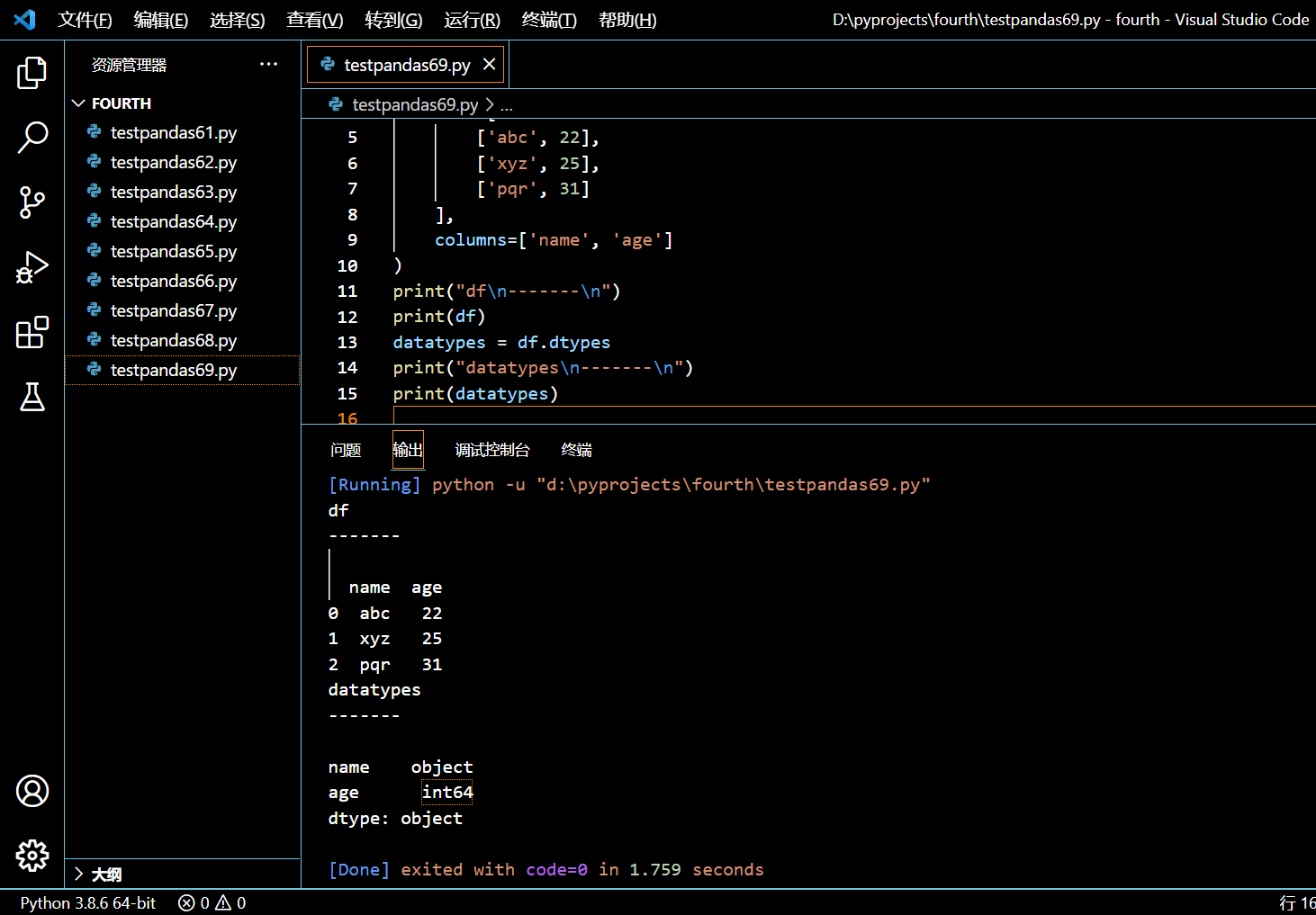
datatypes = df.dtypes
print("datatypes\n-------\n")
print(datatypes)
执行和输出:
我们可以用 for 循环将 DataFrame.dtypes 返回值里的元素遍历出来:
import pandas as pd
df = pd.DataFrame(
data=[
['abc', 22],
['xyz', 25],
['pqr', 31]
],
columns=['name', 'age']
)
print("df\n-------\n")
print(df)
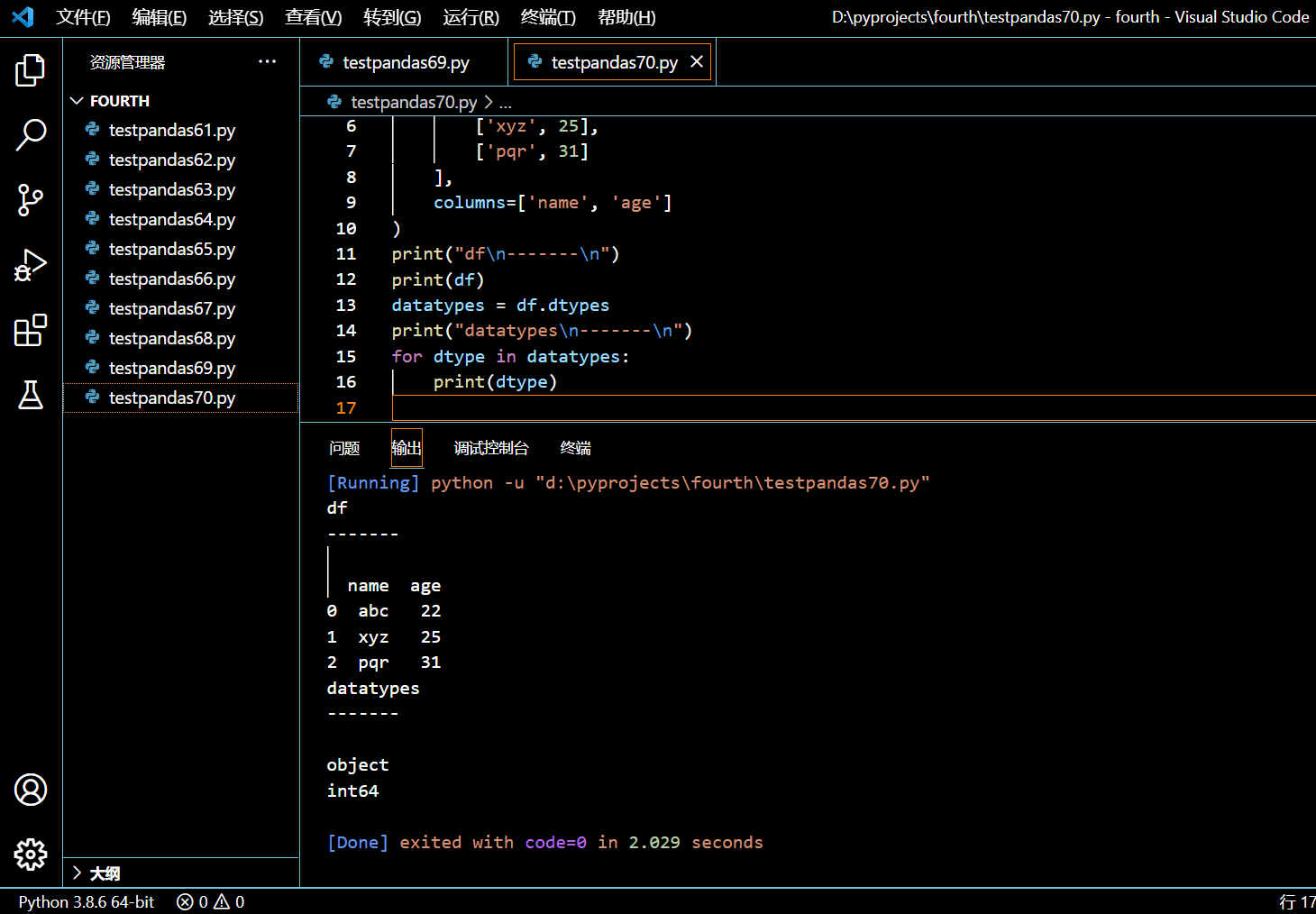
datatypes = df.dtypes
print("datatypes\n-------\n")
for dtype in datatypes:
print(dtype)
执行和输出:
5.3.1. 小结
本节中,我们了解到了如何使用 DataFrame.dtypes 属性拿到 DataFrame 每列的数据类型。
5.4. 如何重命名 Pandas DataFrame 里的列名?
你可以使用 pandas.DataFrame.rename() 方法来对 Pandas DataFrame 的单个或多个列进行重命名。
5.4.1. 重命名单个列
可以使用 DataFrame.rename() 函数来对单个列进行重命名。
import pandas as pd
# initialize a dataframe
df = pd.DataFrame(
data=[
[41, 72, 67, 91],
[21, 78, 69, 87],
[95, 74, 56, 88],
[54, 54, 76, 78]
],
columns=['a', 'b', 'c', 'd']
)
# rename single column
df.rename(columns={'b': 'k'}, inplace=True)
print(df)
执行和输出:
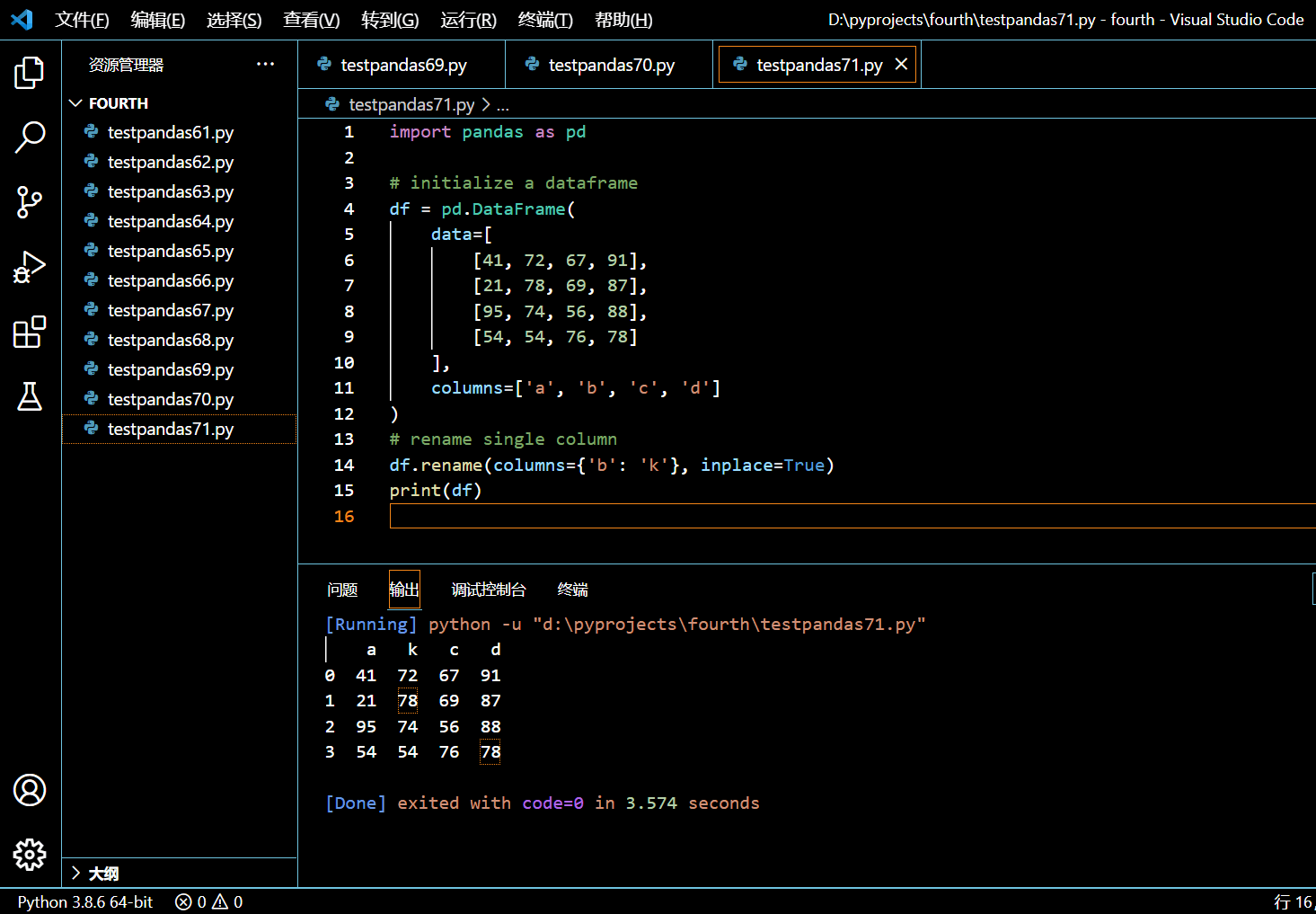
可见列名 b 已被重命名为 k。
5.4.2. 重命名多个列
一次重命名多个列名,还是用 DataFrame.rename(),分别以 老列名 - 新列名的形式进行替换:
import pandas as pd
# initialize a dataframe
df = pd.DataFrame(
data=[
[41, 72, 67, 91],
[21, 78, 69, 87],
[95, 74, 56, 88],
[54, 54, 76, 78]
],
columns=['a', 'b', 'c', 'd']
)
# rename multiple columns
df.rename(columns={'b': 'k', 'c': 'm'}, inplace=True)
print(df)
执行和输出:
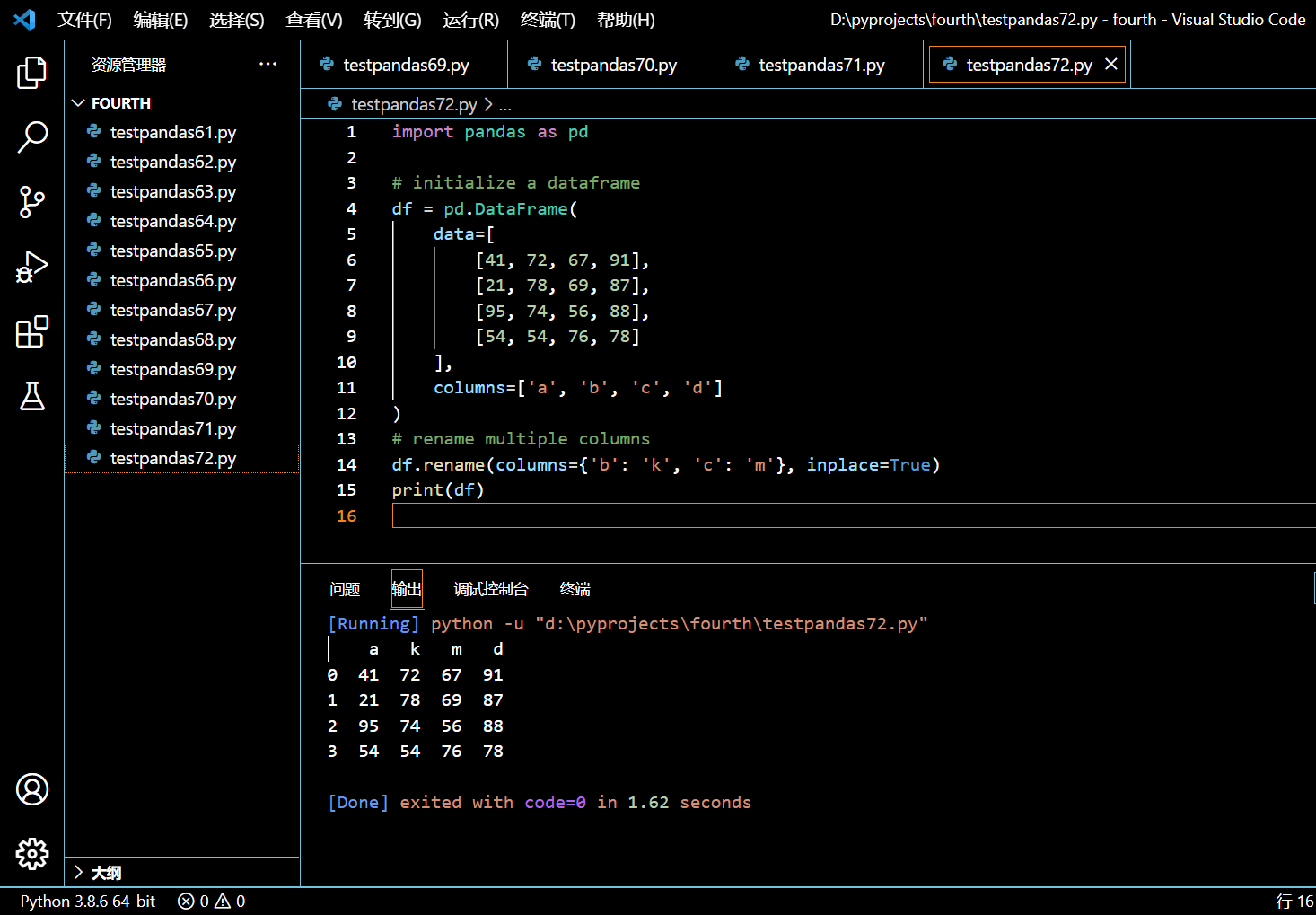
可见原来的列名 b、c 分别被重命名为了 k、m。
5.4.3. 小结
本节中,我们了解到了使用 pandas.DataFrame.rename() 来对一个或多个列进行重命名。
5.5. 选择某一列
可以使用点表示法或者中括号来从 Pandas DataFrame 中选择某一列。
#select column using dot operator
a = myDataframe.column_name
#select column using square brackets
a = myDataframe[coulumn_name]
被选中的列将返回 Pandas Series。
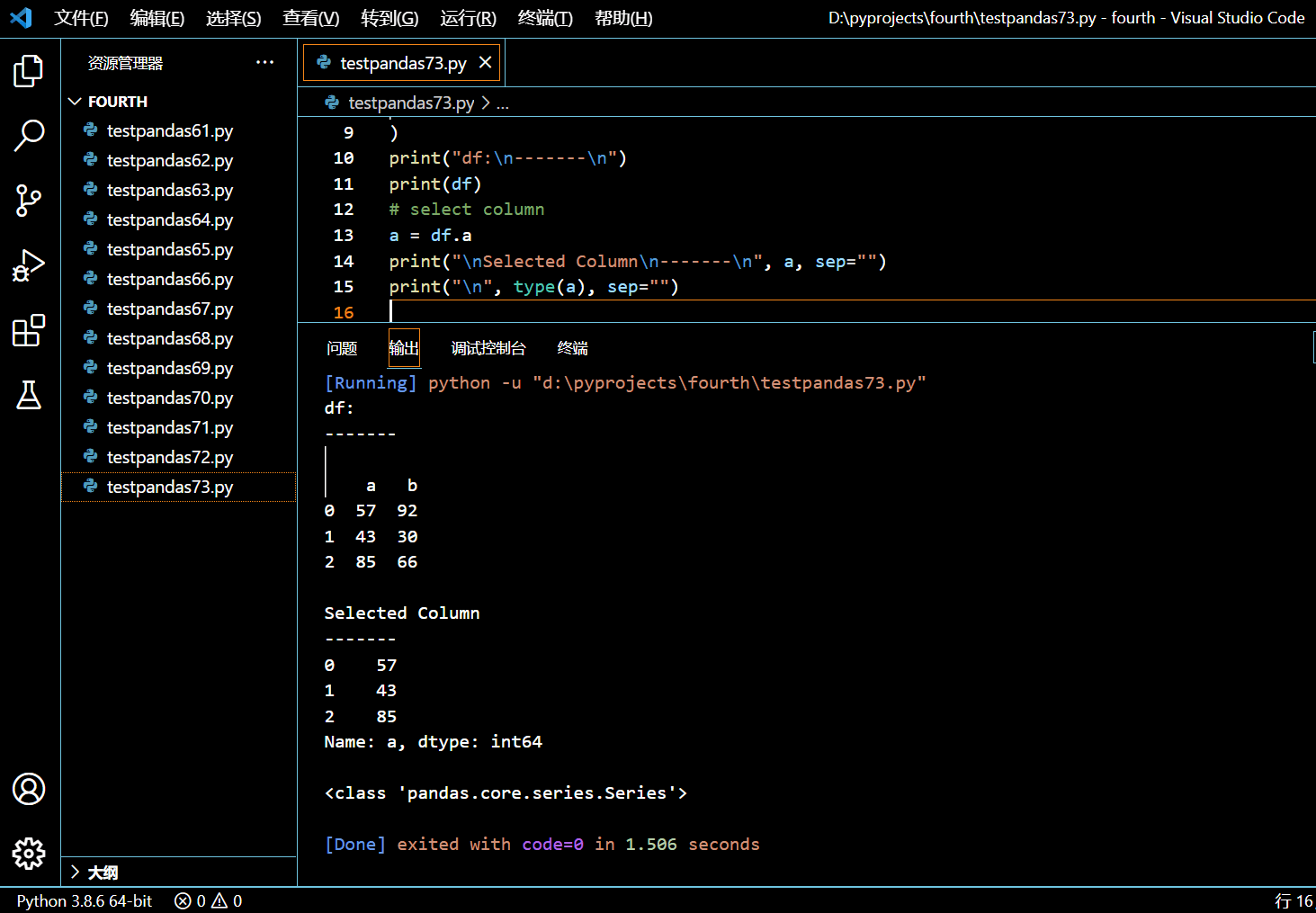
5.5.1. 使用点操作符选中一列
本示例中,我们将使用 . 操作符来从创建的 DataFrame 中选中一列,然后将其内容和数据类型打印。
import pandas as pd
# initialize dataframe
df = pd.DataFrame(
data={
'a': [57, 43, 85],
'b': [92, 30, 66]
}
)
print("df:\n-------\n")
print(df)
# select column
a = df.a
print("\nSelected Column\n-------\n", a, sep="")
print("\n", type(a), sep="")
执行和输出:
5.5.2. 使用中括号选中一列
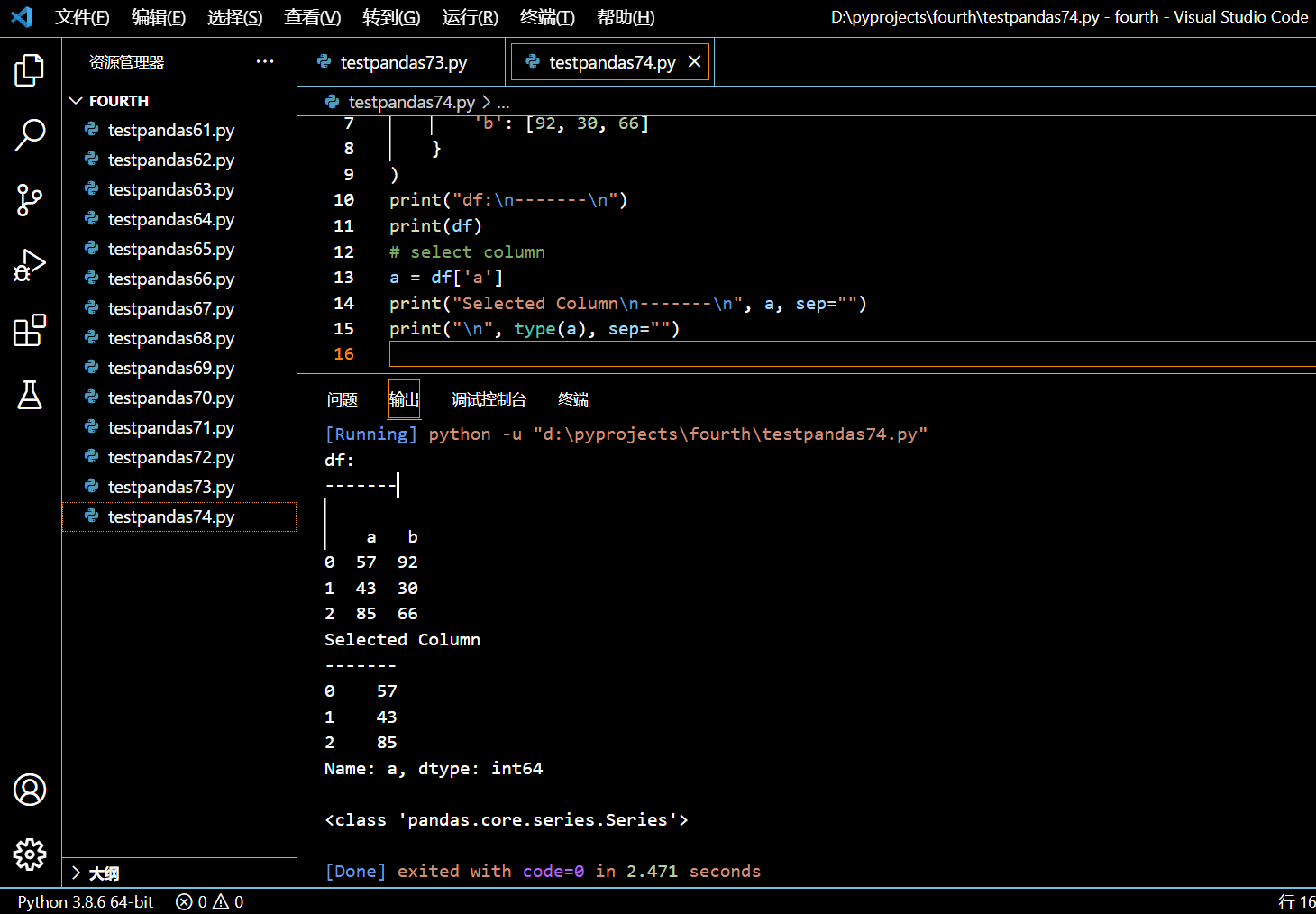
本示例中,我们将使用中括号 [] 来从 Pandas DataFrame 中选中一列数据。
import pandas as pd
# initialize dataframe
df = pd.DataFrame(
data={
'a': [57, 43, 85],
'b': [92, 30, 66]
}
)
print("df:\n-------\n")
print(df)
# select column
a = df['a']
print("Selected Column\n-------\n", a, sep="")
print("\n", type(a), sep="")
执行和输出:
可见中括号也可以选中某列。那么一般我们用点操作符还是中括号呢?推荐用中括号选择列,因为在某些特殊情况下,接下来的示例中会讨论,使用点操作符不起作用。
5.5.3. 选中列名与函数名冲突的列
接下来的示例中,我们将选择一个列名与函数名有冲突的列。
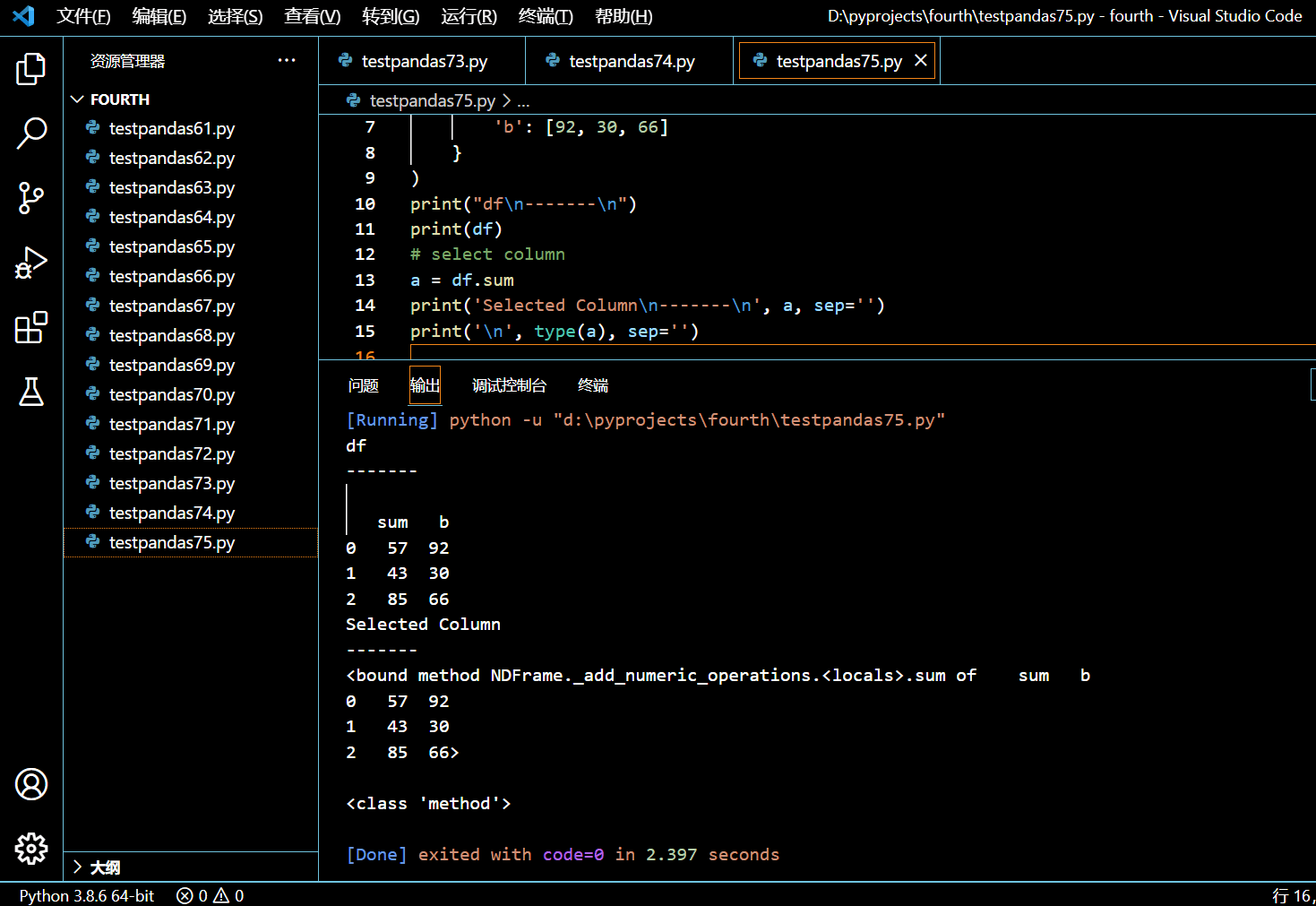
在这种场景下,使用点操作符返回的是一个 method 对象。
import pandas as pd
# initialize dataframe
df = pd.DataFrame(
data={
'sum': [57, 43, 85],
'b': [92, 30, 66]
}
)
print("df\n-------\n")
print(df)
# select column
a = df.sum
print('Selected Column\n-------\n', a, sep='')
print('\n', type(a), sep='')
执行和输出:
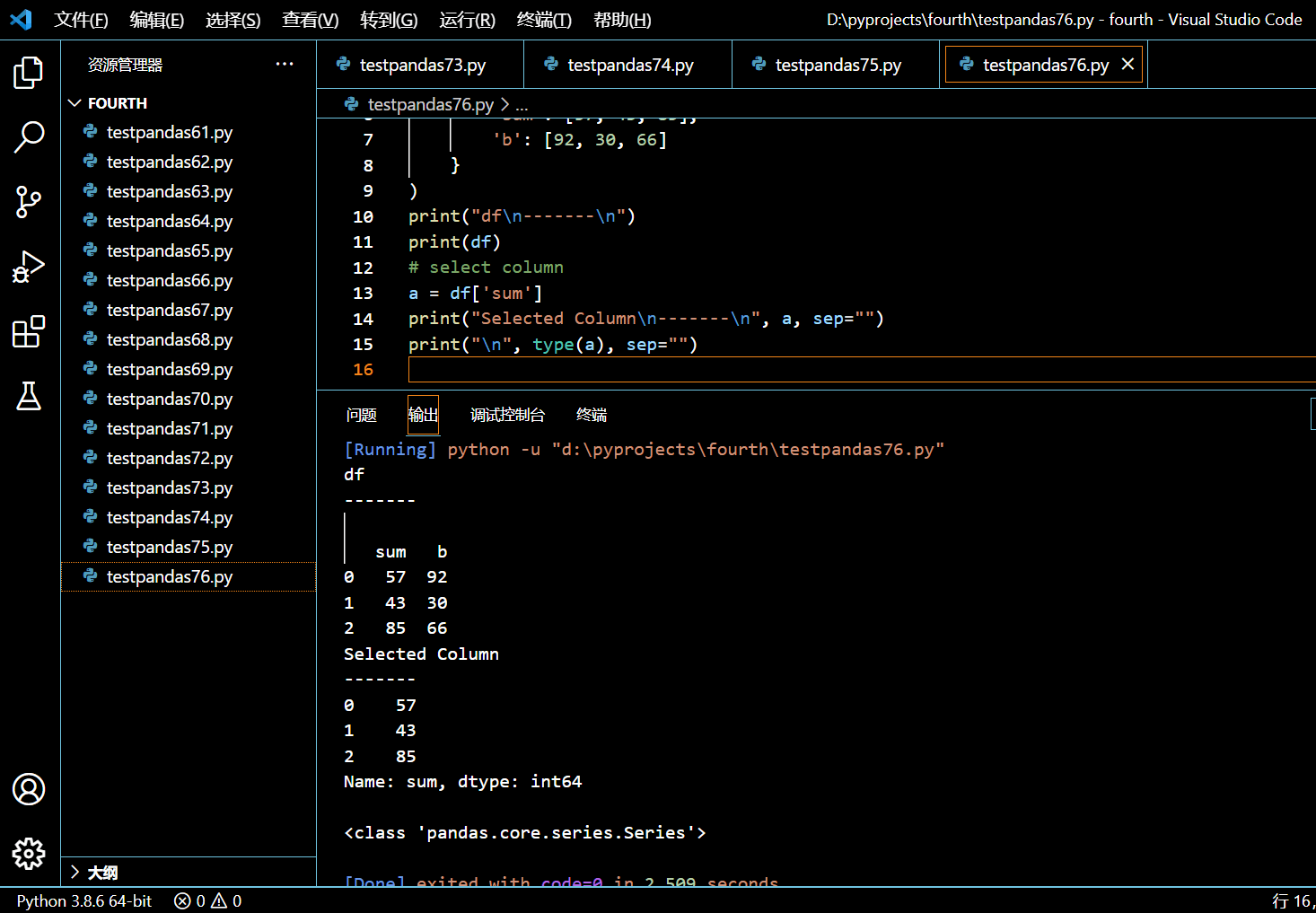
同样数据,用中括号的话则会选中一列并返回 Series:
import pandas as pd
# initialize dataframe
df = pd.DataFrame(
data={
'sum': [57, 43, 85],
'b': [92, 30, 66]
}
)
print("df\n-------\n")
print(df)
# select column
a = df['sum']
print("Selected Column\n-------\n", a, sep="")
