最新YOLO实现的行人车辆检测与计数检测平台(Flask+SocketIO+HTML_CSS_JS)
摘要
本文面向“行人/车辆检测与计数”的真实场景,构建了一个基于 Flask + Flask-SocketIO + HTML/CSS/JS 的Web 网页界面端到端平台,后端集成 YOLOv5–YOLOv12(共 8 种)与多目标跟踪以实现实时检测、区域/过线计数与流量统计。系统支持图片/视频/浏览器摄像头输入,提供双画面对比(原图/检测图同步对齐)、进度控制(播放/暂停/继续/停止与拖拽进度)、Conf/IoU 调节与类别筛选,并可CSV 导出计数与置信度明细、带框结果一键下载(图片/视频/截图)。平台内置SQLite 入库记录任务、参数与结果,含登录/注册(可跳过)的轻量会话与权限管理;可在前端完成模型选择/权重上传与热切换,自动刷新类别与统计项。实验对 YOLOv5–YOLOv12 的 mAP、F1、PR 曲线与训练曲线进行横向比较,结合延迟、参数量与显存占用给出部署建议;提供从数据准备、训练到推理与可视化的一键流程与浏览器端实时演示。文末提供完整工程与数据集下载链接,便于复现与二次开发。
讲解视频地址:基于深度学习的行人车辆检测与计数(Web系统+完整项目分享+数据集+多YOLO模型)
YOLOv12-v11/v10/v9/v8/v7/v6/v5系统(八个模型,含说明论文)合集下载:https://mbd.pub/o/bread/YZWck55yaQ==
说明论文下载:https://mbd.pub/o/bread/YZWck5xpZw==
YOLOv12下载:https://mbd.pub/o/bread/YZWbmppqaQ==
YOLOv11下载:https://mbd.pub/o/bread/YZWbm5ppbA==
YOLOv10下载:https://mbd.pub/o/bread/YZWbm5lqZw==
YOLOv9下载:https://mbd.pub/o/bread/YZWbmp9wZQ==
安装与教程文档:https://deeppython.feishu.cn/wiki/H8DowTJktiEdfFkGNxEc9KzHnLh
@
1. 网页功能与效果
(1)登录注册:提供登录、注册与一次性跳过三种入口;会话在当前浏览器与本工作区内生效,并支持超时自动失效。口令采用哈希存储与最小化权限策略,兼顾体验与安全。首次进入会引导完善昵称与偏好,后续可在资料页修改或直接注销/切换账号。

(2)功能概况:导航遵循“概览 → 图片检测 / 视频检测 / 摄像头检测 → 模型选择 → 导出视图”的动线,常用操作在页首聚合。支持 Conf/IoU 调节、目标类别筛选、结果标注样式切换与一键清空缓存;“检测记录”在多页共享,CSV 可高亮定位关键字段并快速回放。

(3)视频检测:提供等宽左右双画面(原始/检测)同步显示,保持 16:9 自适应不拉伸。具备播放、暂停、继续、停止与拖拽进度控制,支持关键帧截图与段落导出;浏览器摄像头实时推理并可将缓冲一键导出为 MP4,同时支持 CSV 明细与带框视频下载。

(4)更换模型:前端上传权重即可切换当前模型,自动刷新类别列表、默认阈值与配色方案,并保留历史权重以便对照测试。路径规范跨平台兼容,数据库自动迁移保障版本升级后记录与配置持续可用;页面标题与品牌元素可编辑并本地保存。

(5)概览界面:展示最近任务、计数统计与资源占用的轻量总览卡片,可一键跳转到对应数据与导出面板。支持按文件名或时间范围筛选并高亮当前会话生成的结果,批量下载与溯源信息集中管理,便于审计与复现。