print("\n", type(a), sep="")
执行和输出:
5.5.4. 选中列名中有空格的列
接下来的示例中,我们将选择列名中有空格的一列。
在这种场景下,使用点操作符会抛出 SyntaxError。
import pandas as pd
# initialize dataframe
df = pd.DataFrame(
data={
'a': [57, 43, 85],
'b': [92, 30, 66],
'sum a b': [149, 73, 151]
}
)
print("df\n-------\n")
print(df)
# select column
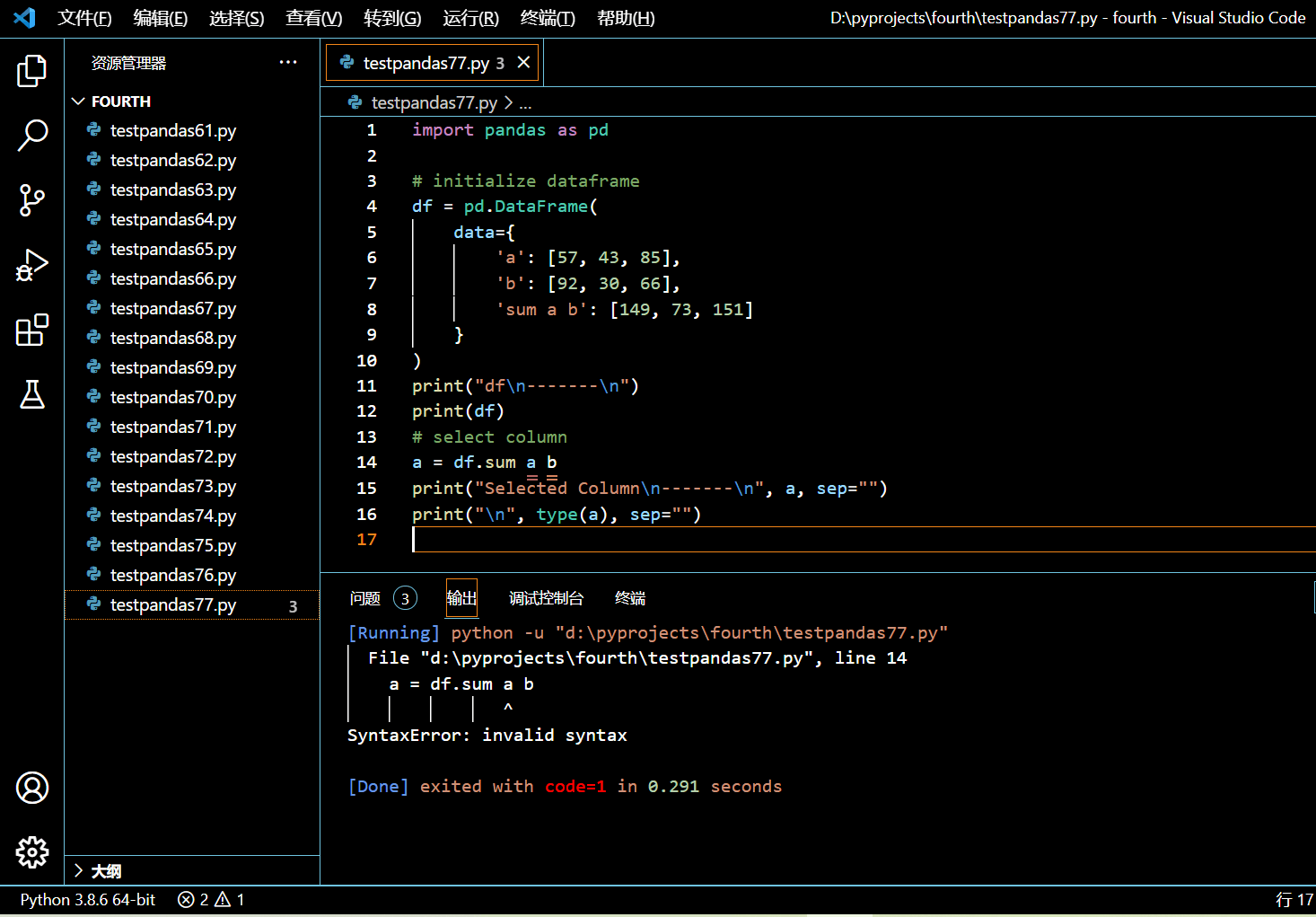
a = df.sum a b
print("Selected Column\n-------\n", a, sep="")
print("\n", type(a), sep="")
执行和输出:
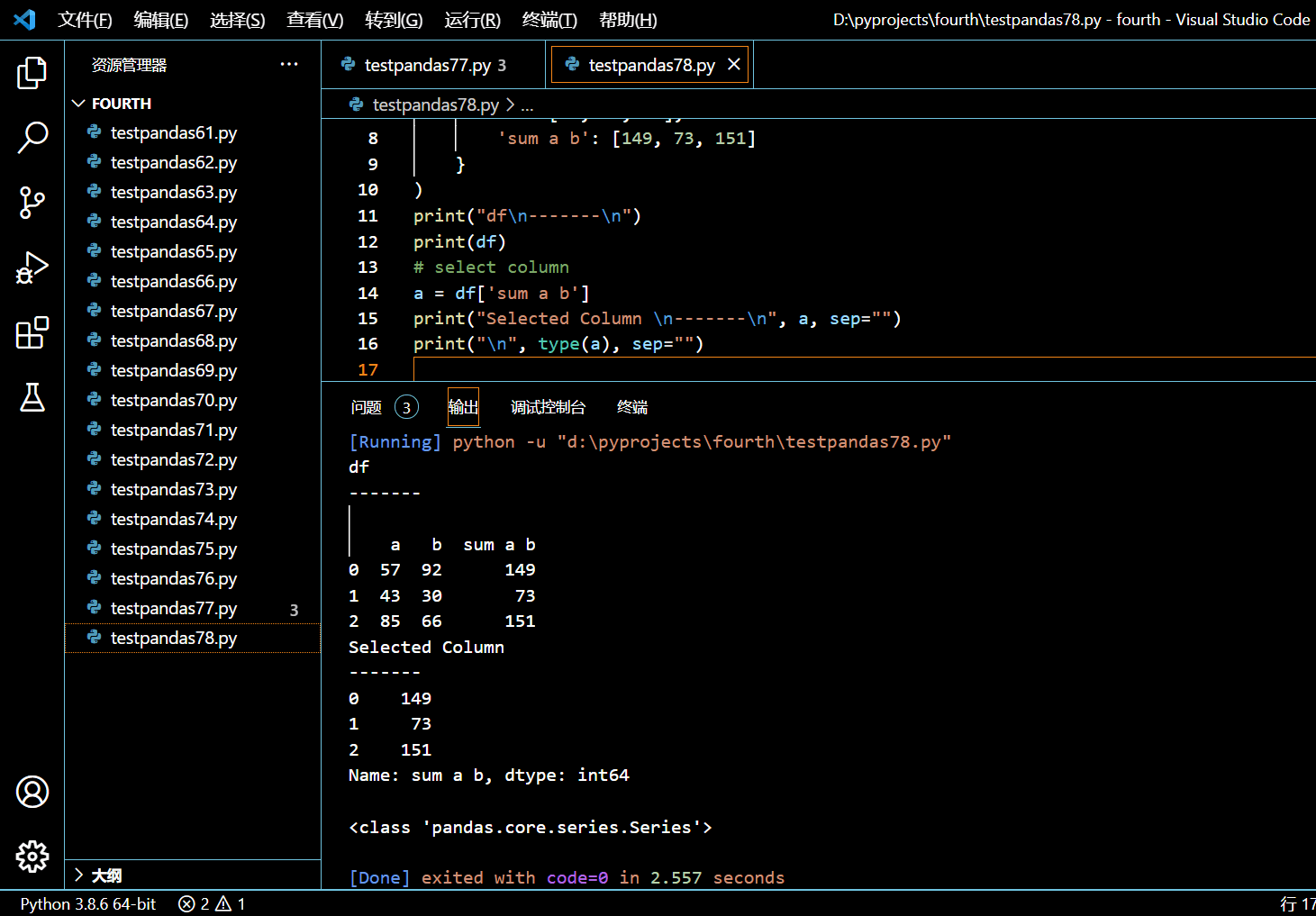
使用中括号则可以选中带有空格的列,并返回 Series:
import pandas as pd
#initialize dataframe
df = pd.DataFrame(
data={
'a': [57, 43, 85],
'b': [92, 30, 66],
'sum a b': [149, 73, 151]
}
)
print("df\n-------\n")
print(df)
# select column
a = df['sum a b']
print("Selected Column \n-------\n", a, sep="")
print("\n", type(a), sep="")
执行和输出:
5.5.5. 小结
本节中我们了解到了如何选中 Pandas DataFrame 里的一列。
5.6. 如何从 DataFrame 获取数字类型的列?
要从一个 Pandas DataFrame 中获取只有数字类型数据的列,可以调用方法 DataFrame.select_dtypes(),将参数 np.number 或 'number' 传递给它的 include 参数即可。这个方法将返回只包含原有 DataFrame 数字列的一个子集。
调用 select_datatypes() 的语法如下:
DataFrame.select_dtypes(include=None, exclude=None)
5.6.1. 选取 DataFrame 的数字列
本示例中,我们将创建一个 DataFrame,然后使用 DataFrame.select_dtypes() 方法拿到它只包含数字类型的列。
import pandas as pd
df = pd.DataFrame(
data=[
['abc', 22, 22.6],
['xyz', 25, 23.2],
['pqr', 31, 30.5]
],
columns=['name', 'age', 'bmi']
)
print("df\n-------\n")
print(df)
result = df.select_dtypes(include="number")
print("result\n-------\n")
print(result)
执行和输出:
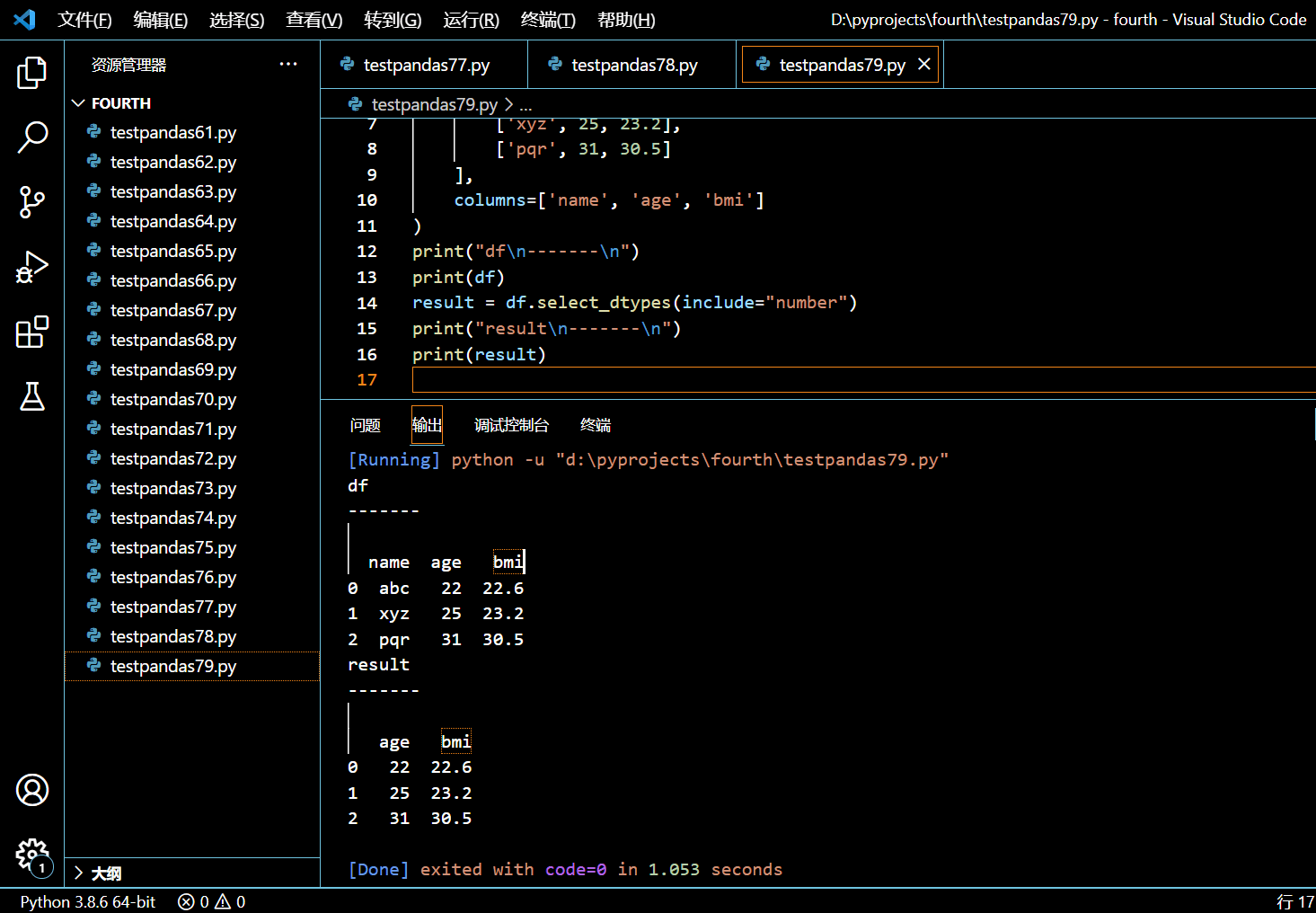
可见只有数字类型的列被从 DataFrame 中选了出来。
5.6.2. 小结
通过本文的示例,我们了解到了如何通过 DataFrame.select_dtypes() 方法将 DataFrame 中的数字类型的列选出来。
5.7. 如何根据某列对 DataFrame 进行排序?
要根据某一列对一个 DataFrame 里的行进行排序,可以使用 pandas.DataFrame.sort_values() 方法,传给它 by=column_name 参数即可。sort_values() 方法并不会修改原来的 DataFrame,它只是返回排序后的 DataFrame。可以根据排序列的值对 DataFrame 进行正序或逆序排列。
5.7.1. 根据某列对 DataFrame 进行正序排序
sort_values() 函数默认的排序方式为正序排序。以下示例中,我们将新建一个 DataFrame,然后根据指定列对其进行正序排序。
import pandas as pd
data = {
'name': ['Somu', 'Kiku', 'Amol', 'Lini'],
'physics': [68, 74, 77, 78],
'chemistry': [84, 56, 73, 69],
'algebra': [78, 88, 82, 87]
}
# create dataframe
df_marks = pd.DataFrame(data=data)
print("df_marks\n------\n")
print(df_marks)
# sort dataframe
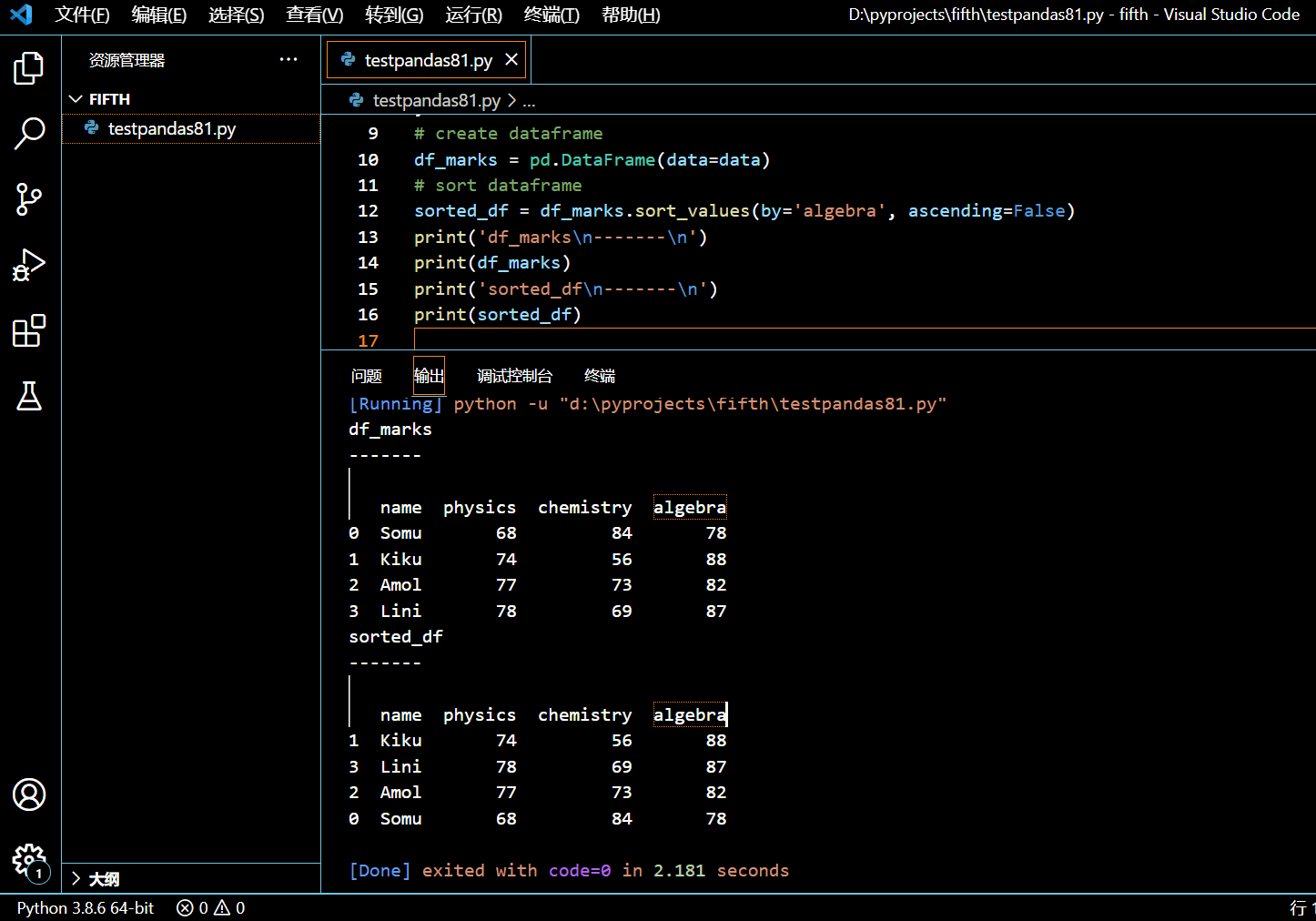
sorted_df = df_marks.sort_values(by='algebra')
print("sorted_df\n-------\n")
print(sorted_df)
执行和输出:
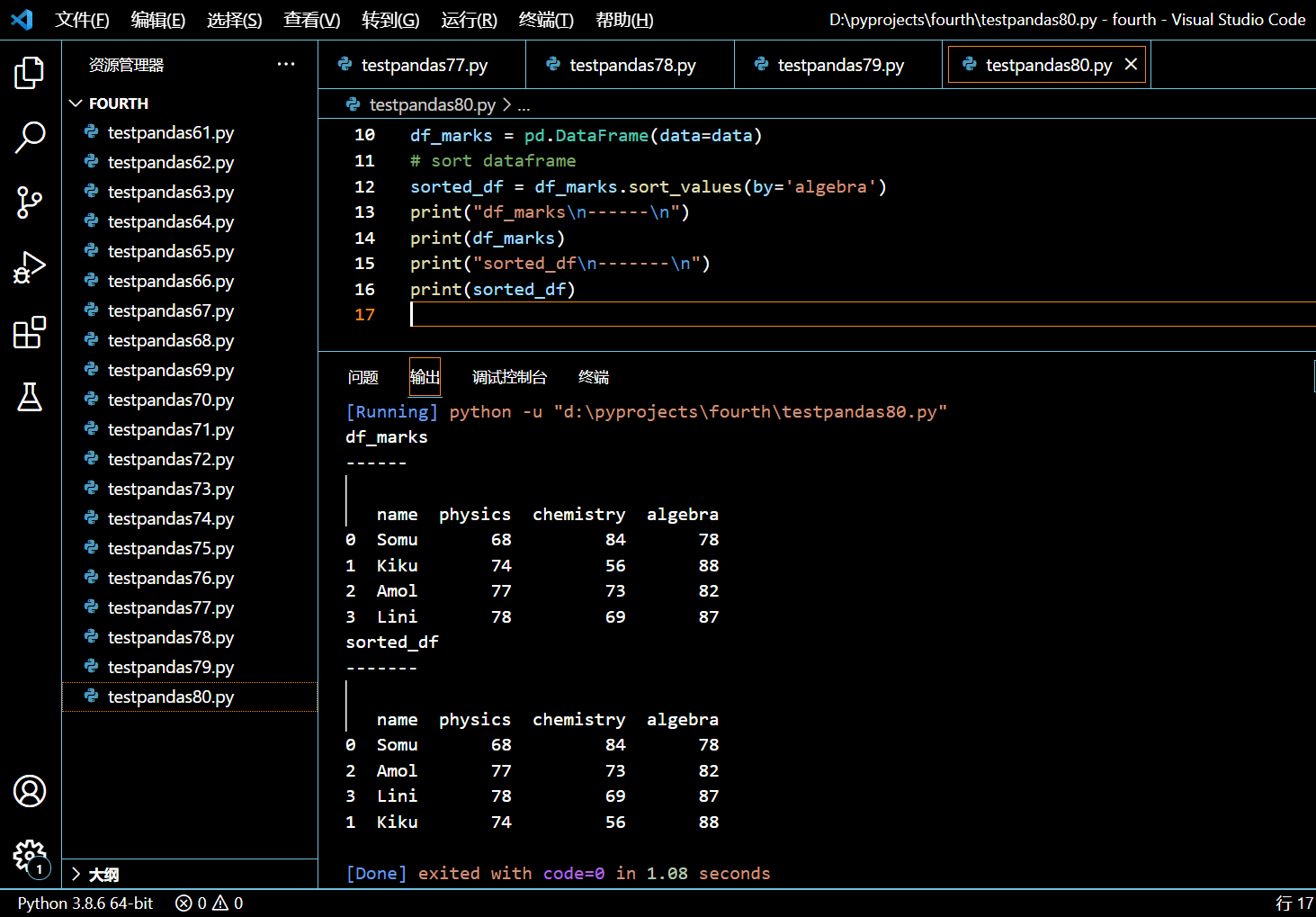
可见,sort_values() 函数返回的是根据 algebra 列正序排序以后的 DataFrame,而原来的 DataFrame 没有改动。
5.7.2. 根据某列对 DataFrame 进行逆序排序
要正序排序的话,只需将 ascending=False 参数传递给 sort_values() 方法。本示例中,我们将新建一个 DataFrame 然后根据指定列对其进行逆序排序。
import pandas as pd
data = {
'name': ['Somu', 'Kiku', 'Amol', 'Lini'],
'physics': [68, 74, 77, 78],
'chemistry': [84, 56, 73, 69],
'algebra': [78, 88, 82, 87]
}
# create dataframe
df_marks = pd.DataFrame(data=data)
# sort dataframe
sorted_df = df_marks.sort_values(by='algebra', ascending=False)
print('df_marks\n-------\n')
print(df_marks)
print('sorted_df\n-------\n')
print(sorted_df)
执行和输出:
可见,sort_values() 函数返回的是根据 algebra 列逆序排序以后的 DataFrame,而原来的 DataFrame 没有改动。
5.7.3. 小结
本节中,我们通过详细示例,了解到了如何使用 sort_values() 方法对 DataFrame 进行正序或逆序排序。
5.8. 如何给 DataFrame 添加列?
要给现有的 Pandas DataFrame 添加一个新列,以新列名作为索引直接将其分配给 DataFrame 即可。
5.8.1. 语法 - 添加列
给 DataFrame 添加一列的语法如下:
mydataframe['new_column_name'] = column_values
其中,mydataframe 是要添加新列的 DataFrame,而 new_column_name 则是需要添加的新列的列标签。你可以以一个列表来供给所有的列值;也可以只提供单个值,以其作为提供给所有行新列的默认值。
5.8.2. 给 Pandas DataFrame 添加列
本示例中,我们将新建一个 DataFrame df_marks,然后添加一个列名为 geometry 的新列给它。
import pandas as pd
mydictionary = {
'names': ['Somu', 'Kiku', 'Amol', 'Lini'],
'physics': [68, 74, 77, 78],
'chemistry': [84, 56, 73, 69],
'algebra': [78, 88, 82, 87]
}
# create dataframe
df_marks = pd.DataFrame(data=mydictionary)
print('Original DataFrame\n-------')
print(df_marks)
# add column
df_marks['geometry'] = [81, 92, 67, 76]
print('\n\nDataFrame after adding "geometry" column\n-------')
print(df_marks)
执行和输出:
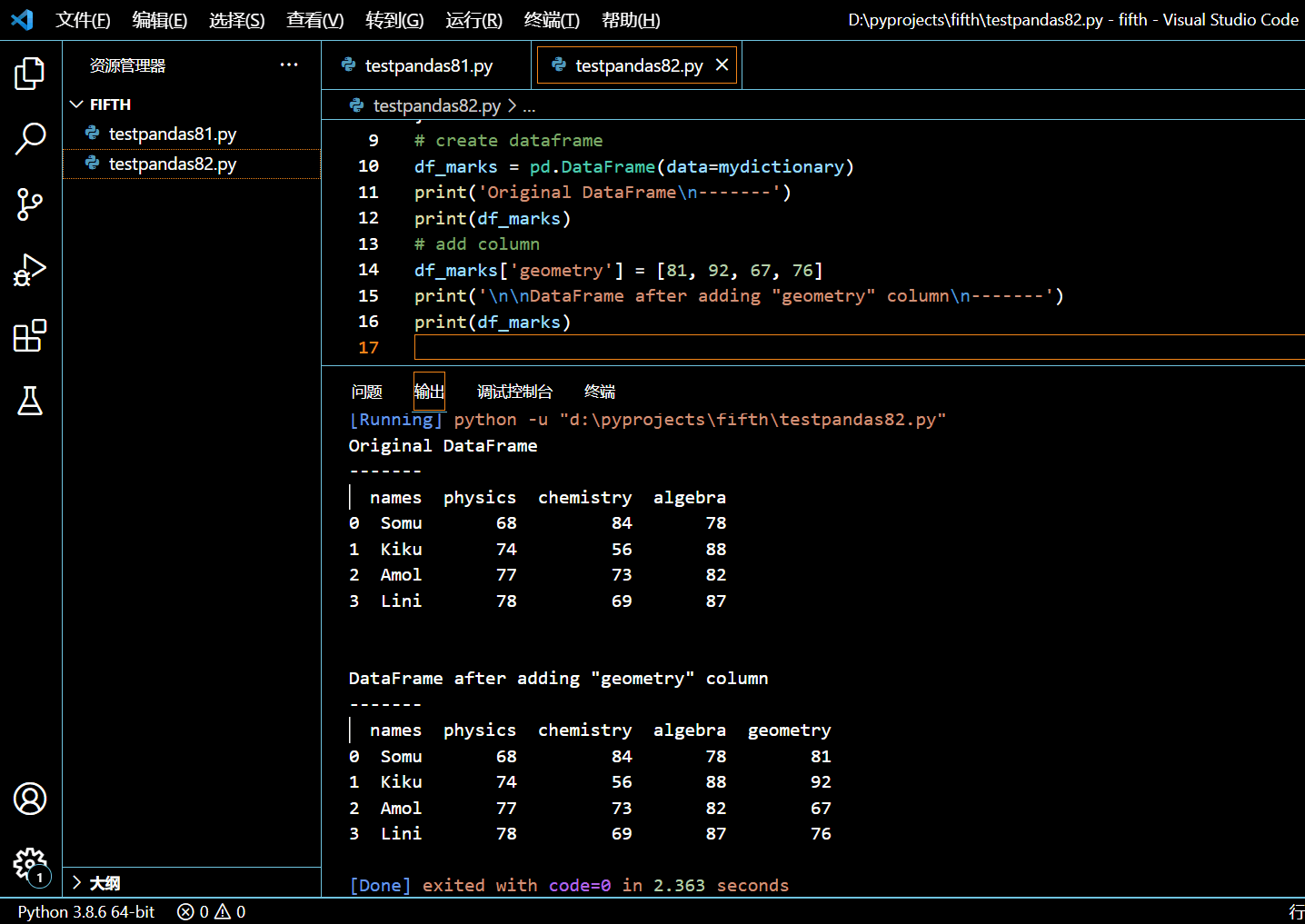
可见以指定列表为列值的列已被添加到 DataFrame。
需注意,你提供的列表的长度,必须和该 DataFrame 的行数相等,否则的话你会碰到类似于以下的错误:
ValueError: Length of values does not match length of index
5.8.3. 给 Pandas DataFrame 添加统一默认值的列
在接下来的示例中,我们将新建一个名为 df_marks 的 DataFrame,然后给它添加列名为 geometry 的新列,该列所有的行均为同一个默认值。
import pandas as pd
mydictionary = {
'names': ['Somu', 'Kiku', 'Amol', 'Lini'],
'physics': [68, 74, 77, 78],
'chemistry': [84, 56, 73, 69],
'algebra': [78, 88, 82, 87]
}
# create dataframe
df_marks = pd.DataFrame(data=mydictionary)
print('Original DataFrame\n-------')
print(df_marks)
# add column
df_marks['geometry'] = 65
print('\n\nDataFrame after adding "geometry" column\n-------')
print(df_marks)
执行和输出:
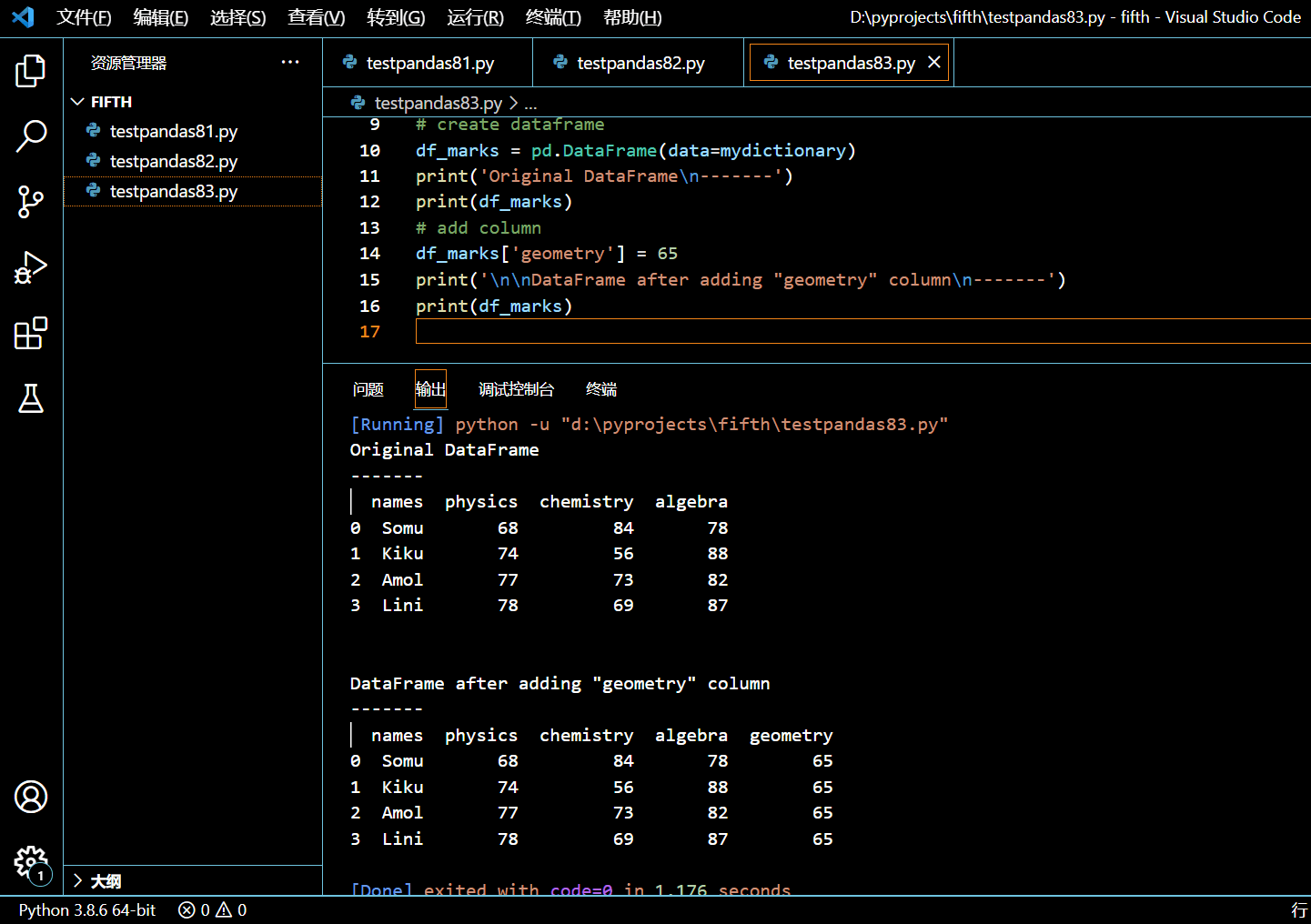
可见新加的那列统一为指定值。
5.8.4. 小结
本节我们了解到了如何向 Pandas DataFrame 新加一列。
5.9. 怎样删除 Pandas DataFrame 的列?
你可以删除一个 DataFrame 的单列或多列。
要删除 Pandas DataFrame 的单个列,可以使用 del 关键字,或者使用该 DataFrame 的 pop() 或 drop() 函数。
要删除 Pandas DataFrame 的多个列,可以使用该 DataFrame 的 drop() 函数。
5.9.1. 使用 del 关键字删除一列
本示例中,我们将新建一个 DataFrame,然后使用 del 关键字将一个指定列删除。要删除的列使用列标签选中。
import pandas as pd
mydictionary = {
'names': ['Somu', 'Kiku', 'Amol', 'Lini'],
'physics': [68, 74, 77, 78],
'chemistry': [84, 56, 73, 69],
'algebra': [78, 88, 82, 87]
}
# create dataframe
df_marks = pd.DataFrame(data=mydictionary)
print('Original DataFrame\n-------')
print(df_marks)
# delete a column
del df_marks['chemistry']
print('\n\nDataFrame after deleting column\n-------')
print(df_marks)
执行和输出:
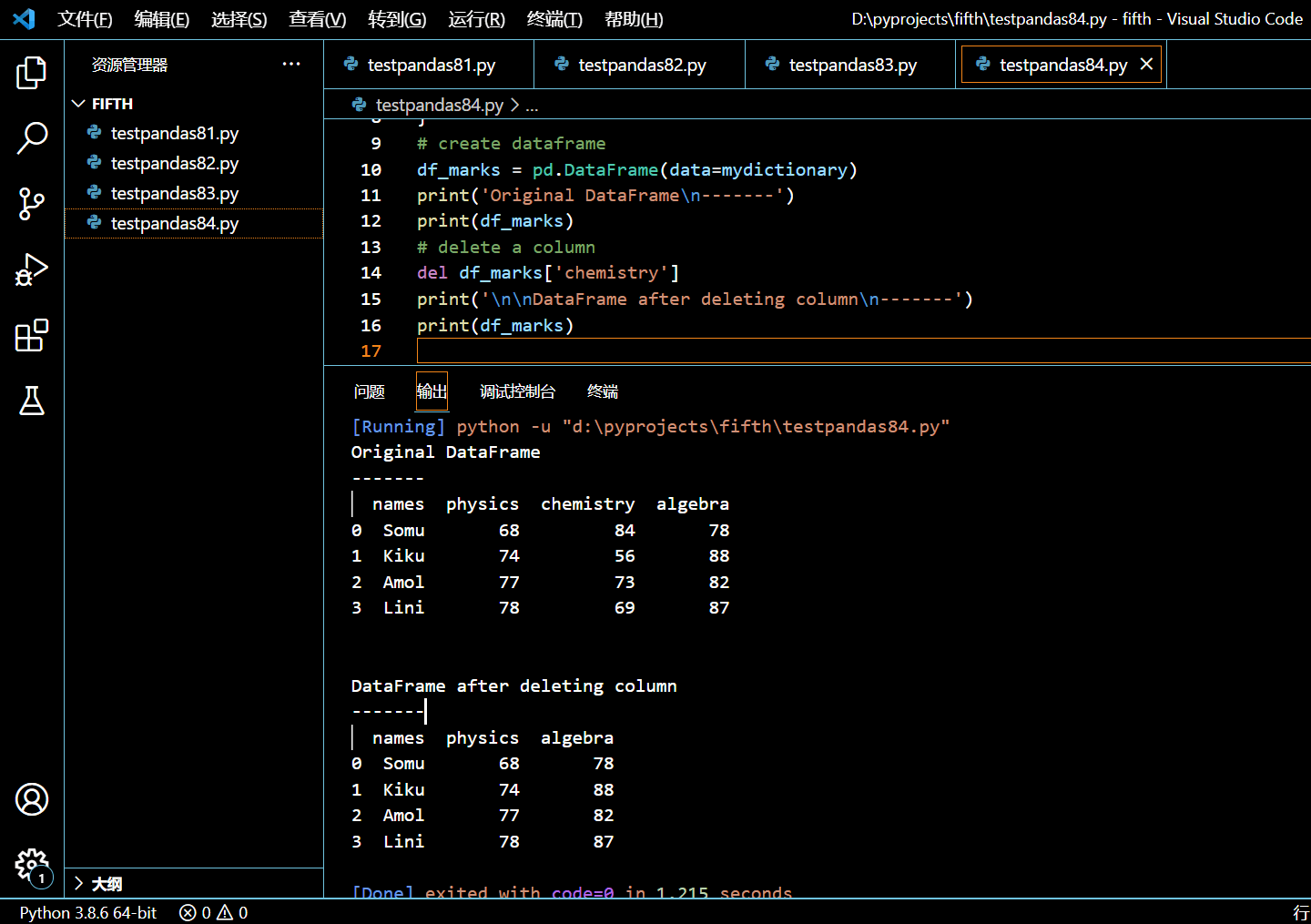
可见我们已经删除了该 DataFrame 的 chemistry 列。
5.9.2. 使用 pop() 函数删除一列
在接下来的示例中,我们将新建一个 DataFrame,然后使用它的 pop() 函数来删除指定列。同样,该列还是使用列标签选中。
import pandas as pd
mydictionary = {
'names': ['Somu', 'Kiku', 'Amol', 'Lini'],
'physics': [68, 74, 77, 78],
'chemistry': [84, 56, 73, 69],
'algebra': [78, 88, 82, 87]
}
# create dataframe
df_marks = pd.DataFrame(data=mydictionary)
print('Original DataFrame\n-------')
print(df_marks)
# delete column
df_marks.pop(item='chemistry')
print('\n\nDataFrame after deleting column\n-------')
print(df_marks)
执行和输出:
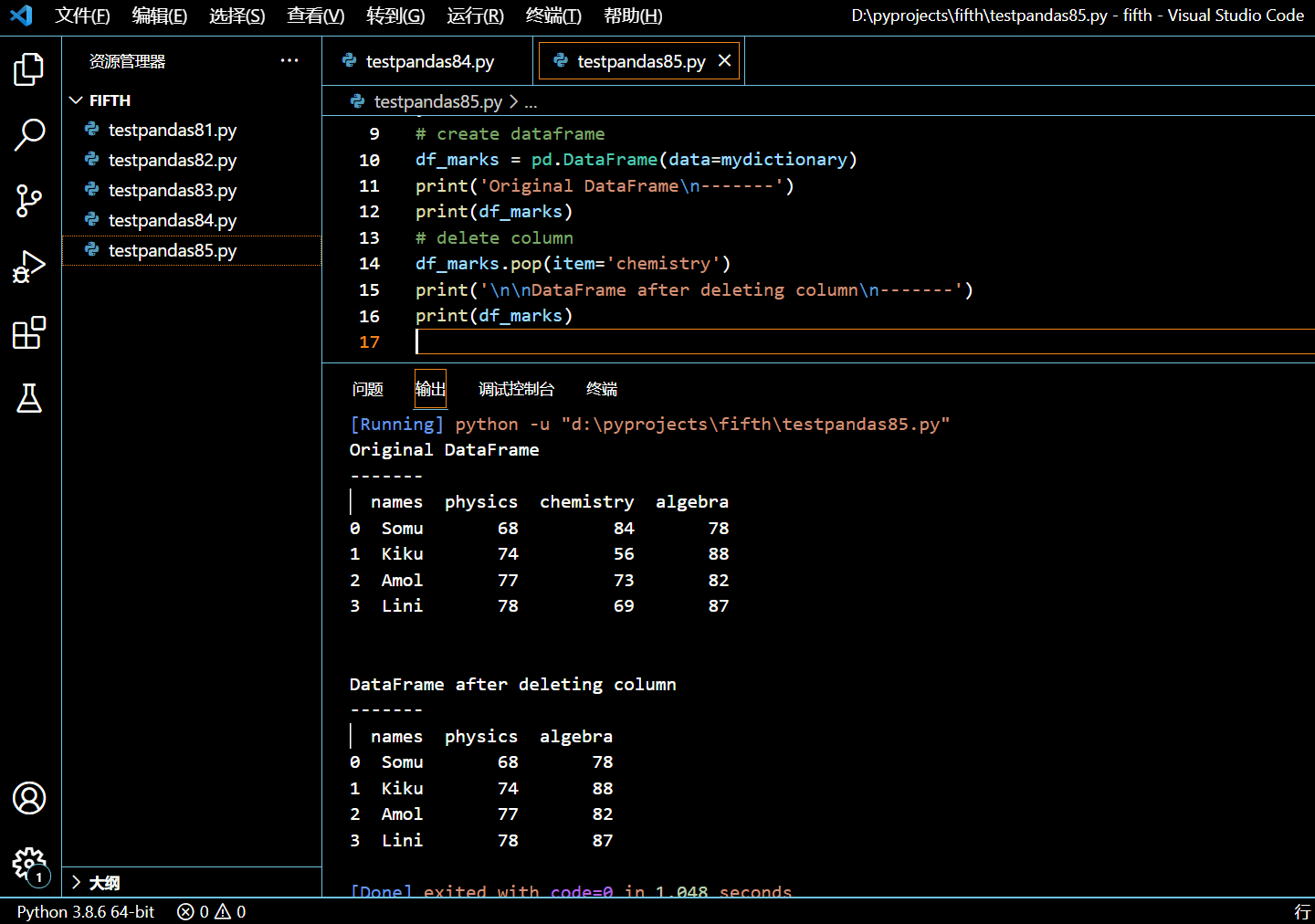
可见 chemistry 列已被从 DataFrame 中删除。
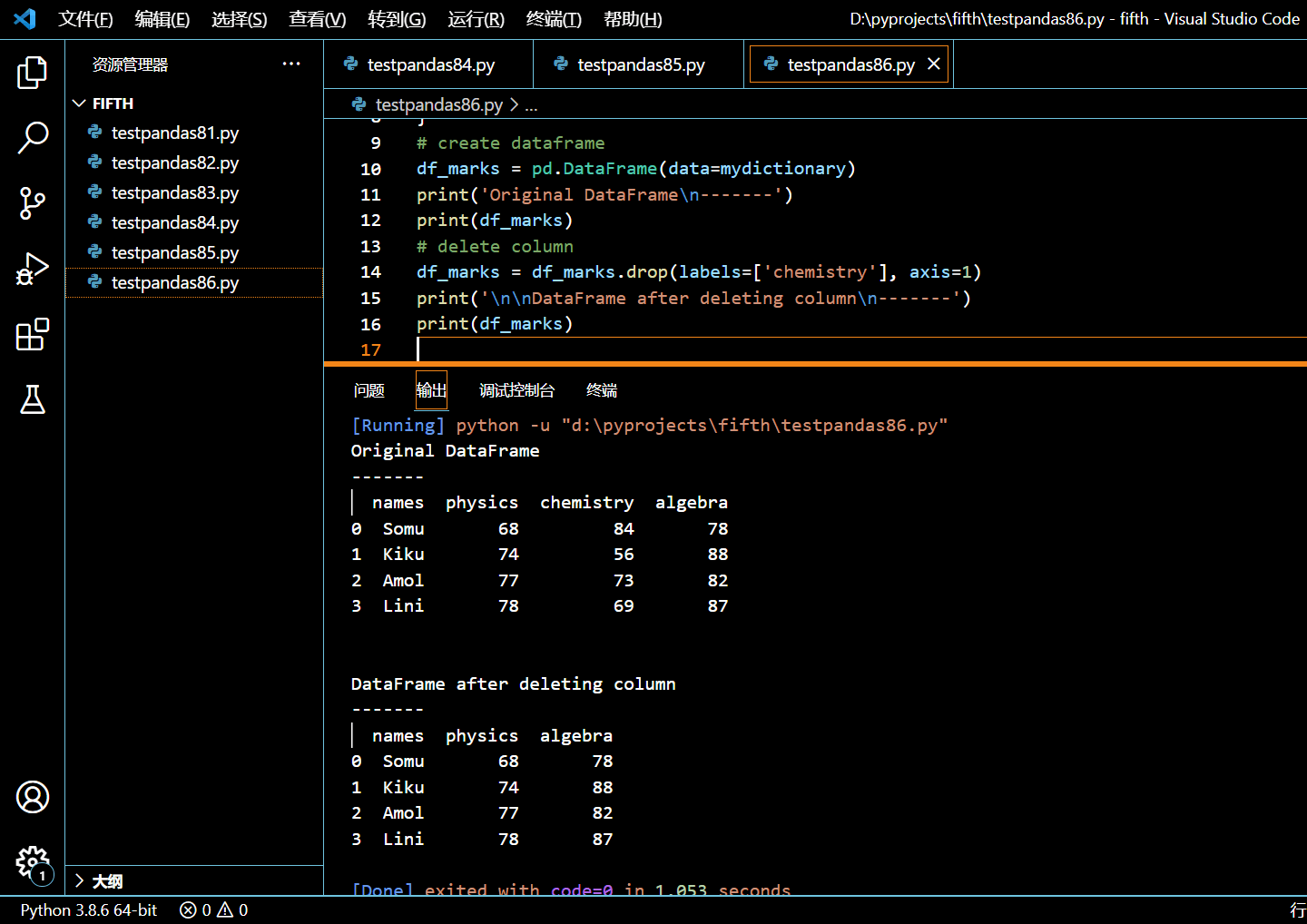
5.9.3. 使用 drop() 函数删除一列
本示例中,我们将使用 DataFrame 的 drop() 函数来删除指定列。我们仍然使用列标签来选中要删除的那一列。
import pandas as pd
mydictionary = {
'names': ['Somu', 'Kiku', 'Amol', 'Lini'],
'physics': [68, 74, 77, 78],
'chemistry': [84, 56, 73, 69],
'algebra': [78, 88, 82, 87]
}
# create dataframe
df_marks = pd.DataFrame(data=mydictionary)
print('Original DataFrame\n-------')
print(df_marks)
# delete column
df_marks = df_marks.drop(labels=['chemistry'], axis=1)
print('\n\nDataFrame after deleting column\n-------')
print(df_marks)
执行和输出:
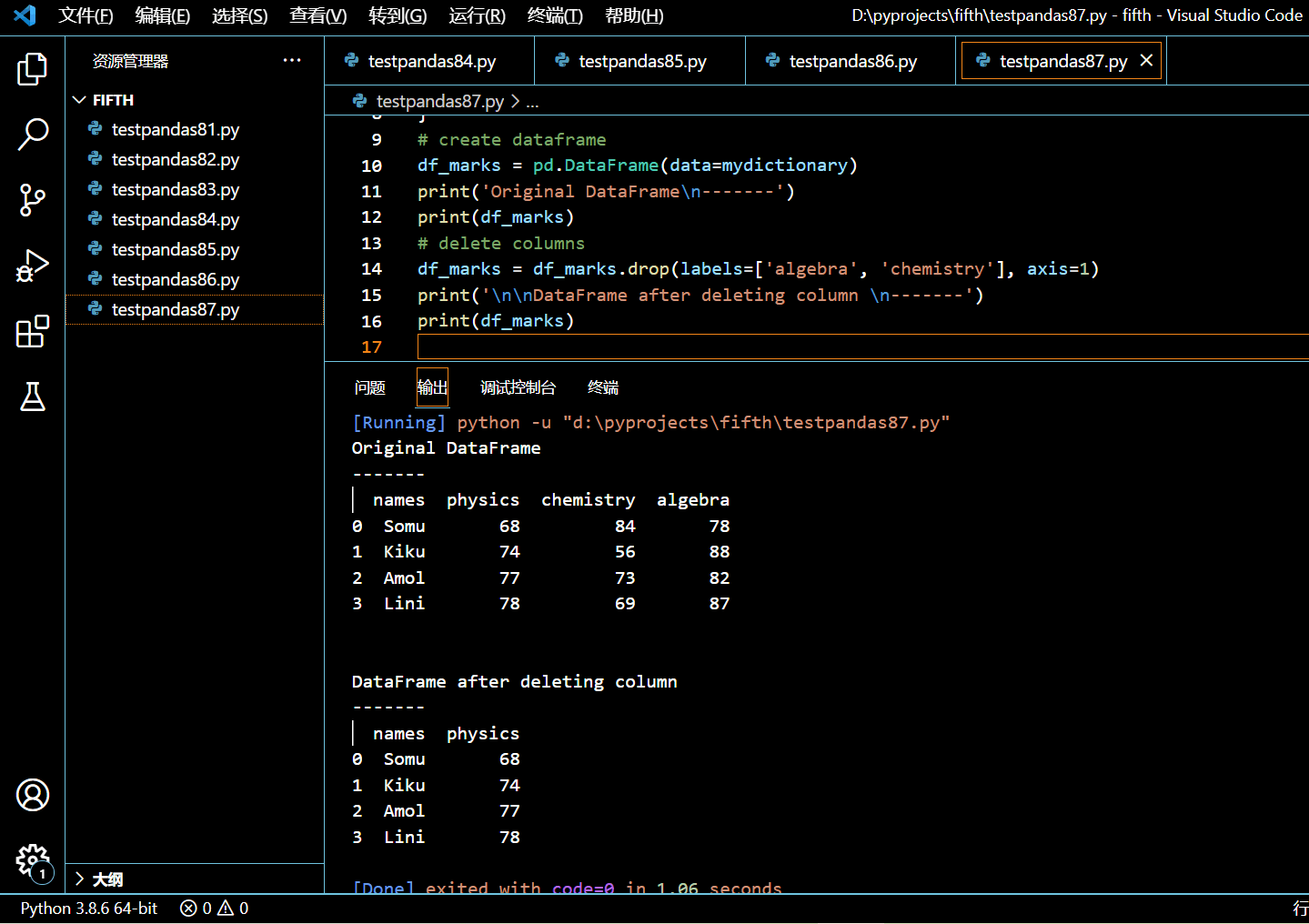
5.9.4. 使用 drop() 函数删除多列
在接下来的示例中,我们将使用 DataFrame 的 drop() 函数来删除多个列。我们将使用列标签的一个列表来选中要删除的列。
import pandas as pd
mydictionary = {
'names': ['Somu', 'Kiku', 'Amol', 'Lini'],
'physics': [68, 74, 77, 78],
'chemistry': [84, 56, 73, 69],
'algebra': [78, 88, 82, 87]
}
# create dataframe
df_marks = pd.DataFrame(data=mydictionary)
print('Original DataFrame\n-------')
print(df_marks)
# delete columns
df_marks = df_marks.drop(labels=['algebra', 'chemistry'], axis=1)
print('\n\nDataFrame after deleting column \n-------')
print(df_marks)
执行和输出:
5.9.5. 小结
在本文的示例中,我们了解到了如何使用 del 关键字、DataFrame 的 pop() 和 drop() 方法来删除 Pandas DataFrame 的列。
5.10. 如何将 Pandas DataFrame 的某列设置为索引?
在默认情况下,DataFrame 会自行创建一个索引。但是,如果有需要的话,你也可以手工设置指定列为 DataFrame 的索引。
可以使用 DataFrame.set_index() 函数为一个 DataFrame 设置某列为索引,将列名作为参数传递给它即可。
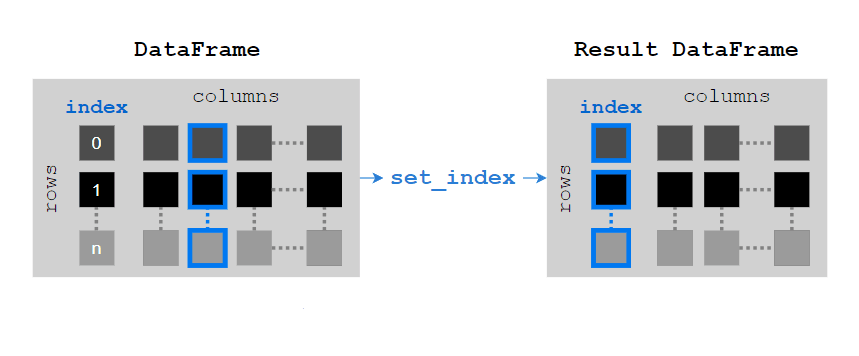
你也可以在索引设置时选择多列作为 MultiIndex(多重索引)。这时,你需要将多个列名组成的列表作为参数传递给 set_index() 方法。
5.10.1. set_index() 的语法
使用 set_index() 来设置某列为索引的语法如下:
myDataFrame.set_index('column_name')
其中,myDataFrame 是你要操作的 DataFrame,而 column_name 则是你要设置为索引的那列。
要设置 MultiIndex,可以遵循如下语法:
myDataFrame.set_index(['column_name_1', column_name_2])
你可以根据需要设置任意数量的列名。
请注意,set_index() 方法并不会修改原来的 DataFrame 对象,它会返回以设置列为索引的一个新的 DataFrame 对象。
5.10.2. 将 Pandas DataFrame 的某列设置为索引
接下来的示例中,我们将初始化一个 DataFrame,然后将其中的一列设置为索引。
import pandas as pd
# initialize a dataframe
df = pd.DataFrame(
data=[
[21, 'Amol', 72, 67],
[23, 'Lini', 78, 69],
[32, 'Kiku', 74, 56],
[52, 'Ajit', 54, 76]
],
columns=['rollno', 'name', 'physics', 'botony']
)
print('DataFrame with default index\n', df)
# set column as index
df = df.set_index(keys='rollno')
print('\nDataFrame with column as index\n', df)
执行和输出:
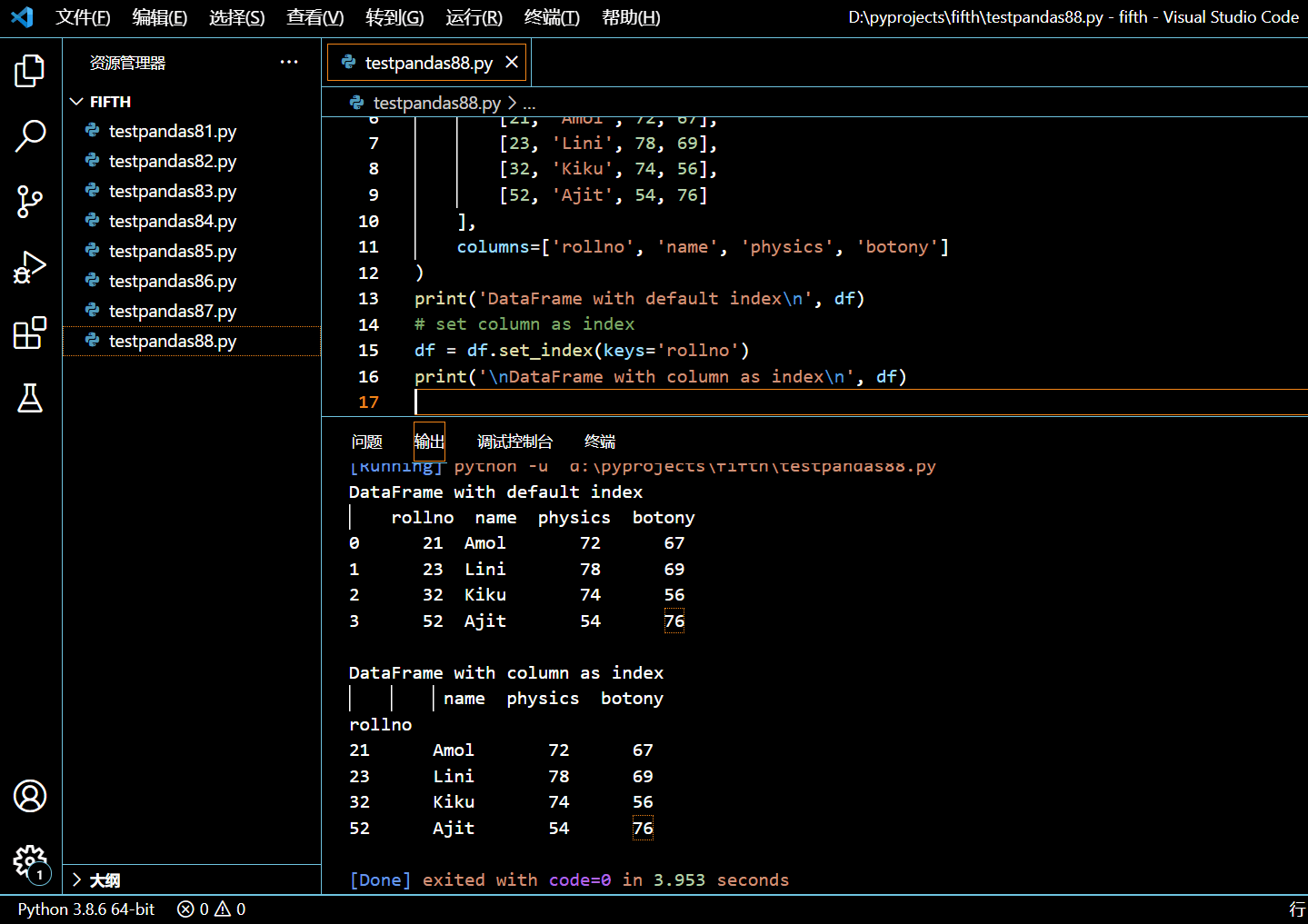
可见,DataFrame 的 rollno 列已经被设置为索引了。
注意,原始 DataFrame,有个独立的索引列(首列),该列没有列名。但在第二个 DataFrame 中,一个现成的列被作为索引,该列占据了第一列的位置。
5.10.3. 为 Pandas DataFrame 设置 MultiIndex(多重索引)
在接下来的示例中,我们将传递多个列名作为列表参数传递给 set_index() 方法来给 DataFrame 设置 MultiIndex。
import pandas as pd
# initialize a dataframe
df = pd.DataFrame(
data=[
[21, 'Amol', 72, 67],
[23, 'Lini', 78, 69],
[32, 'Kiku', 74, 56],
[52, 'Ajit', 54, 76]
],
columns=['rollno', 'name', 'physics', 'botony']
)
print('DataFrame with default index\n', df)
# set multiple columns as index
df = df.set_index(keys=['rollno', 'name'])
print('\nDataFrame with MultiIndex\n', df)
执行和输出:
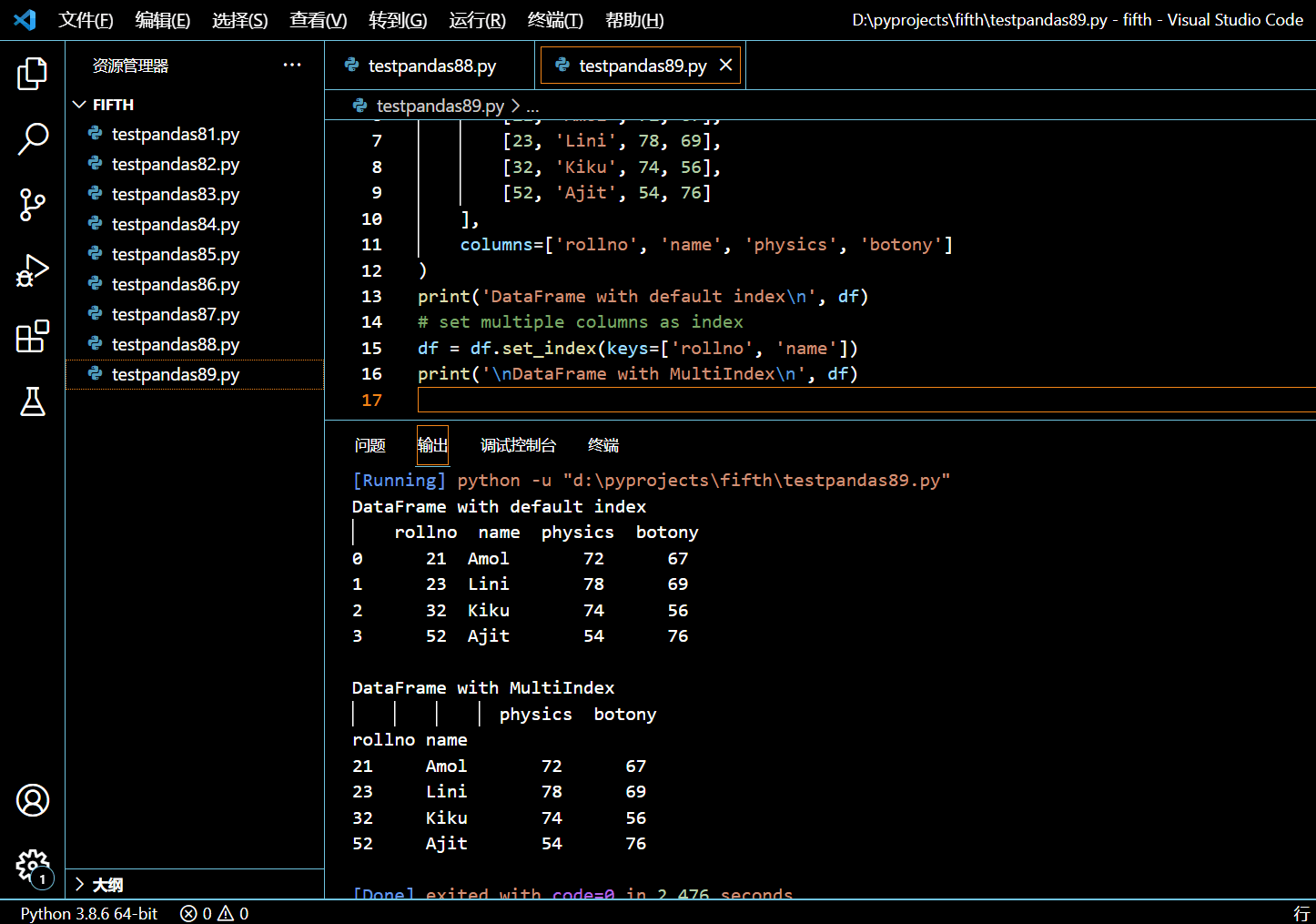
5.10.4. 小结
本节我们了解到了如何将指定列设置为 DataFrame 的索引。
5.11. 如何删除 Pandas DataFrame 的列?
可以使用 Pandas DataFrame.pop() 函数来从 DataFrame 删除一列。
5.11.1. 使用 Pandas pop() 函数来删除一列
在接下来的示例中,我们将根据列名使用 pop() 来删除 DataFrame 的指定列。Pandas 的 pop() 函数会直接修改原来的 DataFrame。也就是说,被删除列中的数据将会丢失。
import pandas as pd
mydictionary = {
'name': ['Somu', 'Kiku', 'Amol', 'Lini'],
'physics': [68, 74, 77, 78],
'chemistry': [84, 56, 73, 69],
'algebra': [78, 88, 82, 87]
}
# create dataframe
df_marks = pd.DataFrame(mydictionary)
print('Original DataFrame\n-------')
print(df_marks)
# delete column
df_marks.pop(item='algebra')
print('\n\nDataFrame after deleting column\n--------')
print(df_marks)
执行和输出:
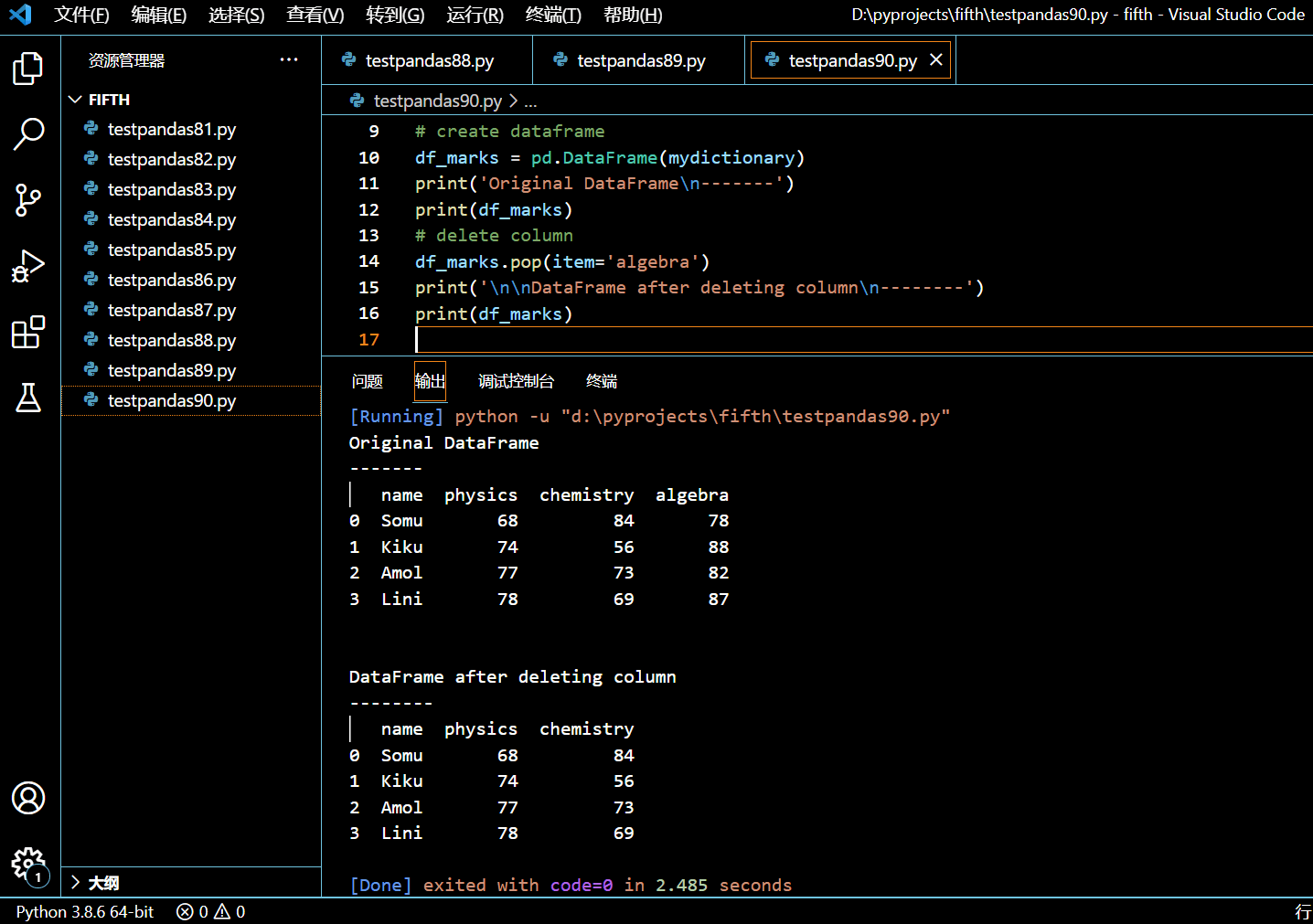
5.11.2. 使用 Pandas pop() 函数删除一个不存在的列
本示例中,我们来试着删除并不存在于 DataFrame 中的一列。
当你使用 pop() 来删除 DataFrame 中一个并不存在的列时,该函数将抛出 KeyError。
import pandas as pd
mydictionary = {
'names': ['Somu', 'Kiku', 'Amol', 'Lini'],
'physics': [68, 74, 77, 78],
'chemistry': [84, 56, 73, 69],
'algebra': [78, 88, 82, 87]
}
# create dataframe
df_marks = pd.DataFrame(data=mydictionary)
print('Original DataFrame\n-------')
print(df_marks)
# delete column that is not present
df_marks.pop(item='geometry')
print('\n\nDataFrame after deleting column\n-------')
print(df_marks)
执行和输出:
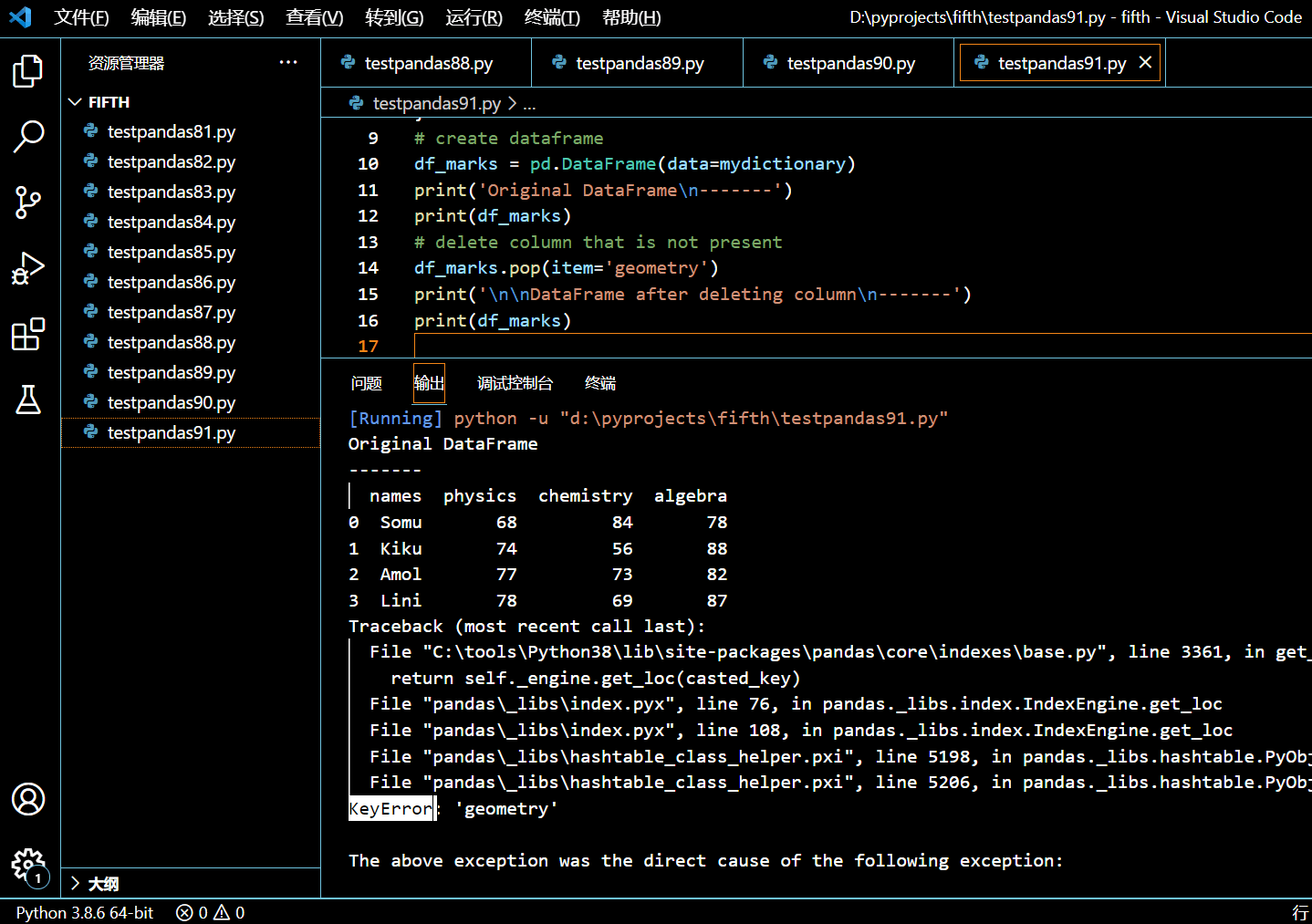
5.11.3. 小结
本节我们通过详尽示例了解到了如何使用 pop() 来删除 DataFrame 的一列。
5.12. 如何改变 Pandas DataFrame 列的数据类型?
要改变 DataFrame 列的数据类型,可以使用 DataFrame.astype() 方法,或者 DataFrame.infer_objects() 方法,或者 pd.to_numeric。
5.12.1. 用 DataFrame.astype() 改变列的数据类型
DataFrame.astype() 会将这个 DataFrame 转换到一个指定的数据类型,以下是它的语法:
astype(dtype, copy=True, errors='raise', **kwargs)
我们只关心第一个参数 dtype。dtype 可以是数据类型,也可以是字典 列名 -> 数据类型。
5.12.1.1. 修改一列的数据类型
在接下来的示例中,我们将把列 a 的数据类型改为 float。
import pandas as pd
import numpy as np
# initialize a dataframe
df = pd.DataFrame(
data=[
[21, 72, 67],
[23, 78, 62],
[32, 74, 54],
[52, 54, 76]
],
columns=['a', 'b', 'c']
)
print('Previous DataTypes\n', df.dtypes, sep='')
# change datatype of column
df = df.astype(dtype={'a': np.float})
# print results
print('\nNew Datatypes\n', df.dtypes, sep='')
print('\nDataFrame\n', df, sep='')
执行和输出:
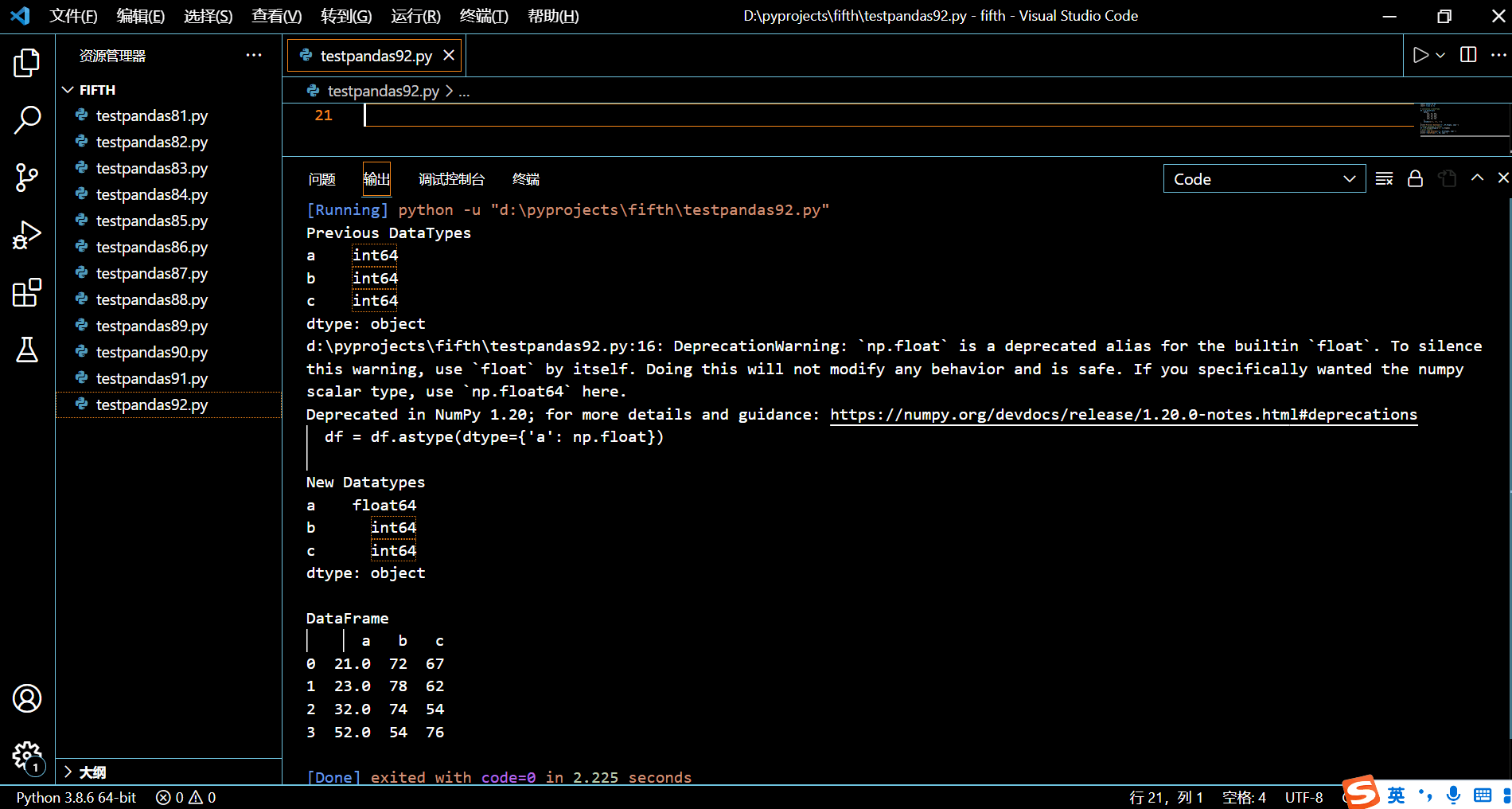
5.12.1.2. 修改多列的数据类型
现在我们来一次性修改多列的数据类型。
通过 astype() 的语法以及上面的示例,不难看出,修改多列只需要在该方法的 dtype 字典参数中多传递几个键值对即可。
在接下来的示例中,我们将把列 a 的数据类型改为 float64,把列 b 的数据类型改为 int8。
import pandas as pd
import numpy as np
# initialize a dataframe
df = pd.DataFrame(
data=[
[21, 72, 67],
[23, 78, 62],
[32, 74, 54],
[52, 54, 76]
],
columns=['a', 'b', 'c']
)
print('Previous Datatypes\n', df.dtypes, sep='')
# change datatype of column
df = df.astype(dtype={'a': np.float64, 'b': np.int8})
# print results
print('\nNew Datatypes\n', df.dtypes, sep='')
print('\nDataFrame\n', df, sep='')
执行和输出:
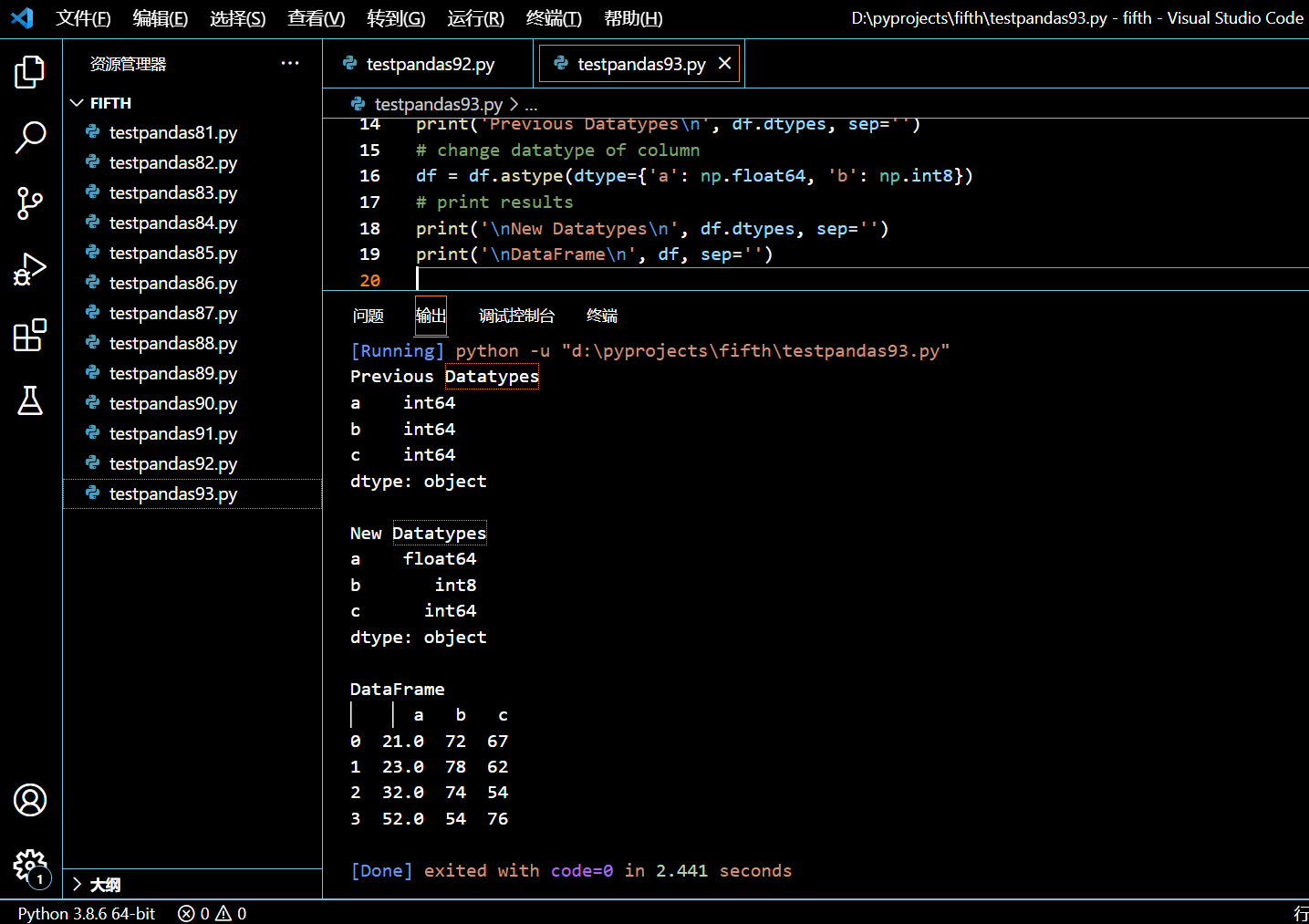
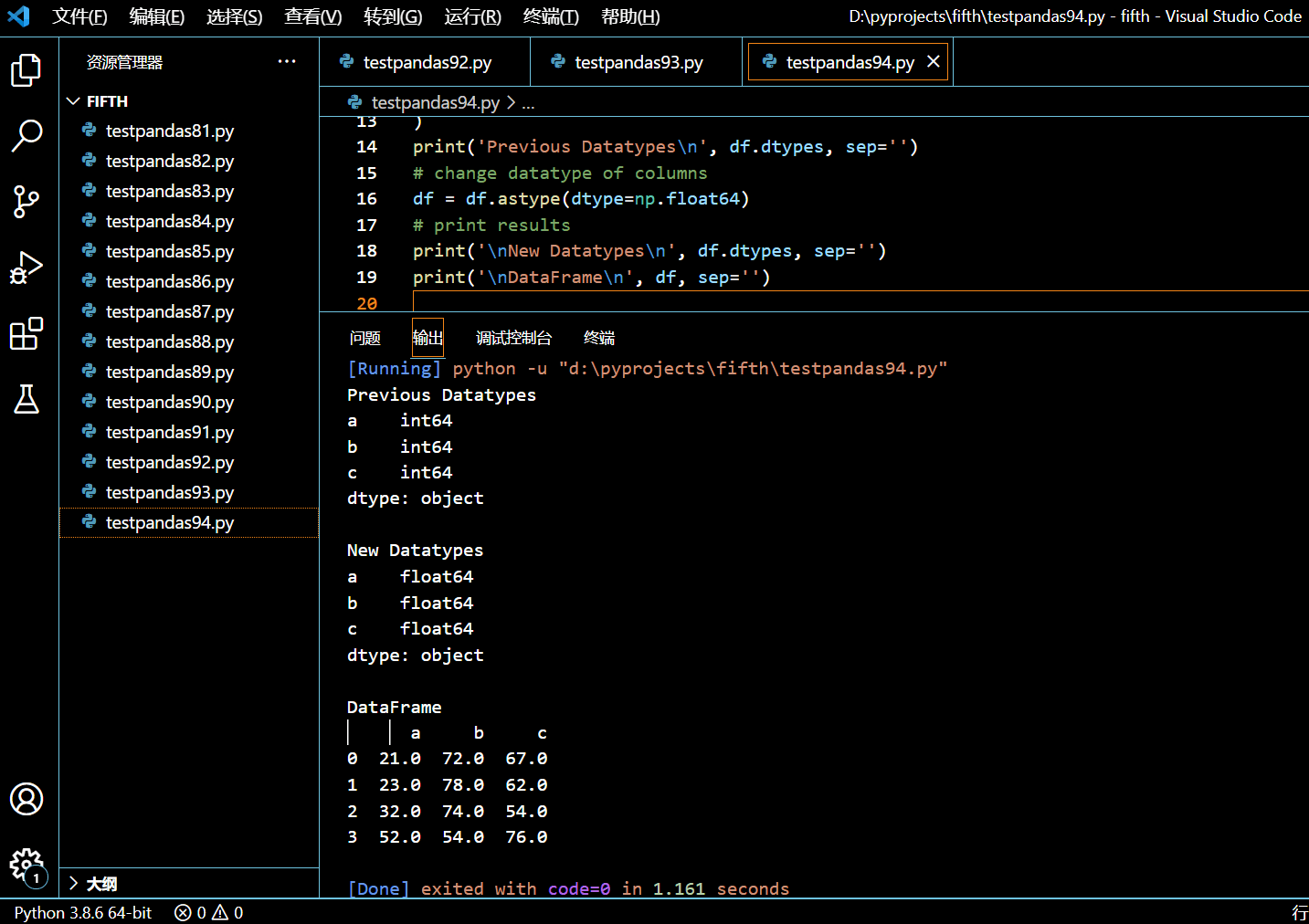
5.12.1.3. 修改所有列的数据类型
如果你想修改 DataFrame 所有列的数据类型,你只需要把目标数据类型传给 astype() 方法即可,不需要字典对象。
在接下来的示例中,我们将把所有列的数据类型都改为 float64。
import pandas as pd
import numpy as np
# initialize a dataframe
df = pd.DataFrame(
data=[
[21, 72, 67],
[23, 78, 62],
[32, 74, 54],
[52, 54, 76]
],
columns=['a', 'b', 'c']
)
print('Previous Datatypes\n', df.dtypes, sep='')
# change datatype of columns
df = df.astype(dtype=np.float64)
# print results
print('\nNew Datatypes\n', df.dtypes, sep='')
print('\nDataFrame\n', df, sep='')
执行和输出:
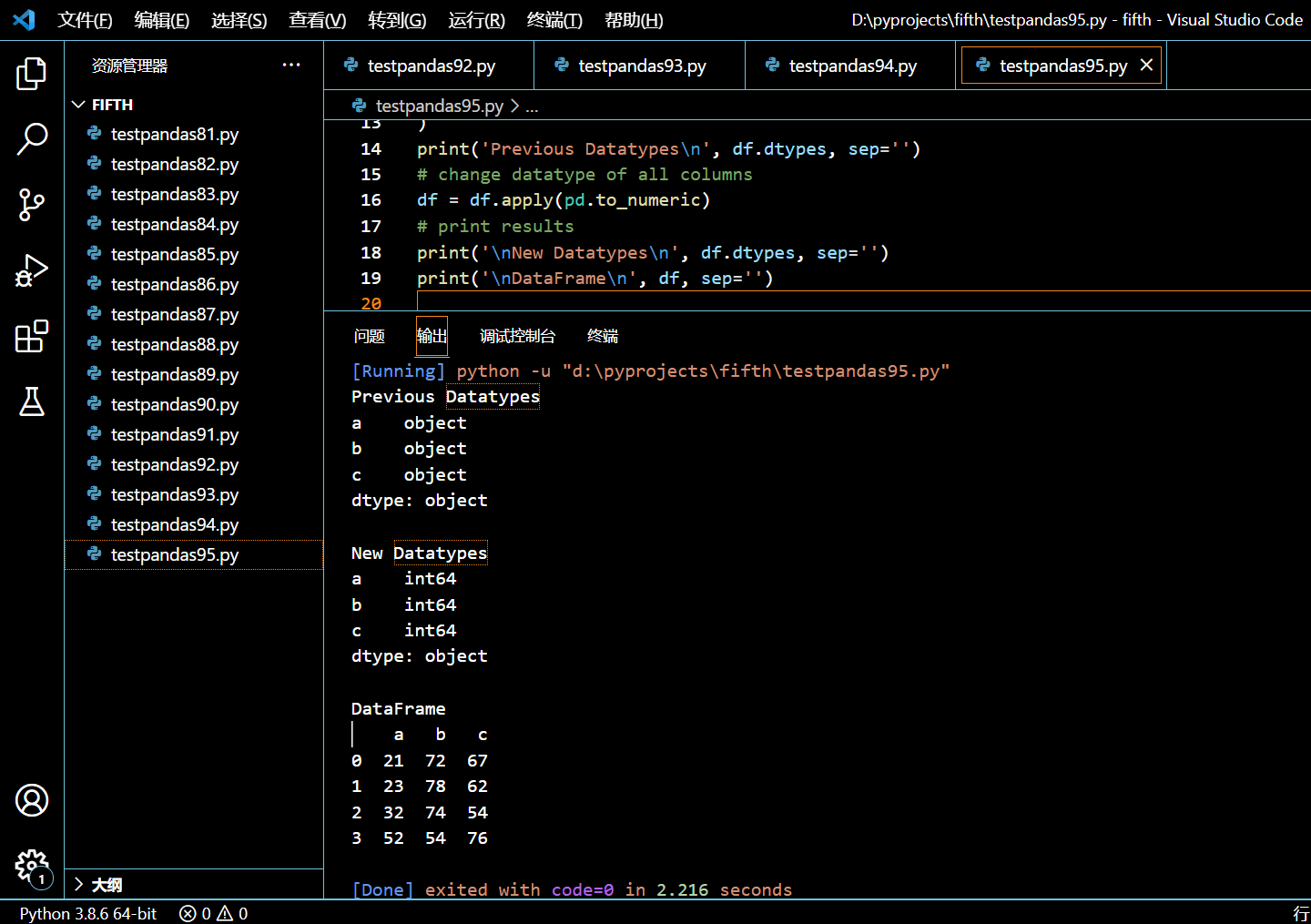
5.12.2. pd.to_numeric
假设你从 excel、csv 或其他数据源中导入了一个 DataFrame,它里边的所有元素皆为字符串值。现在想要把所有列的数据类型转换为合适的数字数据类型。
import pandas as pd
import numpy as np
# initialize a dataframe
df = pd.DataFrame(
data=[
['21', '72', '67'],
['23', '78', '62'],
['32', '74', '54'],
['52', '54', '76']
],
columns=['a', 'b', 'c']
)
print('Previous Datatypes\n', df.dtypes, sep='')
# change datatype of all columns
df = df.apply(pd.to_numeric)
# print results
print('\nNew Datatypes\n', df.dtypes, sep='')
print('\nDataFrame\n', df, sep='')
执行和输出:
5.12.3. 小结
通过本节示例我们了解了如何修改 DataFrame 中列的数据类型。
5.13. 如何修改 Pandas DataFrame 里列的次序?
5.13.1. 使用 DataFrame.reindex()
你可以通过调用 DataFrame.reindex() 来修改其列的顺序,将重新排列的列名作为参数传递给它。
new_dataframe = dataframe.reindex(columns=['a', 'c', 'b'])
reindex() 函数将返回一个给定列顺序的新的 DataFrame。
在接下来的示例中,我们将新建一个列顺序为 a, b, c 的 DataFrame,然后将列的顺序改变为 a, c, b。
import pandas as pd
# initialize a dataframe
df = pd.DataFrame(
data=[
[21, 72, 67],
[23, 78, 62],
[32, 74, 54],
[52, 54, 76]
],
columns=['a', 'b', 'c']
)
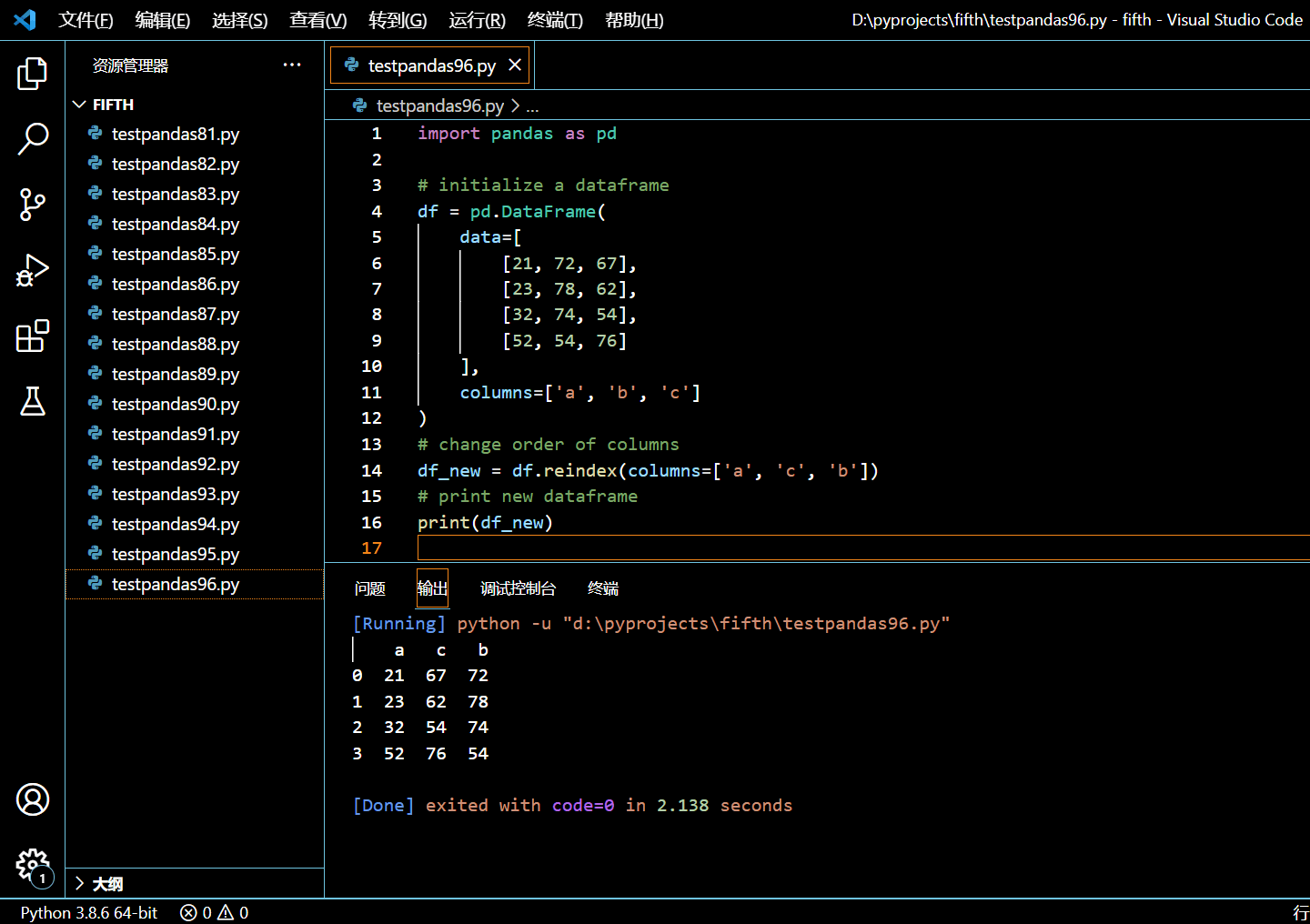
# change order of columns
df_new = df.reindex(columns=['a', 'c', 'b'])
# print new dataframe
print(df_new)
执行和输出:
5.13.2. 使用 DataFrame 索引
DataFrame 索引(中括号)可被用于修改指定 DataFrame 的列顺序。
以下为 DataFrame 索引(中括号)修改列顺序的语法:
new_dataframe = dataframe[['a', 'c', 'b']]
在接下来的示例中,我们就用这种办法来将列顺序为 a, b, c 的 DataFrame 改为顺序为 a, c, b。
import pandas as pd
# initialize a dataframe
df = pd.DataFrame(
data=[
[21, 72, 67],
[23, 78, 62],
[32, 74, 54],
[52, 54, 76]
],
columns=['a', 'b', 'c']
)
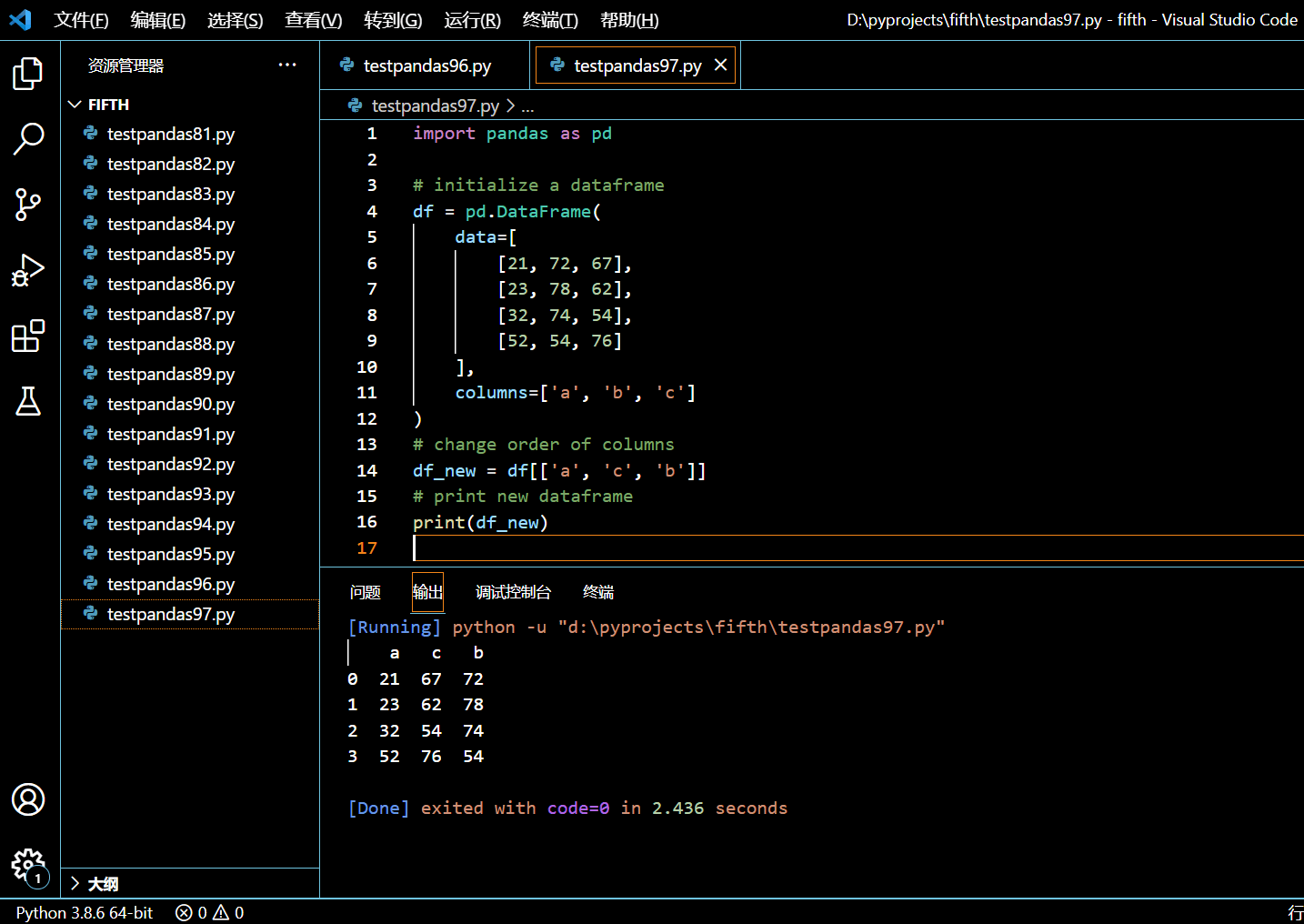
# change order of columns
df_new = df[['a', 'c', 'b']]
# print new dataframe
print(df_new)
执行和输出:
5.13.3. 使用 DataFrame 构造子
你也可以利用 DataFrame 的构造子来对列进行重新排序。把当前 DataFrame 当做裸数据,以这些裸数据和排好序的列重新创建一个新的 DataFrame。
以下是为用该方法修改列顺序的语法:
new_dataframe = pd.dataframe(raw_data, index=['a', 'c', 'b'])
在接下来的示例中,我们将新建一个列顺序为 a, b, c 的 DataFrame,然后改变列的顺序为 a, c, b。
import pandas as pd
# initialize a dataframe
df = pd.DataFrame(
data=[
[21, 72, 67],
[23, 78, 62],
[32, 74, 54],
[52, 54, 76]
],
columns=['a', 'b', 'c']
)
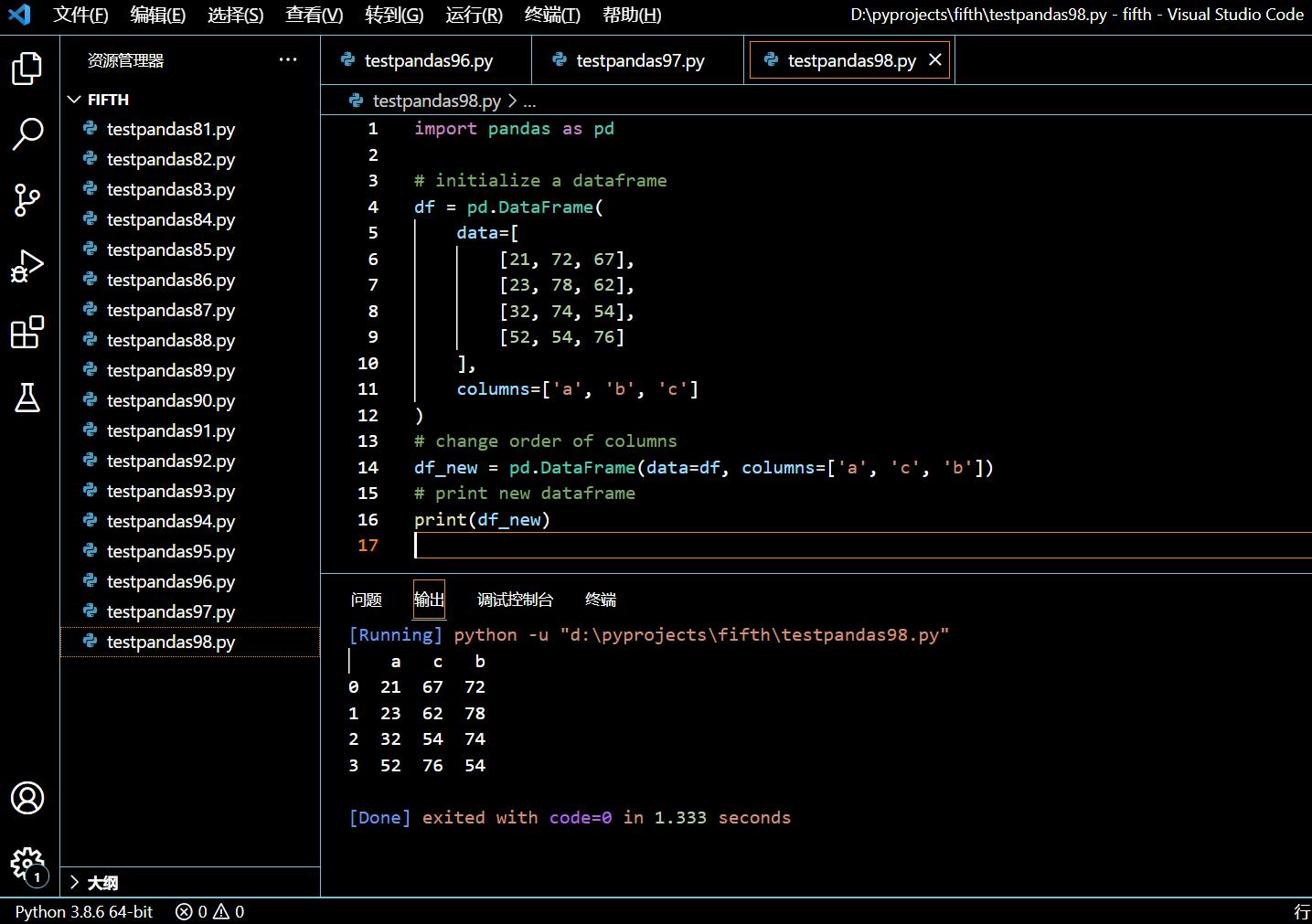
# change order of columns
df_new = pd.DataFrame(data=df, columns=['a', 'c', 'b'])
# print new dataframe
print(df_new)
执行和输出:
5.13.4. 小结
本节我们了解到了如何修改 DataFrame 中列的顺序。
5.14. 替换多个值
要替换 DataFrame 中的多个值,可以使用 DataFrame.replace() 方法,以 旧 - 新 值组成的字典传给它即可。
5.14.1. 替换一列中的多个值
替换 DataFrame 中某一列的多个值的语法如下:
DataFrame.replace({'column_name' : { old_value_1 : new_value_1, old_value_2 : new_value_2}})
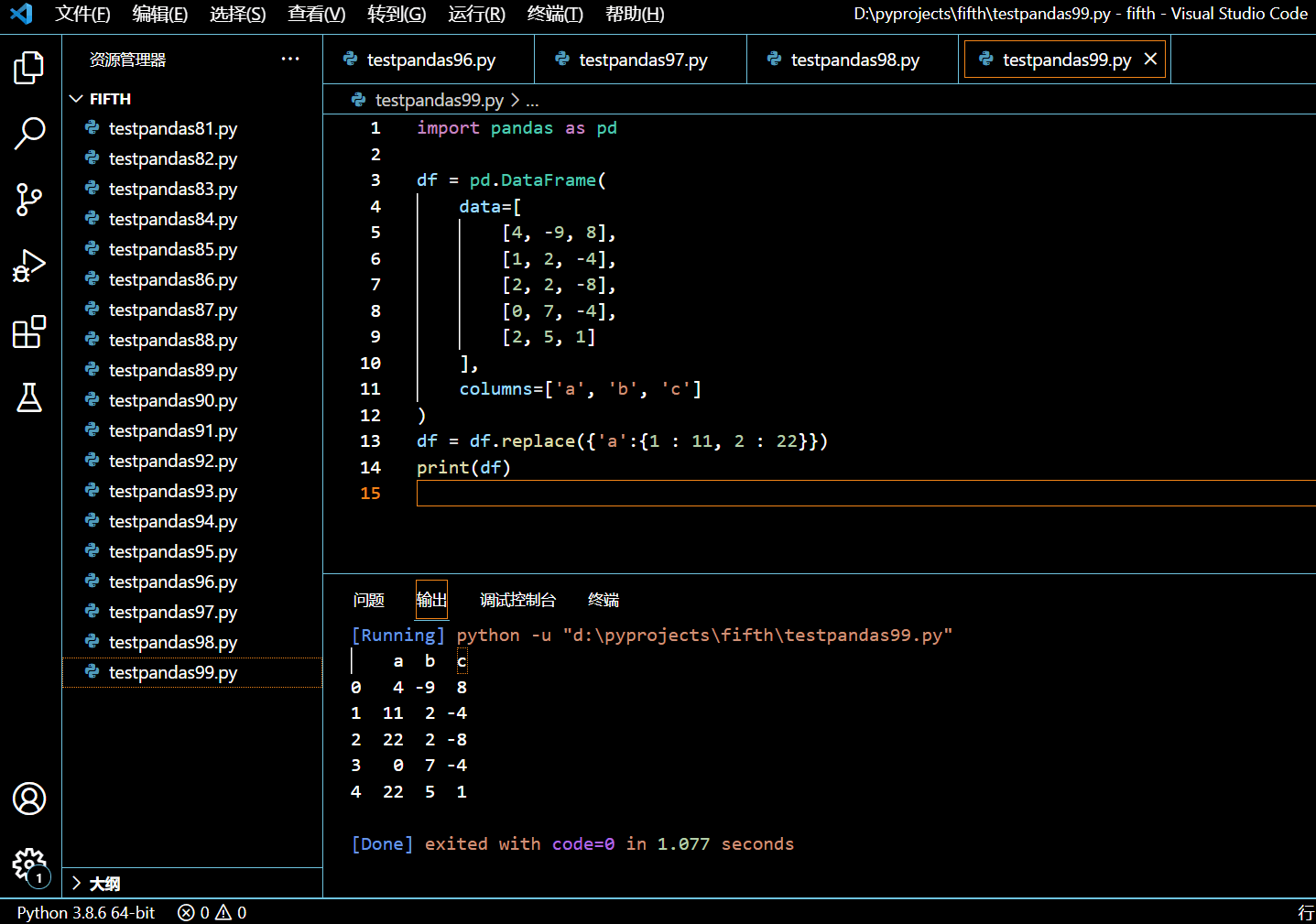
在接下来的示例中,我们将使用 replace() 方法,将列 a 中所有的 1 值替换为 11,所有的 2 值替换为 22。
import pandas as pd
df = pd.DataFrame(
data=[
[4, -9, 8],
[1, 2, -4],
[2, 2, -8],
[0, 7, -4],
[2, 5, 1]
],
columns=['a', 'b', 'c']
)
df = df.replace({'a':{1 : 11, 2 : 22}})
print(df)
执行和输出:
5.14.2. 替换多列中的多个值
替换多列中的多个值的语法如下:
DataFrame.replace({'column_name_1' : { old_value_1 : new_value_1, old_value_2 : new_value_2},
'column_name_2' : { old_value_1 : new_value_1, old_value_2 : new_value_2}})
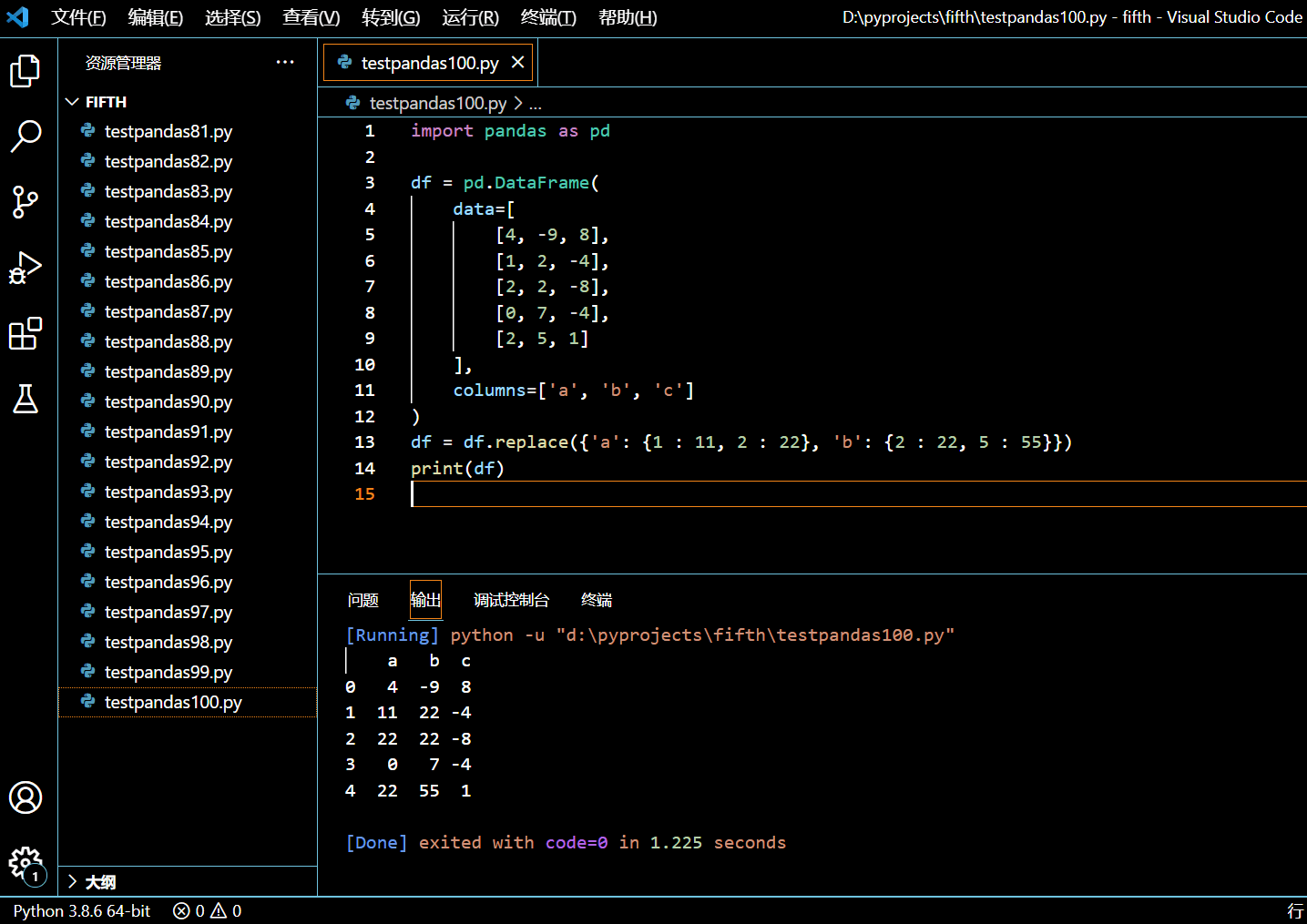
在接下来的示例中,我们将使用 replace() 方法,将列 a 中所有的 1 值替换为 11、所有的2 值替换为 22;将列 b 中所有的 2 值替换为 22、所有的 5 值替换为 55。
import pandas as pd
df = pd.DataFrame(
data=[
[4, -9, 8],
[1, 2, -4],
[2, 2, -8],
[0, 7, -4],
[2, 5, 1]
],
columns=['a', 'b', 'c']
)
df = df.replace({'a': {1 : 11, 2 : 22}, 'b': {2 : 22, 5 : 55}})
print(df)
外层字典为列维度,内层字典为列内元素维度。执行和输出:
5.14.3. 小结
本节我们了解了如何替换单列或多列中的多个值。
5.15. 根据条件替换列里边的值
要根据条件来替换 Pandas DataFrame 列中的值,你可以使用这三种方法里的任一:
- 使用 DataFrame.loc 属性
- numpy.where()
- DataFrame.where()
5.15.1. DataFrame.loc - 根据条件替换列内的值
使用 DataFrame.loc 根据条件替换某一列内的值的语法为:
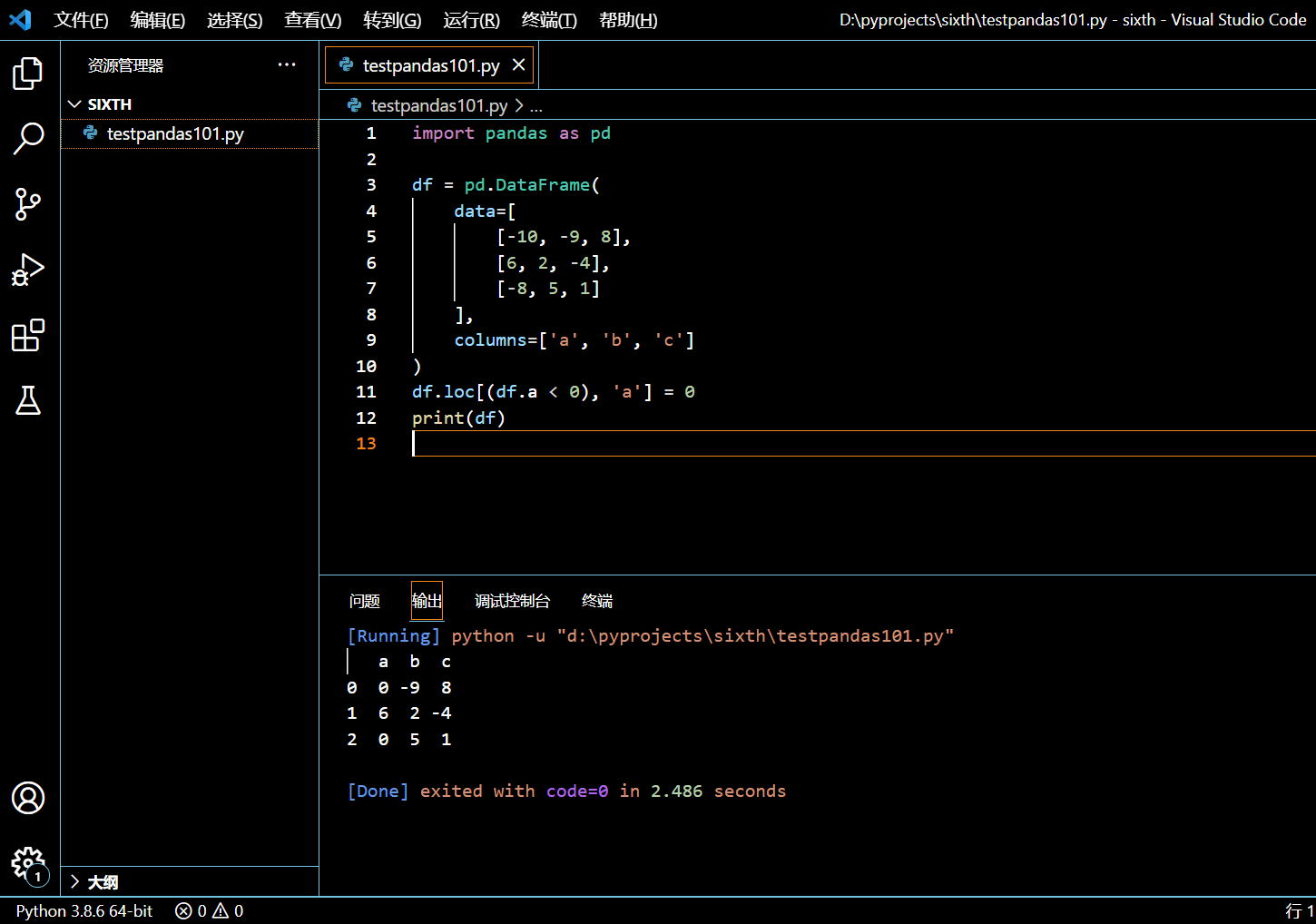
DataFrame.loc[condition, column_name] = new_value
在接下来的示例中,我们将把列 a 中小于零的值替换为零。
import pandas as pd
df = pd.DataFrame(
data=[
[-10, -9, 8],
[6, 2, -4],
[-8, 5, 1]
],
columns=['a', 'b', 'c']
)
df.loc[(df.a < 0), 'a'] = 0
print(df)
执行和输出:
你也可以基于单一条件传入多个列。将这些列作为元组传给 loc 方法。
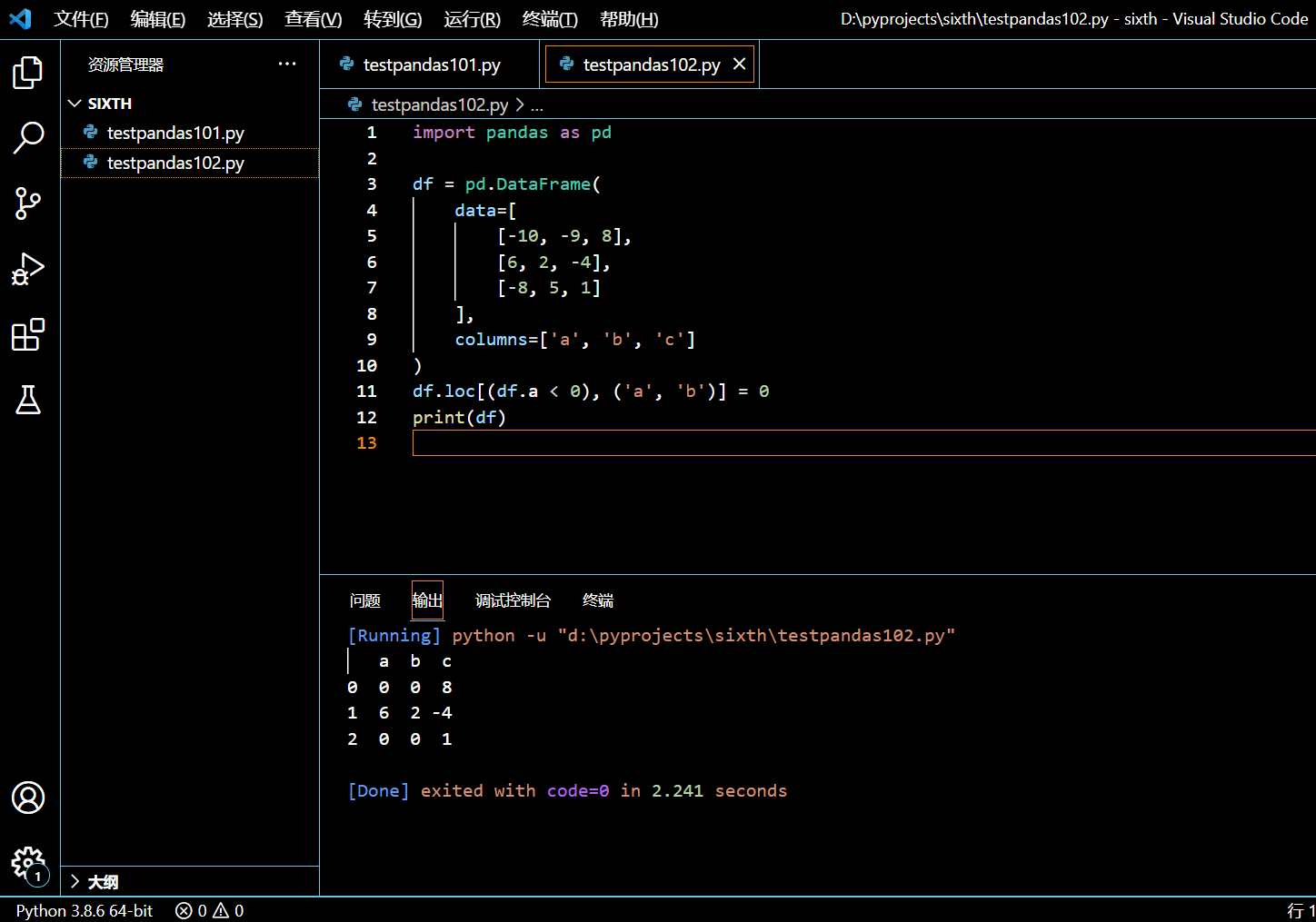
DataFrame.loc[condition, (column_1, column_2)] = new_value
在接下来的示例中,我们将把 a 和 b 列中小于零的值都替换为零。
import pandas as pd
df = pd.DataFrame(
data=[
[-10, -9, 8],
[6, 2, -4],
[-8, 5, 1]
],
columns=['a', 'b', 'c']
)
df.loc[(df.a < 0), ('a', 'b')] = 0
print(df)
执行和输出:
5.15.2. numpy.where - 根据条件替换列里边的值
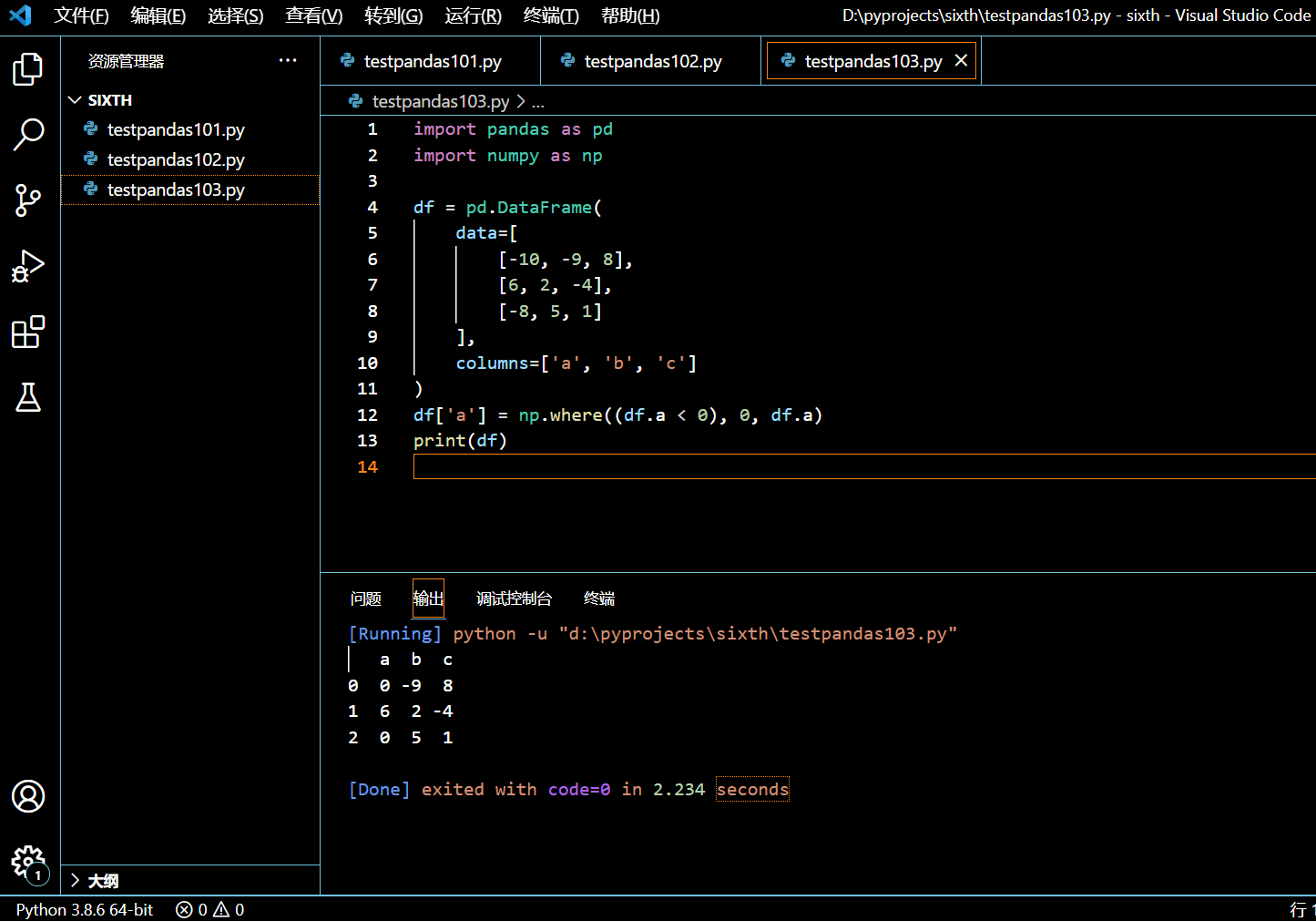
也可以使用 numpy.where 来根据给定条件替换某一列里的值,其语法如下:
DataFrame['column_name'] = numpy.where(condition, new_value, DataFrame.column_name)
在接下来的示例中,我们将使用 numpy.where() 方法来替换掉列 a 中小于零的值。
import pandas as pd
import numpy as np
df = pd.DataFrame(
data=[
[-10, -9, 8],
[6, 2, -4],
[-8, 5, 1]
],
columns=['a', 'b', 'c']
)
df['a'] = np.where((df.a < 0), 0, df.a)
print(df)
执行和输出:
5.15.3. DataFrame.where - 根据条件替换列里的值
还可以使用 DataFrame.where 根据条件替换列里的值,其语法如下:
DataFrame['column_name'].where(~(condition), other=new_value, inplace=True)
其中,
- column_name 是为替换发生的列
- condition 需要被取代的布尔值表达式
- new_value 需要替换成的目标值
在接下来的示例中,我们将使用 DataFrame.where() 方法将 a 列中小于零的值都替换为零。
import pandas as pd
df = pd.DataFrame(
data=[
[-10, -9, 8],
[6, 2, -4],
[-8, 5, 1]
],
columns=['a', 'b', 'c']
)
df['a'].where(~(df.a < 0), other=0, inplace=True)
print(df)
执行和输出:
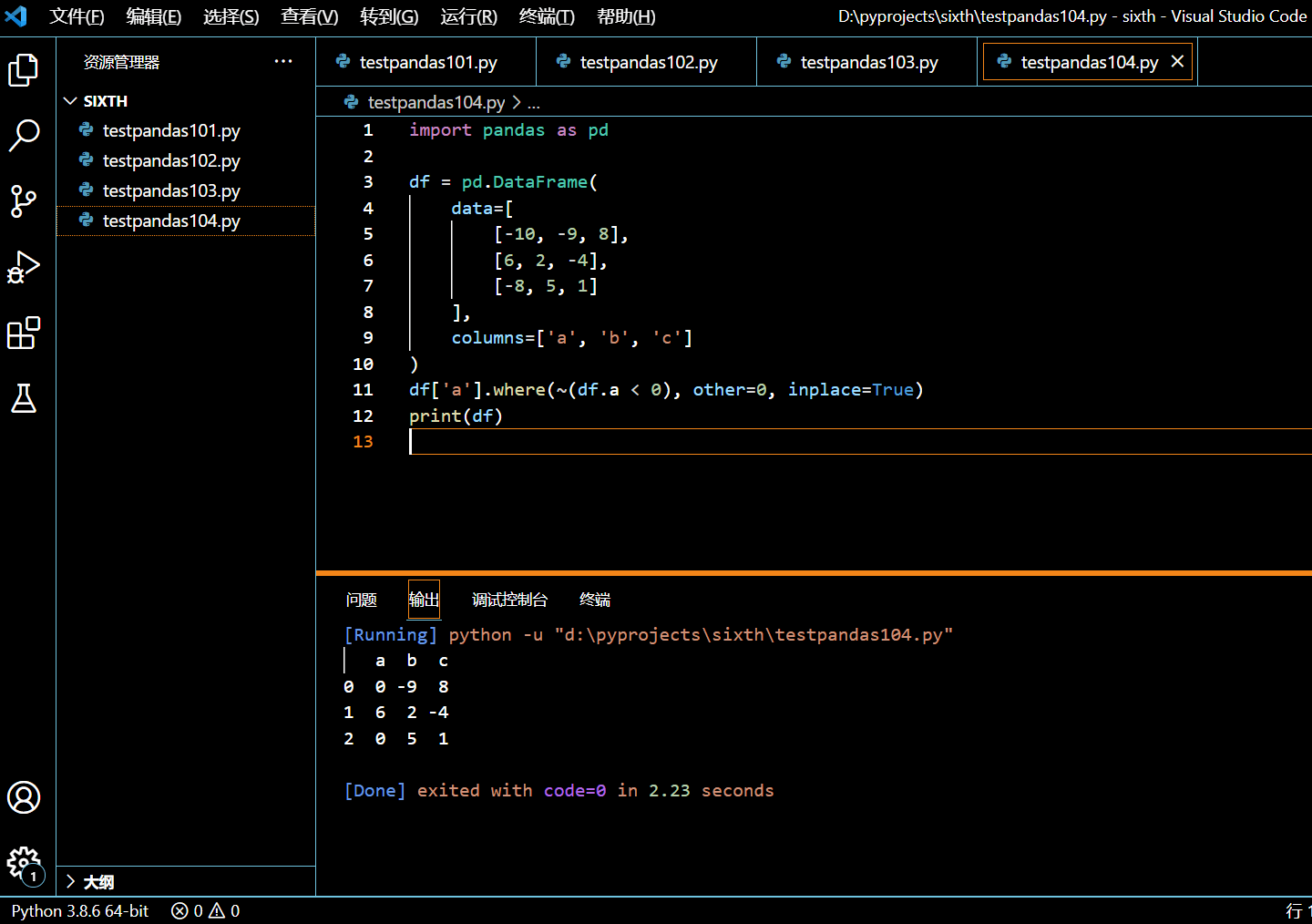
5.15.4. 小结
通过本节示例,我们了解了如何根据条件将 DataFrame 列中的值替换为一个新值。
6. Pandas DataFrame 行操作
6.1. Pandas iterrows() - 行遍历
要遍历一个 Pandas DataFrame 里的行,使用 DataFrame.iterrows() 函数,它将返回一个每行索引和行数据的迭代器。
6.1.1. iterrows() 的语法
iterrows() 的语法如下:
DataFrame.iterrows(self)
它的返回,
- index - DataFrame 中该列的索引。这个可以是一个列标签的单个索引,也可以是一个元组列标签的多个索引。
- data - Pandas Series 形式的行数据。
- it - 迭代 DataFrame 行的生成器。
6.1.2. Pandas iterrows() - 遍历行
本示例中,我们将初始化一个拥有四行数据的 DataFrame,然后使用 Python for 循环(参考博客《简单 Python 快乐之旅之:Python 基础语法之循环关键字的使用例子》)和 iterrows() 函数对DataFrame 的行进行遍历。
import pandas as pd
# create dataframe
df_marks = pd.DataFrame(
data={
'name': ['apple', 'banana', 'orange', 'mango'],
'calories': [68, 74, 77, 78]
}
)
# iterate through each row of dataframe
for index, row in df_marks.iterrows():
print(index, ': ', row['name'], 'has', row['calories'], 'calories.')
通过每个迭代,我们能够访问到行的索引和行的内容。执行和输出:
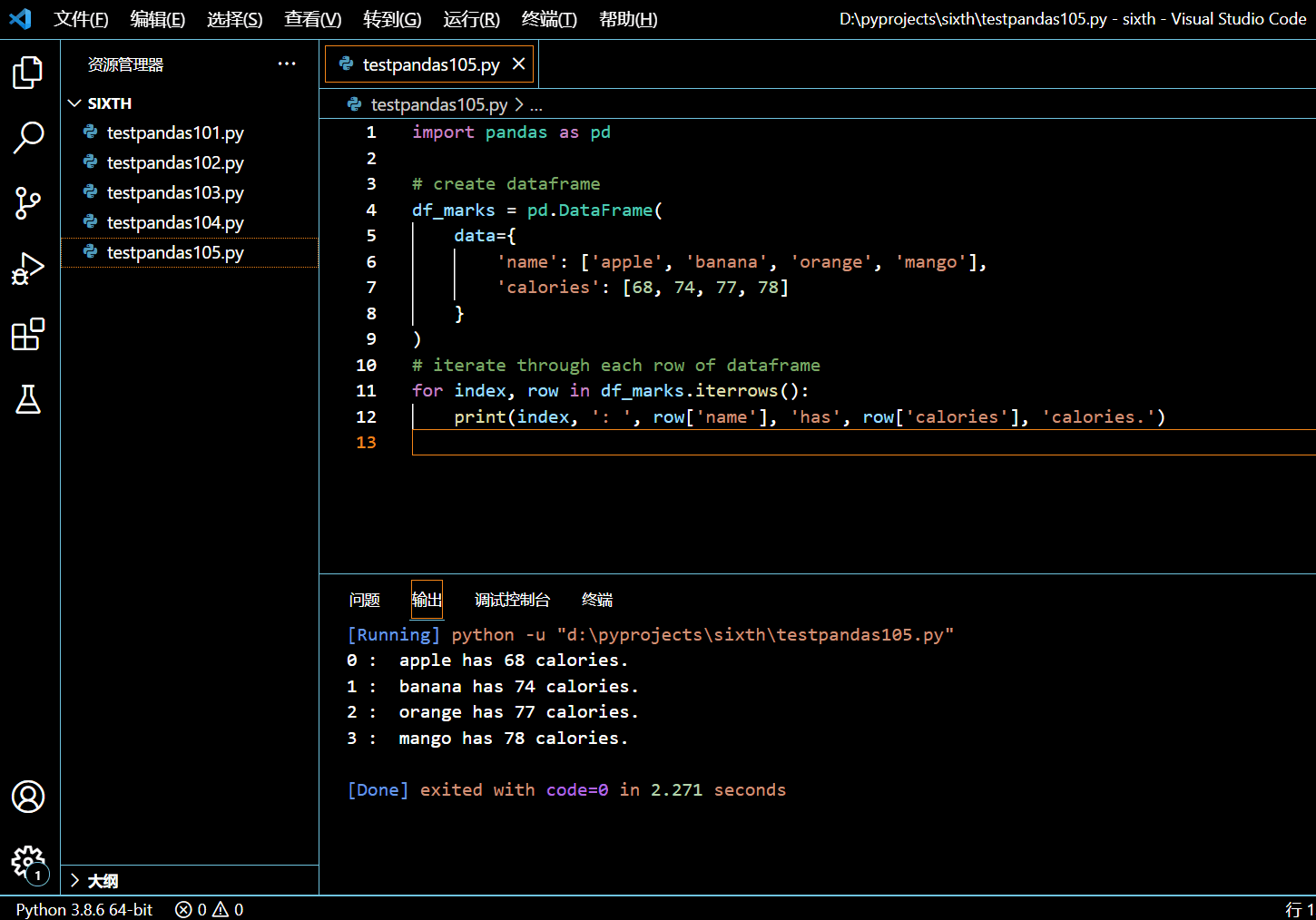
请注意以上每种水果的卡路里数据纯属虚构。本示例只是演示 iterrows() 的用法。
6.1.3. iterrows() 返回索引和行内容的数据类型
通过前面的示例,我们看到可以通过 iterrows() 来访问每行的索引和内容。
在接下来的示例中,我们来看一下 iterrows() 迭代时返回的每行数据的数据类型。
import pandas as pd
# create dataframe
df_marks = pd.DataFrame(
data={
'name': ['apple', 'banana', 'orange', 'mango'],
'calories': [68, 74, 77, 78]
}
)
# iterate through each row of dataframe
for index, row in df_marks.iterrows():
print(type(index), type(row))
执行和输出:
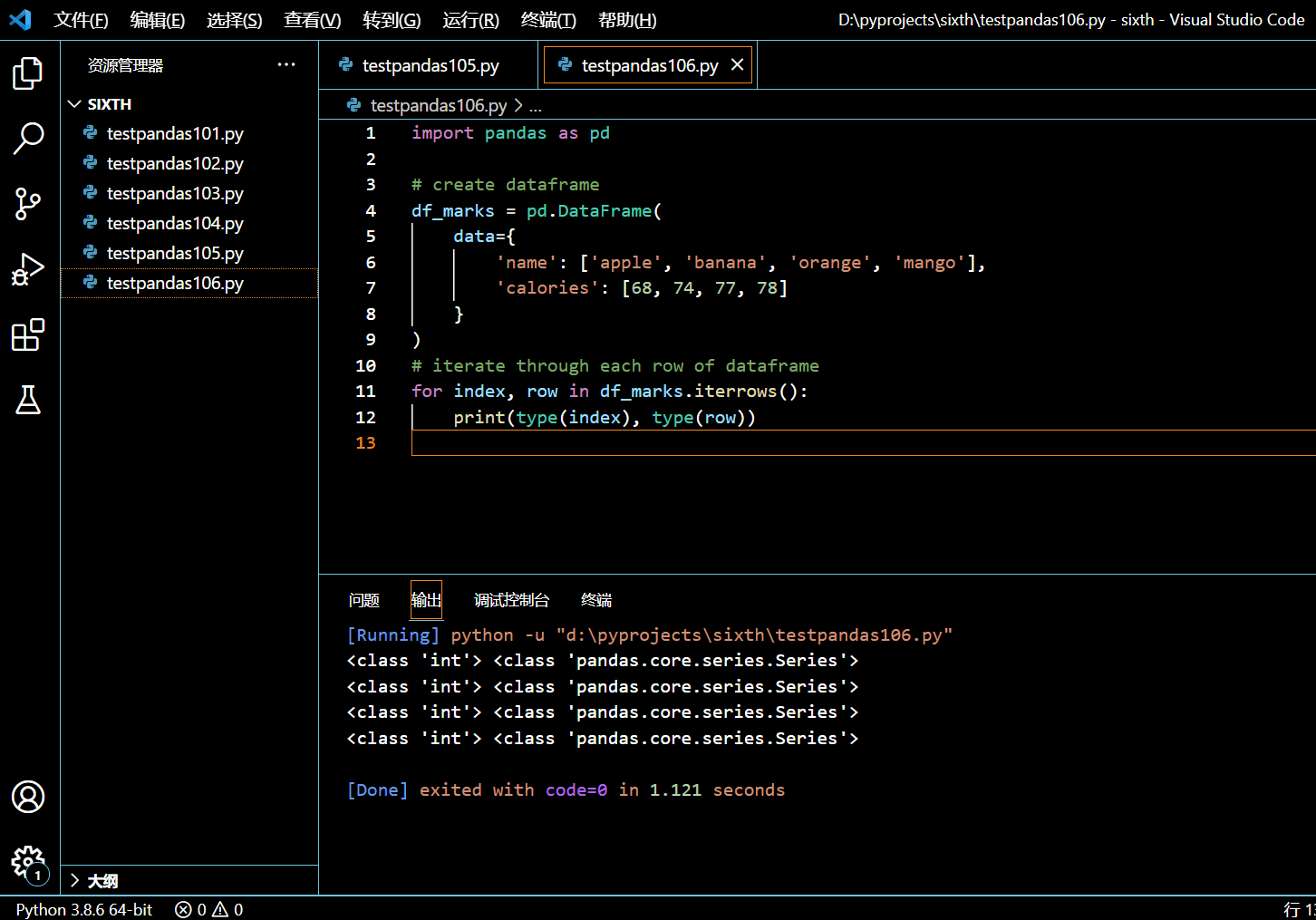
我们并没有给 DataFrame 显式提供索引,所以 Python 默认给它生成整型索引,由零开始,递增加一。所以上面示例中的 iterrows() 返回的索引是为整型。
6.1.4. 小结
通过本节我们了解了如何使用 DataFrame.iterrows() 来遍历 Pandas DataFrame 里的行。
6.2. 如何给 DataFrame 添加或插入新行?
要追加或新加一行到 DataFrame,将新行创建为 Series,然后使用 DataFrame.append() 方法。

6.2.1. append() 的语法
DataFrame.appen() 函数的语法如下:
mydataframe = mydataframe.append(new_row, ignore_index=True)
其中,new_row 行将被添加到 mydataframe。
append() 是 immutable 的。它并不会改变当前 DataFrame,但它会返回一个追加新行后的新的 DataFrame。
6.2.2. 添加新行到 DataFrame
本示例中,我们将新建一个 DataFrame,然后追加一个新行到这个 DataFrame。
当你追加的数据是一个 Python 字典时,注意一定还有传给 append() 函数 ignore_index=True 参数。
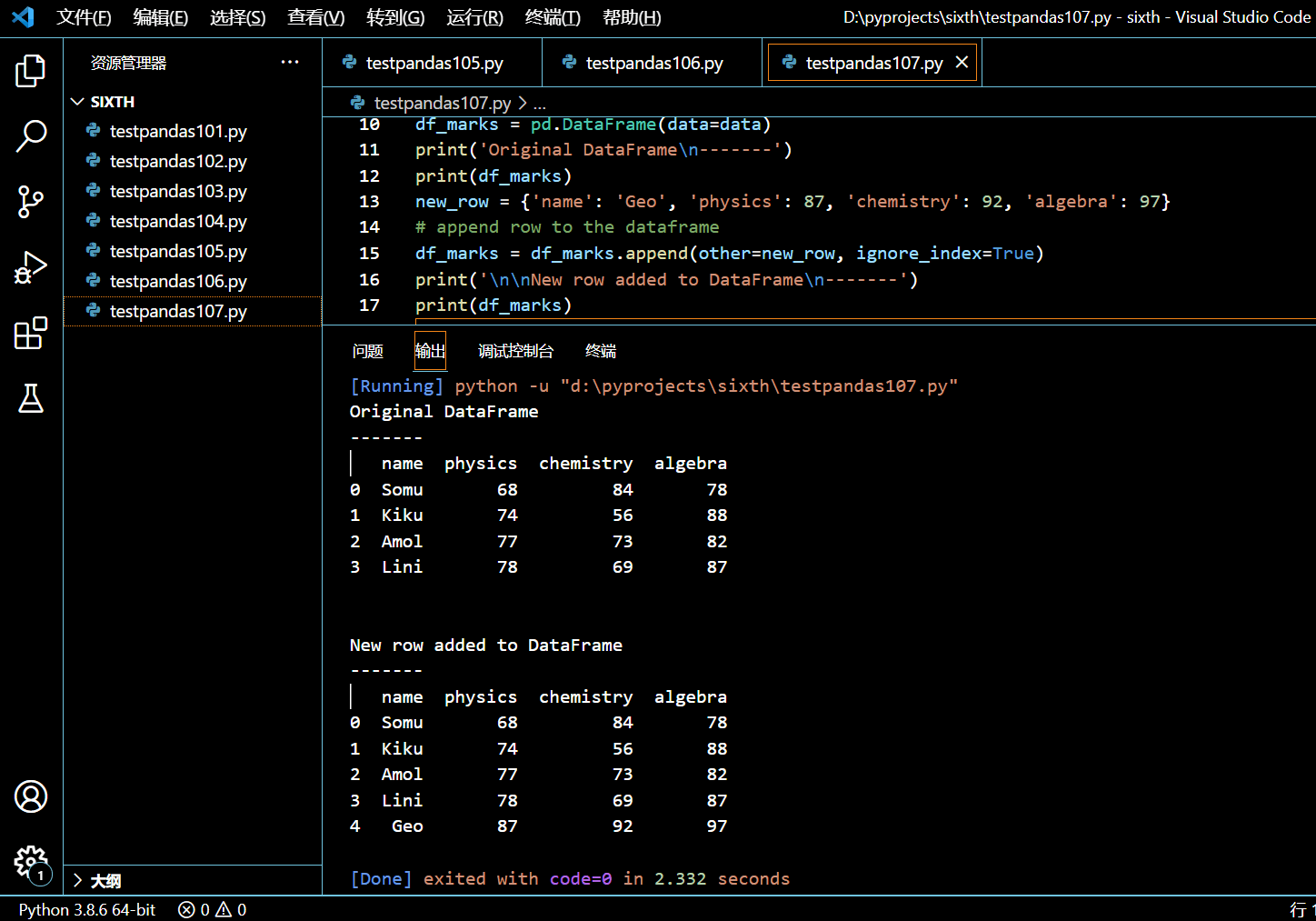
import pandas as pd
data = {
'name': ['Somu', 'Kiku', 'Amol', 'Lini'],
'physics': [68, 74, 77, 78],
'chemistry': [84, 56, 73, 69],
'algebra': [78, 88, 82, 87]
}
# create dataframe
df_marks = pd.DataFrame(data=data)
print('Original DataFrame\n-------')
print(df_marks)
new_row = {'name': 'Geo', 'physics': 87, 'chemistry': 92, 'algebra': 97}
# append row to the dataframe
df_marks = df_marks.append(other=new_row, ignore_index=True)
print('\n\nNew row added to DataFrame\n-------')
print(df_marks)
执行和输出:
6.2.3. 添加新行到 Pandas DataFrame(ignoreIndex=False)
那么为何必须传 ignoreIndex=True 给 append() 函数呢,因为不这样的话你会碰到 TypeError。
在接下来的示例中,我们就来尝试一下传递 ignoreIndex=False。
import pandas as pd
data = {
'name': ['Amol', 'Lini'],
'physics': [77, 78],
'chemistry': [73, 85]
}
# create dataframe
df_marks = pd.DataFrame(data=data)
print('Original DataFrame\n-------')
print(df_marks)
new_row = {'name': 'Geo', 'physics': 87, 'chemistry': 92}
# append row to the dataframe
df_marks = df_marks.append(other=new_row, ignore_index=False)
print('\n\nNew row added to DataFrame\n-------')
print(df_marks)
执行和输出:
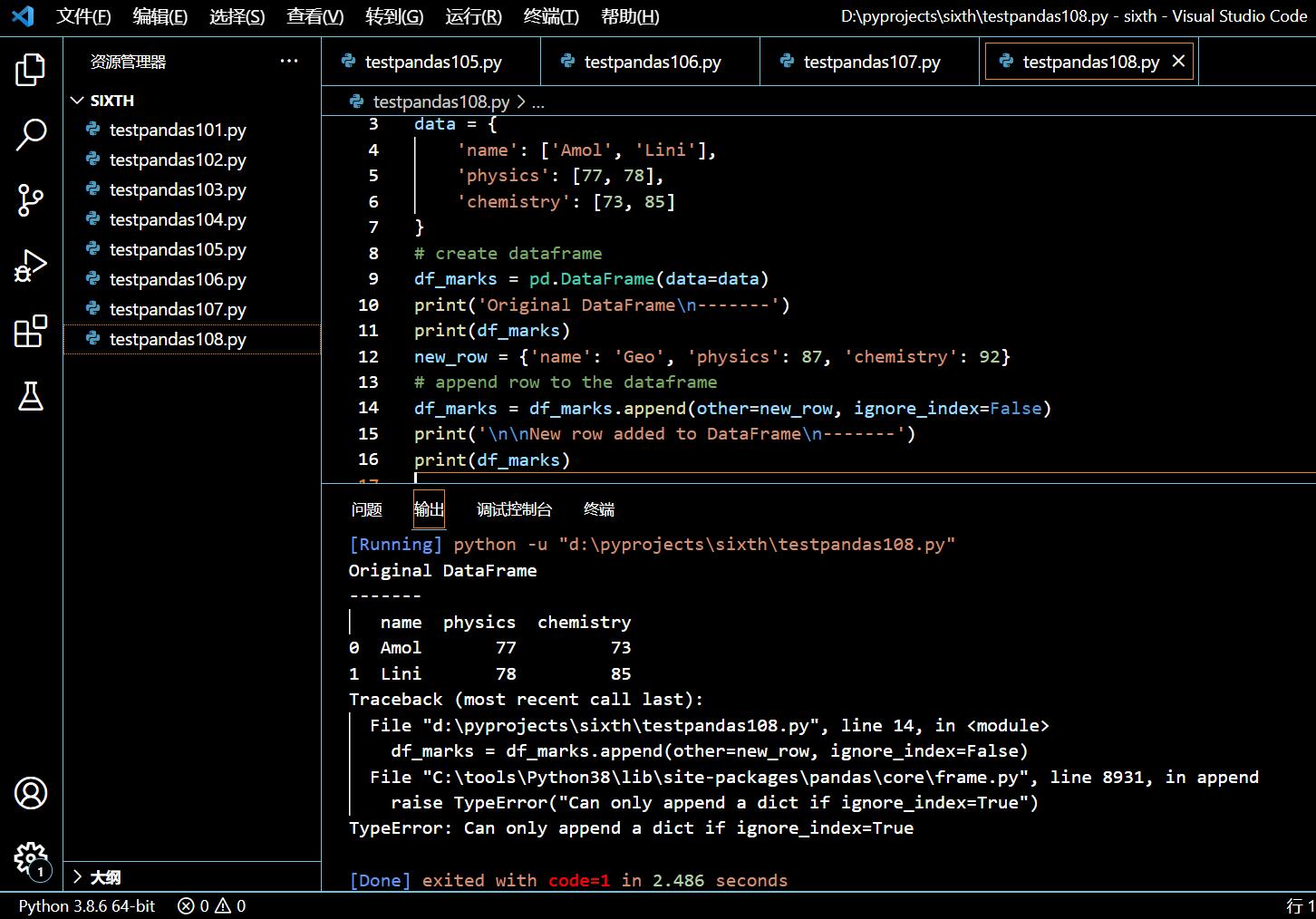
可见如果追加的是一个字典,ignore_index=True 是必须的。
那么 ignore_index=False 适用于哪些场合?
import pandas as pd
data = {
'name': ['Amol', 'Lini'],
'physics': [77, 78],
'chemistry': [73, 85]
}
# create dataframe
df_marks = pd.DataFrame(data)
print('Original DataFrame\n-------')
print(df_marks)
new_row = pd.Series(data={'name': 'Geo', 'physics': 87, 'chemistry': 92}, name='x')
# append row to the dataframe
df_marks = df_marks.append(other=new_row, ignore_index=False)
print('\n\nNew row added to DataFrame\n-------')
print(df_marks)
执行和输出:
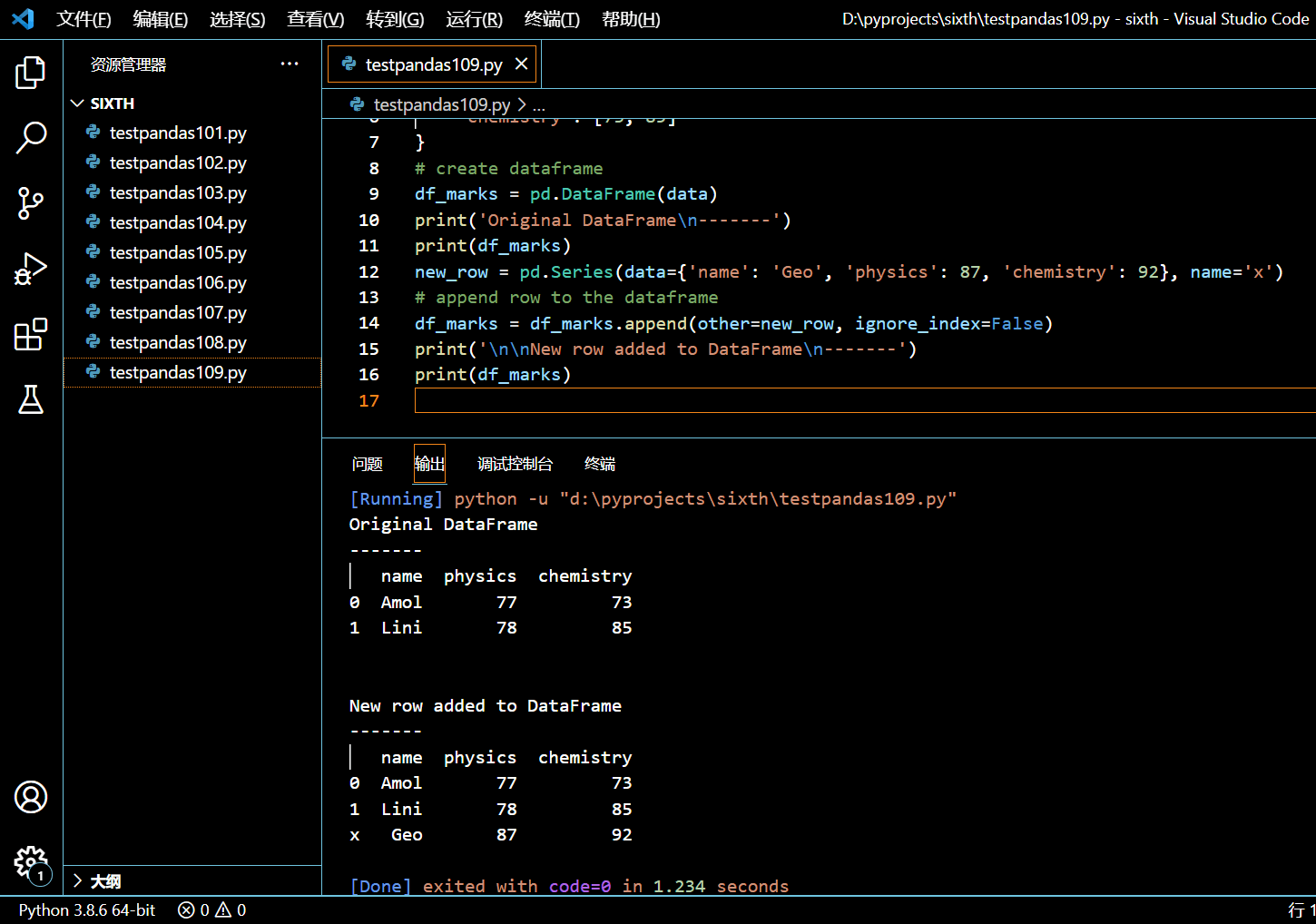
可见我们将 Series 作为 data 传入,ignore_index=False 就不再抛出 TypeError 了。
6.2.4. 小结
本节我们了解了如何使用 append() 函数来添加一行到 Pandas DataFrame。
6.3. 如何拿到 Pandas DataFrame 的前 N 行数据?
要获取 DataFrame 的前 N 行,使用 pandas.DataFrame.head() 函数。你可以传给它一个可选的整型数据,这个整型代表了前多少行。如果你没有传任何数据,它将返回前 5 行。也就是说,N 默认为 5。
6.3.1. DataFrame.head(N)
本示例中,我们将获取 DataFrame 的前 3 行。
import pandas as pd
# initialize a dataframe
df = pd.DataFrame(
data=[
[21, 72, 67],
[23, 78, 62],
[32, 74, 56],
[73, 88, 67],
[32, 74, 56],
[43, 78, 69],
[32, 74, 54],
[52, 54, 76]
],
columns=['a', 'b', 'c']
)
# get first 3 rows
df1 = df.head(n=3)
print(df1)
执行和输出:
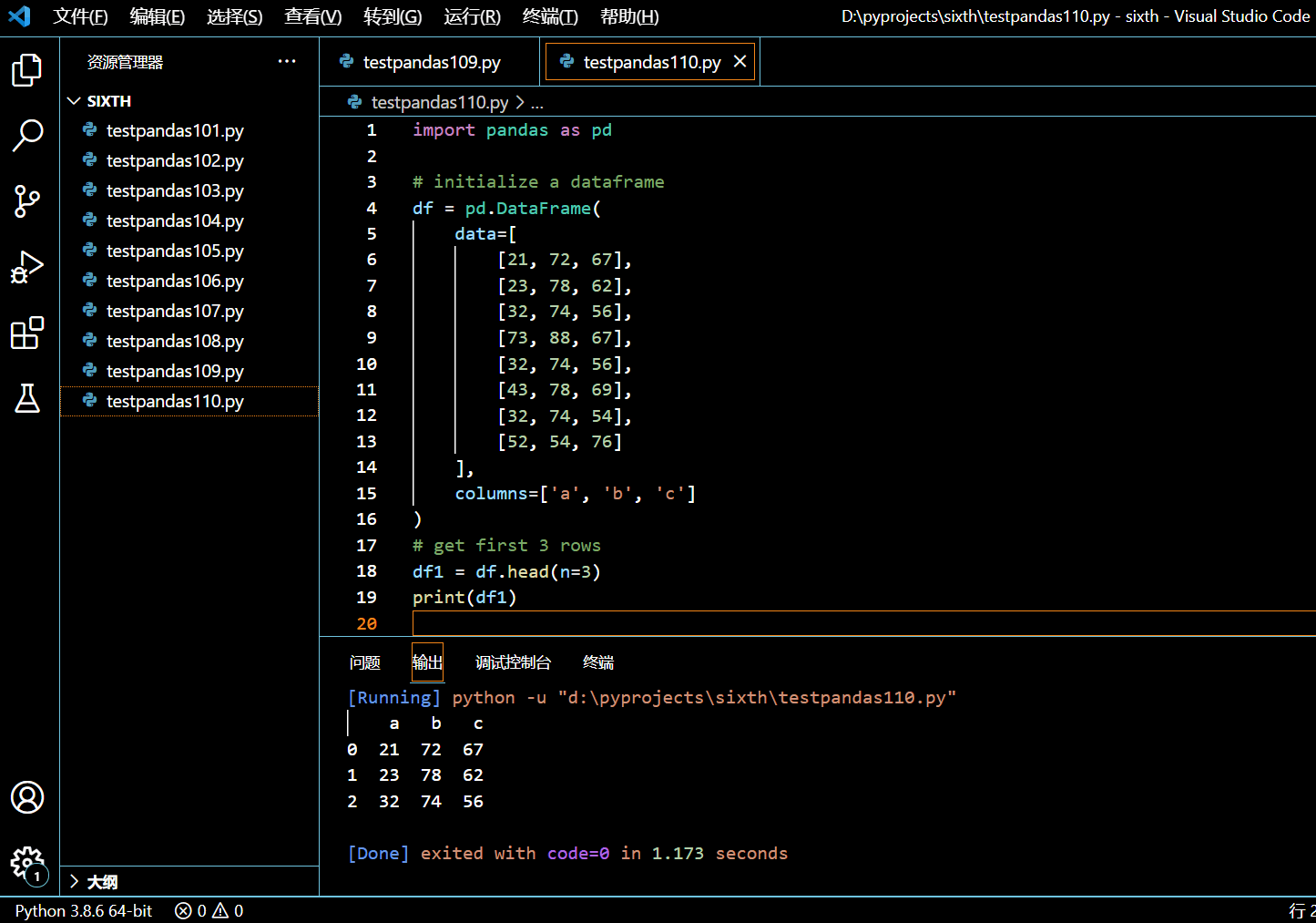
6.3.2. DataFrame.head()
接下来的示例中,我们不传递任何数字给函数 head()。默认情况下,head() 函数将返回前 5 行。
import pandas as pd
# initialize a dataframe
df = pd.DataFrame(
data=[
[21, 72, 67],
[23, 78, 62],
[32, 74, 56],
[73, 88, 67],
[32, 74, 56],
[43, 78, 69],
[32, 74, 54],
[52, 54, 76]
],
columns=['a', 'b', 'c']
)
# get first 3 rows
df1 = df.head()
print(df1)
执行和输出:
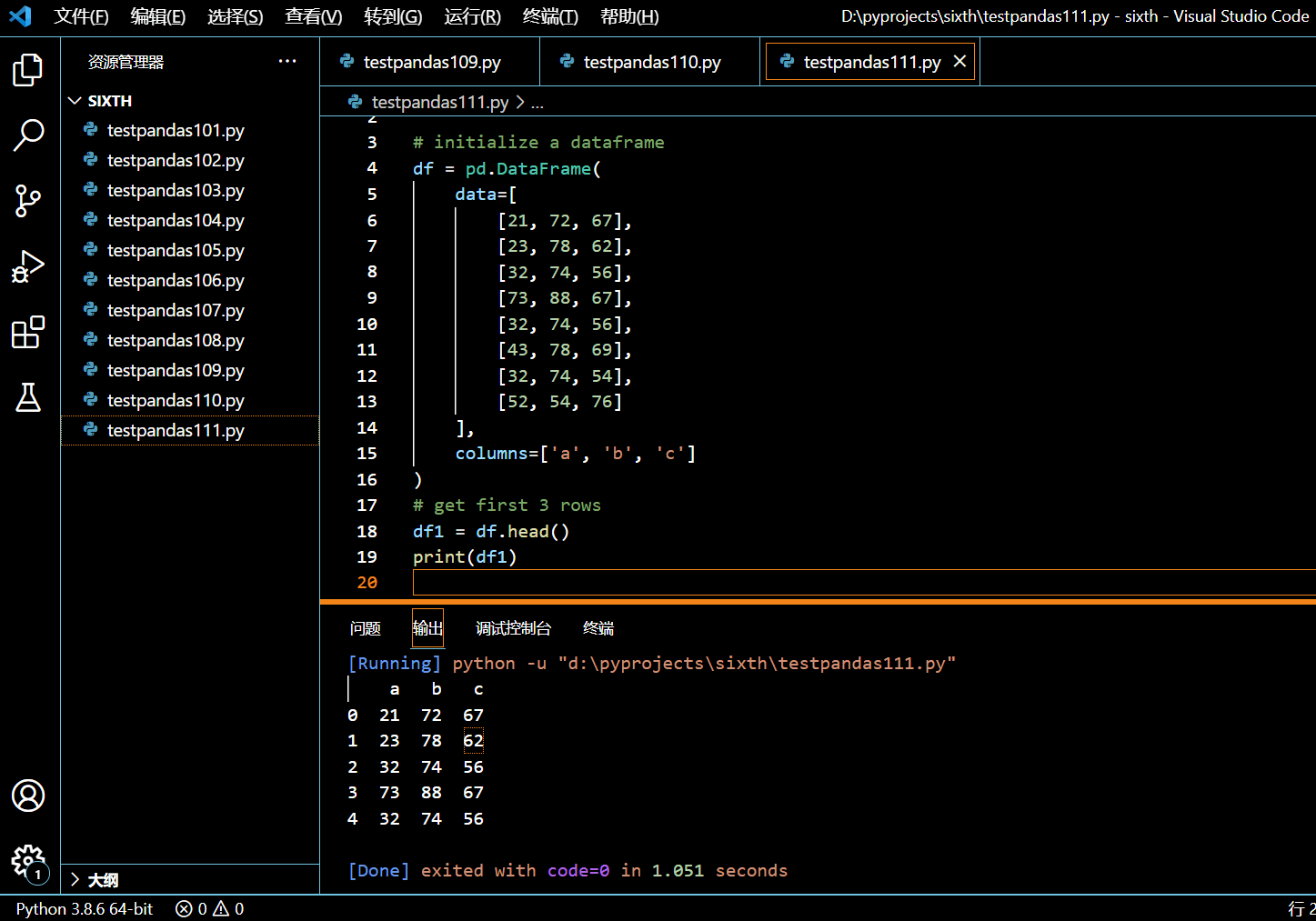
6.3.3. 小结
通过本节示例我们了解到了如何使用 pandas.DataFrame.head() 方法提取 Pandas DataFrame 前 N 行数据。
6.4. 如何获取 Pandas DataFrame 的行数?
要获取一个 DataFrame 里的行数,你可以使用 DataFrame.shape 属性或者 DataFrame.count() 方法。
DataFrame.shape 属性将返回一个元组,该元组的第一个元素是 DataFrame 的行数,第二个元素是 DataFrame 的列数。通过第一个元素的索引我们就可以获取到 DataFrame 的行数了。
DataFrame.count(),不传任意参数就使用默认参数值。它将返回每一列的值的个数。在 DataFrame 中,所有列都拥有同样个数的值,也就是每列的行数一致。通过第一个元素的索引,我们就可以获取到 DataFrame 的行数了。
6.4.1. 获取行数 - DataFrame.shape
本示例中,我们将使用 DataFrame.shape 属性来获取 DataFrame 的行数。
import pandas as pd
# initialize dataframe
df = pd.DataFrame(
data={
'a': [1, 4, 7, 2],
'b': [2, 0, 8, 7]
}
)
# number of rows in dataframe
num_rows = df.shape[0]
print('Number of Rows in DataFrame:', num_rows)
执行和输出:
6.4.2. 获取行数 - DataFrame.count()
本示例中,我们将使用 DataFrame.count() 方法来获取 DataFrame 的行数。
import pandas as pd
# initialize dataframe
df = pd.DataFrame(
data={
'a': [1, 4, 7, 2],
'b': [2, 0, 8, 7]
}
)
# number of rows in dataframe
num_rows = df.count()[0]
print('Number of Rows in DataFrame:', num_rows)
执行和输出:
6.4.3. 小结
通过本文示例,我们了解到了获取指定 DataFrame 行数的两种办法。
6.5. 如何对 Pandas DataFrame 的行进行过滤?
可以使用 DataFrame.isin() 来对 Pandas DataFrame 的行进行过滤。isin() 将返回源 DataFrame 中符合过滤条件的行。
你也可以使用 DataFrame.query() 来过滤掉符合指定布尔表达式的行。
6.5.1. 过滤 DataFrame 的行 - DataFrame.isin()
本示例中,我们将新建一个四行两列的 DataFrame。我们将根据列 a 中的值是否在指定区间内来过滤这个 DataFrame。
import pandas as pd
# initialize dataframe
df = pd.DataFrame(
data={
'a': [2, 4, 8, 5],
'b': [2, 0, 9, 7]
}
)
# check if the values of df['a'] are in the range(3, 6)
out = df['a'].isin(range(3, 6))
# filter dataframe
filtered_df = df[out]
print('Original DataFrame\n-------\n', df)
print('\nFiltered DataFrame\n-------\n', filtered_df)
执行和输出:
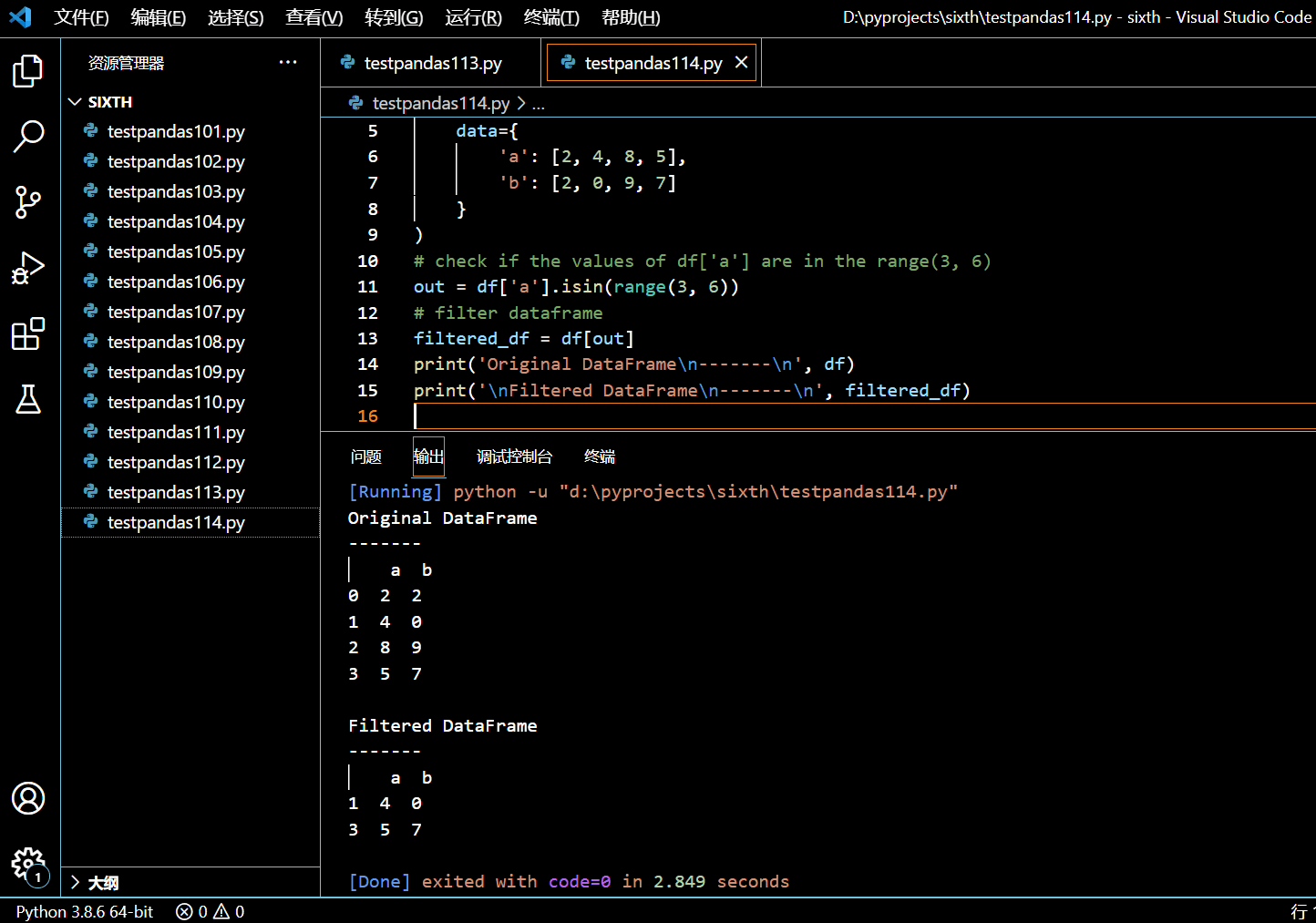
对于列 a 中在 range(3,6) 区间的值 isin() 函数返回 True,否则返回 False。
df[out] 只返回这些值为 True 的行,进而产生过滤后的输出。
6.5.2. 过滤 DataFrame 的行 - DataFrame.query()
本示例中,我们仍将初始化一个四行两列的 DataFrame,然后将满足列 b 的值大于 4 的行过滤出来。
import pandas as pd
# initialize dataframe
df = pd.DataFrame(
data={
'a': [1, 4, 7, 2],
'b': [2, 0, 8, 7]
}
)
# get the rows that b > 4
filtered_df = df.query(expr='b > 4')
print('Original DataFrame\n-------\n', df)
print('\nFiltered DataFrame\n-------\n', filtered_df)
执行和输出:
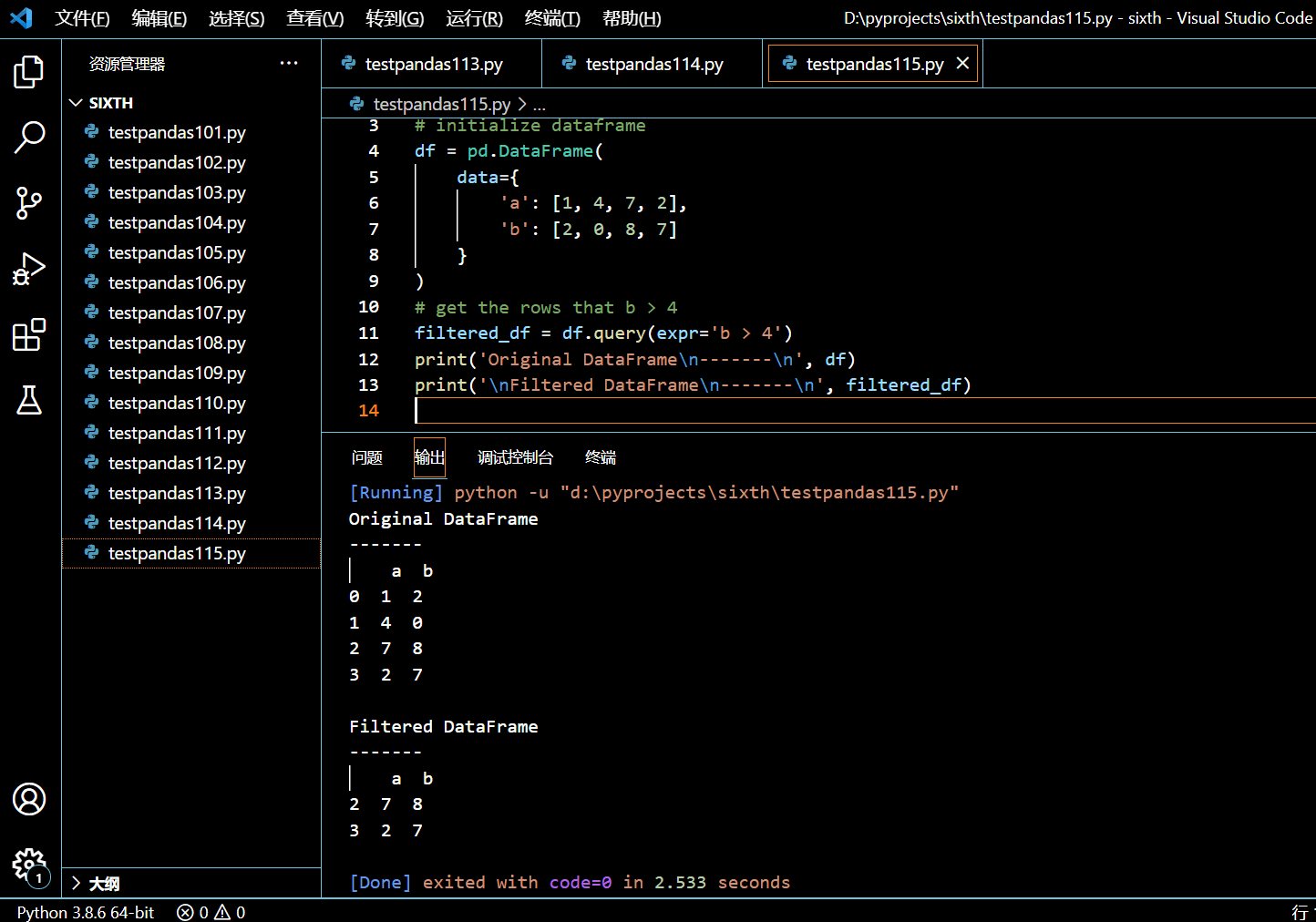
6.5.3. 小结
本节我们了解了如何根据列值过滤 DataFrame。
6.6. Pandas DataFrame - 根据索引排序
可以使用 DataFrame.sort_index() 方法将 Pandas DataFrame 根据索引进行排序。
要指定该方法是根据索引对 DataFrame 进行正序还是逆序排序,你可以指定 ascending 参数为 True 还是 False。
索引被排序后,相对应的行将被重新排列。
6.6.1. 将 DataFrame 根据索引正序排序
本示例中,我们将创建一个多行、由一组数字组成索引的 DataFrame。我们将把 DataFrame 里的行根据索引进行正序排序。
要依据索引进行正序排列,可以像下面程序这样将 ascending=True 参数传给 sort_index() 方法。或者直接忽略掉 ascending 参数,因为其默认值就是 True。
import pandas as pd
# create a dataframe
df_1 = pd.DataFrame(
data=[
['Arjun', 70, 86],
['Kiku', 80, 76],
['Mama', 99, 99],
['Lini', 79, 92]
],
index=[2, 1, 6, 5],
columns=['name', 'aptitude', 'cooking']
)
print(df_1)
# sort dataframe by index in ascending order
df_1 = df_1.sort_index(ascending=True)
print('\nDataFrame after sorting by index\n')
print(df_1)
执行和输出:
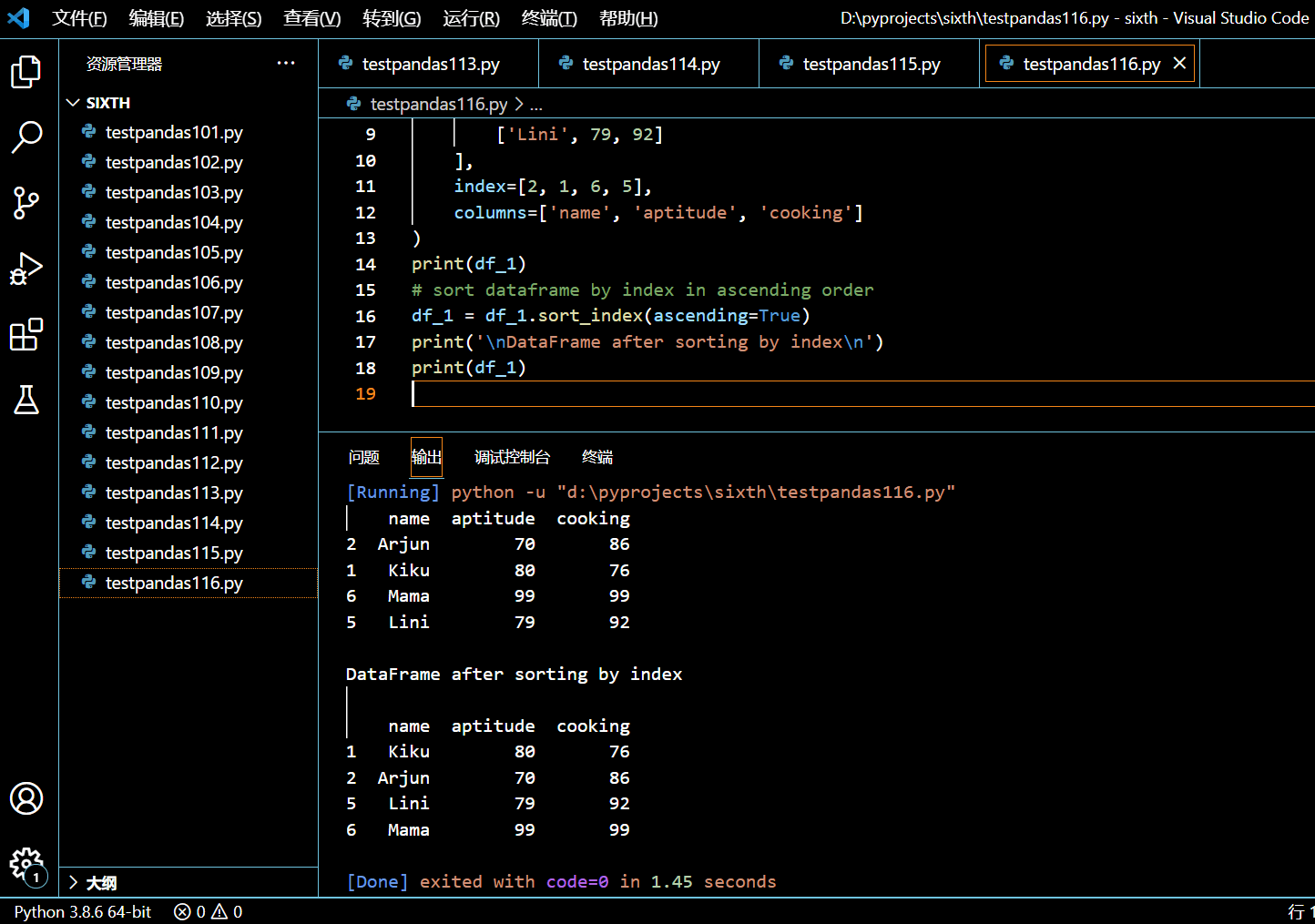
6.6.2. 将 DataFrame 根据索引逆序排序
接下来的示例中,我们将根据索引对 DataFrame 进行逆序排序。所以呢,我们将把参数 ascending=False 传给 sort_index() 方法。
import pandas as pd
# create a dataframe
df_1 = pd.DataFrame(
data=[
['Arjun', 70, 86],
['Kiku', 80, 76],
['Mama', 99, 99],
['Lini', 79, 92]
],
index=[2, 1, 6, 5],
columns=['name', 'aptitude', 'cooking']
)
print(df_1)
# sort dataframe by index in ascending order
df_1 = df_1.sort_index(ascending=False)
print('\nDataFrame after sorting by index\n')
print(df_1)
执行和输出:
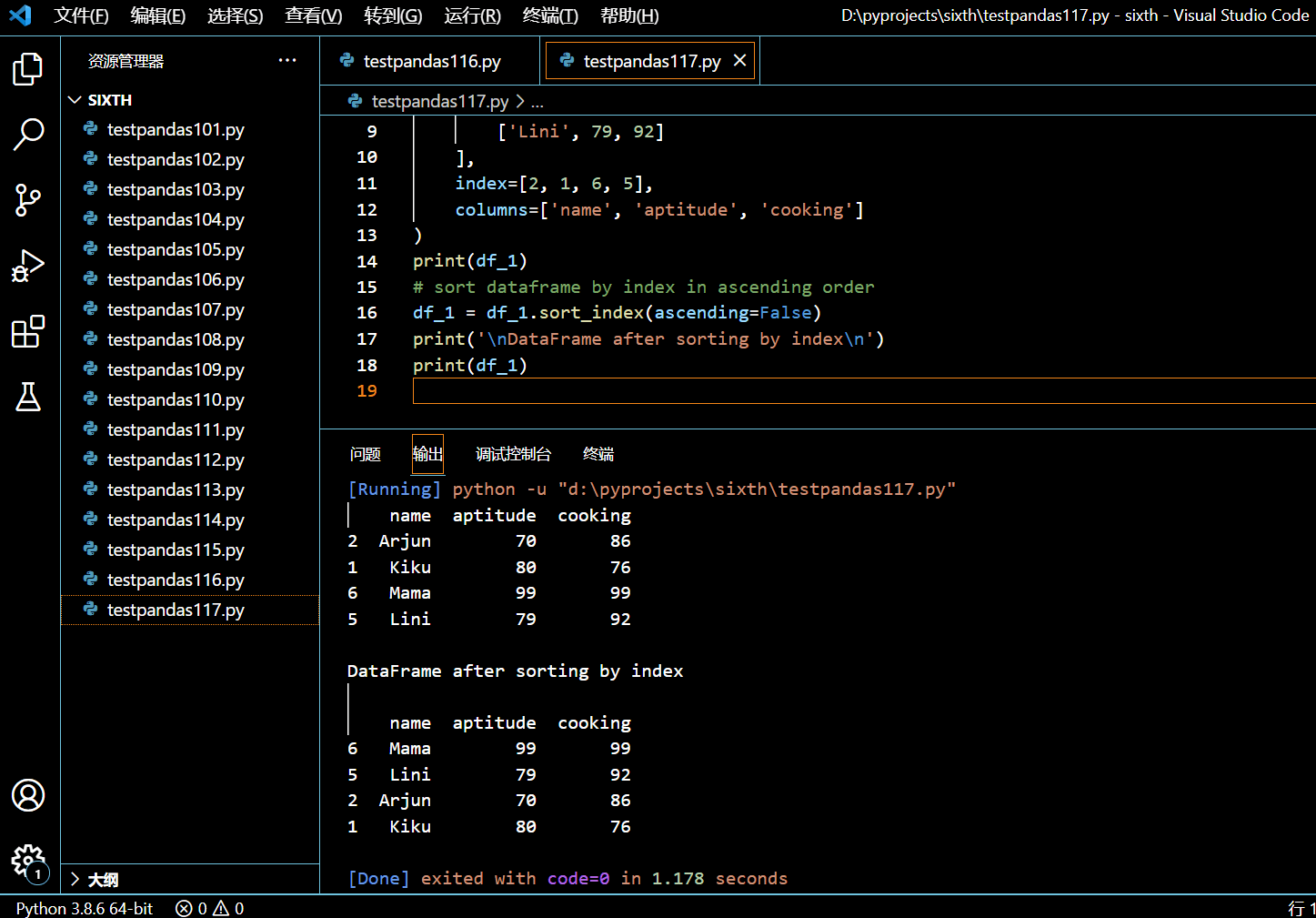
6.6.3. 小结
通过本节示例,我们了解到了如何将一个 DataFrame 根据索引进行升序或逆序排序。
6.7. 如何对 Pandas DataFrame 里行内的元素进行迭代?
要对 Pandas DataFrame 行中的元素进行遍历,你可以索引递增使用 DataFrame.at[],或者先拿到行然后使用 Series.items()。
6.7.1. 对行里的元素进行遍历 - 使用索引
本示例中,我们将
- 初始化一个载有若干数字的 DataFrame。
- 拿到指定行。
- 拿到列数。
- 使用 for 循环对其中元素进行迭代。
import pandas as pd
import numpy as np
df = pd.DataFrame(
data=[
['a', 'b', 'c'],
['d', 'e', 'f'],
['g', 'h', 'i'],
['j', 'k', 'l']
]
)
# index = 1 => second row
row = df.iloc[1]
length = row.size
for i in range(length):
print(row[i])
执行和输出:
6.7.2. 对行里的元素进行遍历 - 使用 Series.items()
在接下来的示例中,我们将
- 初始化一个载有若干数字的 DataFrame。
- 使用 DataFrame.iloc 属性拿到指定行。
- 使用 Series.items() 对该行中元素进行迭代。
import pandas as pd
import numpy as np
df = pd.DataFrame(
data=[
['a', 'b', 'c'],
['d', 'e', 'f'],
['g', 'h', 'i'],
['j', 'k', 'l']
]
)
# index = 1 => second row
row = df.iloc[1]
for index, item in row.items():
print(item)
执行和输出:
6.7.3. 小结
通过本文的示例,我们了解了如何对 Pandas DataFrame 内指定行进行元素的遍历。
6.8. 如何使用索引获取 Pandas DataFrame 中的指定行?
要使用索引获取 Pandas DataFrame 里指定行,使用 DataFrame.iloc 属性,然后在中括号中给出该行索引。
DataFrame.iloc[row_index]
DataFrame.iloc 将行返回为 Series 对象。
6.8.1. 获取 Pandas 中指定的行
在接下来的示例中,我们将
- 初始化一个载有多个数字的 DataFrame。
- 使用 DataFrame.iloc 属性获取指定行。
import pandas as pd
import numpy as np
df = pd.DataFrame(
data=[
['a', 'b', 'c'],
['d', 'e', 'f'],
['g', 'h', 'i'],
['j', 'k', 'l']
]
)
# index = 1 => second row
row = df.iloc[1]
print(row)
执行和输出:
控制台打印的输出中,0、1 和 2 是列索引;d、e、f 是行内容。
6.8.2. 小结
通过本节示例,我们了解到了如何通过 DataFrame.iloc 属性来获取 Pandas DataFrame 里的指定行。
7. Pandas 转换
7.1. 将 Pandas DataFrame 转换为 Numpy 数组
你可以将一个 Pandas DataFrame 转换为 Numpy 数组,以执行 numpy 包所提供的一些高级数学函数。
要将 Pandas DataFrame 转换为 Numpy 数组,使用 DataFrame.to_numpy() 函数,它将返回一个 Numpy ndarray 类型的对象。通常返回的 ndarray 是两维的。
7.1.1. DataFrame 到 Numpy 数组
接下来我们来将 DataFrame 转换为 Numpy 数组。
import pandas as pd
# initialize a dataframe
df = pd.DataFrame(
data=[
[21, 72, 67],
[23, 78, 69],
[32, 74, 56],
[52, 54, 76]
],
columns=['a', 'b', 'c']
)
print('DataFrame\n-------\n', df)
# convert dataframe to numpy array
arr = df.to_numpy()
print('\nNumpy Array\n-------\n', arr)
执行和输出:
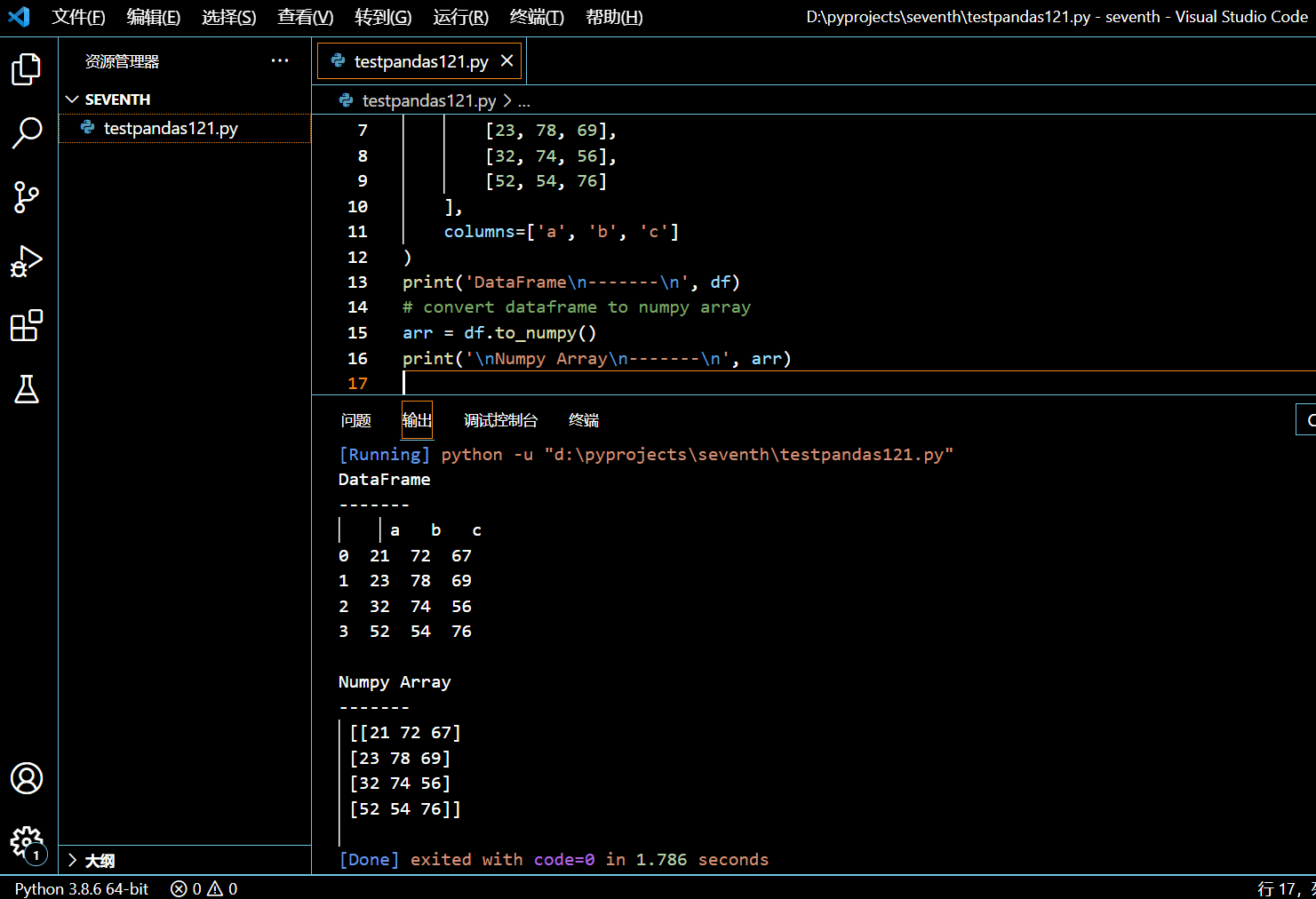
7.1.2. 不同数据类型组成的 DataFrame 到 Numpy 数组
如果你的 DataFrame 具有不同数据类型的列,返回的 Numpy 数组将由单一数据类型的元素组成。DataFrame 中最低的数据类型将被认作为 Numpy 数组的数据类型。
在接下来的示例中,该 DataFrame 含有 int64 和 float64 数据类型的列。当该 DataFrame 被转换为 Numpy 数组时,int64 和 float64 的最低数据类型,也就是 float64 将被选中。
import pandas as pd
import numpy as np
# initialize a dataframe
df = pd.DataFrame(
data=[
[21, 72, 67.1],
[23, 78, 69.5],
[32, 74, 56.6],
[52, 54, 76.2]
],
columns=['a', 'b', 'c']
)
print('DataFrame\n-------\n', df)
print('\nDataFrame datatypes:\n', df.dtypes)
# convert pandas dataframe to numpy array
arr = df.to_numpy()
print('\nNumpy Array\n-------\n', arr)
print('\nNumpy Array Datatype: ', arr.dtype)
执行和输出:
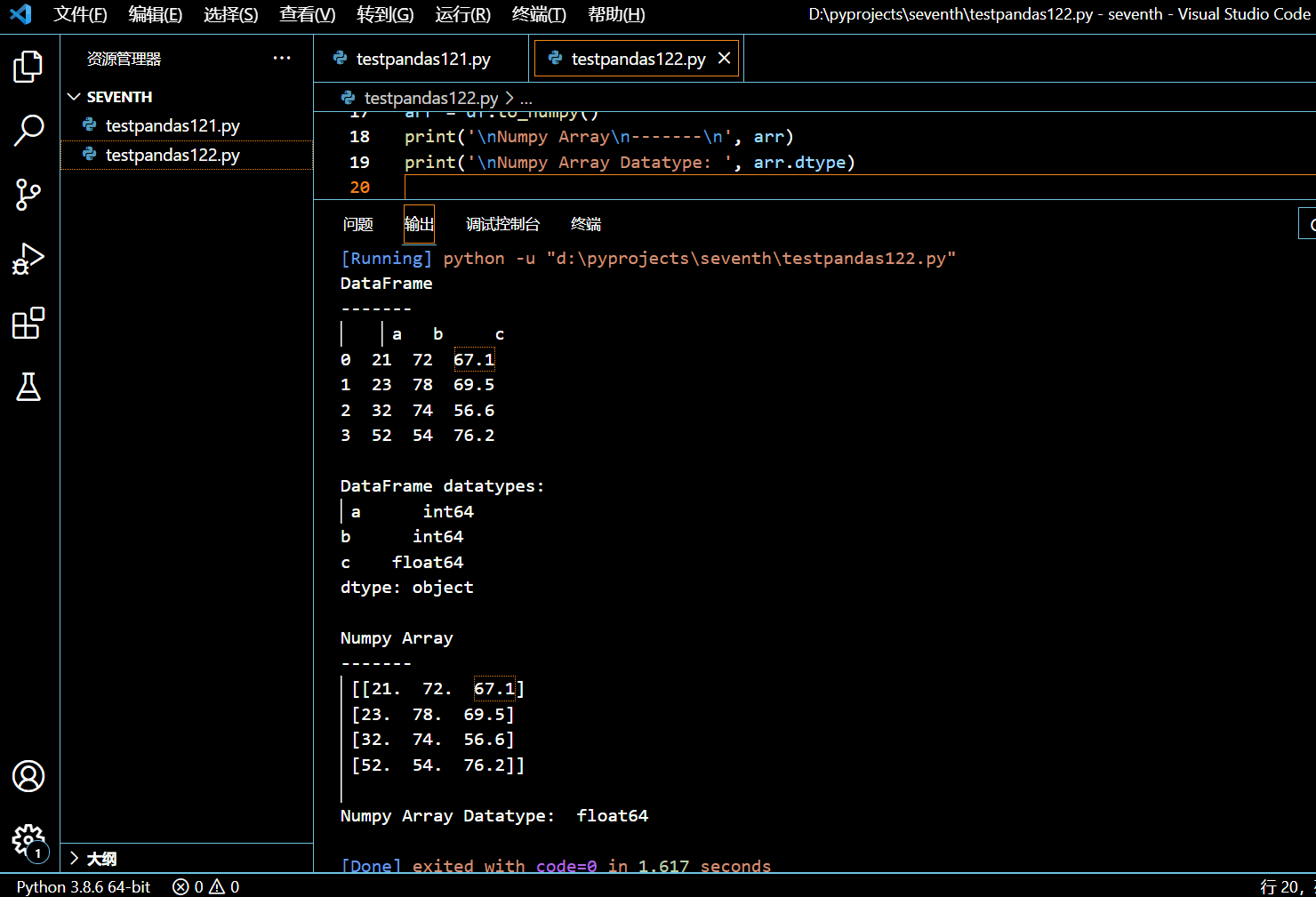
可见返回的 Numpy 数组的数据类型是为 float64。
7.1.3. 小结
通过本节的示例,我们了解到了如何将 Pandas DataFrame 转换为 Numpy Array。
总结
通过本文的 Python 示例,我们对 Python Pandas 的相关概念有了一些了解。
参考资料
- Python Pandas Examples
- Pandas Series Example
- Pandas – Create or Initialize DataFrame
- Pandas DataFrame – Change Column Labels
- Pandas – Construct DataFrame from Dictionary
- Pandas DataFrame – Load Data from CSV File
- Pandas DataFrame – Sort by Column
- Pandas DataFrame – Iterate Rows – iterrows()
- Pandas DataFrame – Add Row
- Pandas DataFrame – Add Column
- Pandas DataFrame – Delete Column
- Pandas Append or Concatenate DataFrames
- Pandas DataFrame – Reset Index

 浙公网安备 33010602011771号
浙公网安备 33010602011771号