2. 绪论
2.1 研究背景与意义
随着城市交通数字化与多源视频感知的普及,路口与道路监控对“行人/车辆检测与计数”的实时性与稳定性提出了更高要求,核心目标是在百毫秒量级时延内完成准确检测、跨线/区域计数与可视化统计,以支撑信号配时优化与事件告警[1]。与静态图像识别不同,连续视频中的小目标、遮挡、光照与天气变化会显著影响召回与精度,因此亟需将高效检测器与稳健跟踪计数策略协同设计,并在边缘端完成低耗部署[2]。在工程侧,基于 Flask+SocketIO 的 Web 平台可将模型推理、状态管理与可视化整合为闭环,一方面便于在多路摄像头间统一配置与审计,另一方面为数据闭环、持续学习与可追溯导出提供了基础设施支撑[3]。
2.2 国内外研究现状
从任务特征看,行人与车辆的尺寸差异显著、密集遮挡频繁、类间相似度高(如两轮车与行人、轿车与SUV),再叠加昼夜与雨雾等域偏移,导致定位与分类同时受挑战;主流做法通过多尺度特征融合与注意力机制增强细粒度表征,并以改进的回归损失缓解定位误差对计数稳定性的影响[4]。Anchor-free 的单阶段检测成为实时视频的主流:YOLOX 通过解耦头与 SimOTA 标签分配兼顾了小模型速度与大模型精度,为拥挤场景提供了较好的均衡[5];PP-YOLOE 以结构演化与任务自适应标签分配(TAL)获得更高吞吐,适合大分辨率视频推理[6]。两阶段方法(Faster R-CNN)在精度与可解释性上仍具优势,但在边缘侧多路并发时延相对较高[7]。
YOLO 家族在近年围绕数据增强、骨干/颈部结构与解耦头持续演进:YOLOv7 引入可训练的“免费与特技”组合,显著提升了实时检测的精度/速度上限[8];YOLOv8 提供端到端实用工程基线,便于数据与推理导出流水线的一体化管理[9];YOLOv9 通过可编程梯度(PGI)与 GELAN 骨干提升收敛与多尺度表现,对复杂背景下的小目标更稳健[10];YOLOv10 倡导一致性双分配并弱化 NMS 依赖,在相近精度下降低整体延迟,利于计数链路端到端优化[11];社区新近的 YOLOv11/12 在边缘与云端协同、注意力中心化等方面探索,以进一步压缩时延并强化密集场景表现[12]。与之平行,Transformer 检测器将检测建模为集合预测,RT-DETR 通过高效解码与匹配实现端到端实时,为“无后处理/弱后处理”的部署形态提供了新范式[13]。
工程与部署研究强调将训练-导出-加速贯通:ONNX/TensorRT 推理、INT8 量化与剪枝可在不显著损失精度的前提下带来 1.5–3 倍的时延优化,适合 Jetson/独显等边缘硬件的大并发流媒体处理[14]。在中文交通场景文献中,针对道路监控的改进 YOLOv5/7/8 方法表明,结合坐标注意力、空间到深度与轻量化骨干,可在 KITTI/自建路侧数据上同时提升 mAP 与帧率,为计数稳定性与可视化落地提供可复用的工程证据[15]。多目标跟踪方面,ByteTrack 的“全框关联”策略显著提高遮挡段落下的轨迹连续性,叠加过线/区域逻辑后可有效降低误计/漏计[16]。
表1 典型检测器在交通视频场景的对比(节选)
| 方法 | 范式/家族 | 数据集 | 关键改进 | 优势与局限 | 指标(原文报告) | 适用难点 |
|---|---|---|---|---|---|---|
| Faster R-CNN | 两阶段/Anchor-based | COCO | RPN+共享特征 | 精度高、时延大 | 早期实现约数FPS@VGG16[7] | 需要高精度但低并发 |
| YOLOX-L | 单阶段/Anchor-free | COCO | 解耦头+SimOTA | 精度/速度均衡 | 50.0 AP@68.9 FPS(V100)[5] | 多路实时、泛化 |
| PP-YOLOE-l | 单阶段/Anchor-free | COCO | CSPRepRes+TAL | 吞吐高、部署友好 | 51.4 mAP@78.1 FPS(V100)[6] | 大分辨率吞吐 |
| YOLOv7 | 单阶段/YOLO | COCO | 可训练BoF/BoS | 工程成熟 | 实时检测SOTA(原文)[8] | 稳态高吞吐 |
| YOLOv9-C | 单阶段/YOLO | COCO | PGI+GELAN | 收敛/多尺度优 | 多项子集优于前代[10] | 复杂背景稳健 |
| YOLOv10-S | 单阶段/NMS-free | COCO | 一致性双分配 | 端到端低时延 | 同级精度更快[11] | 低时延计数 |
| RT-DETR-R18 | 端到端/Transformer | COCO | 高效解码/匹配 | 省后处理 | 实时/精度平衡[13] | 简化后处理 |
| CenterNet | 单阶段/Anchor-free | COCO | 中心点回归 | 结构简洁 | 28.1 AP@142 FPS[17] | 超高帧率场景 |
上述对比提示:当侧重“吞吐+并发”时,可优先 YOLOv8/YOLOX/PP-YOLOE 等 Anchor-free 单阶段器;当希望减少后处理复杂度与跨端一致性时,RT-DETR 与 YOLOv10 的一致性训练更具工程吸引力[11]。
2.3 要解决的问题及其方案
(1)检测准确性与实时性的平衡:在遮挡、小目标与类间相似条件下维持高召回与低时延;方案:采用 YOLOv12 作为核心并对比 YOLOv5–YOLOv11,结合 CIoU/SIoU 损失、Mosaic/Copy-Paste 等增强与多尺度训练,按分辨率-帧率-显存三元组选型[10]。
(2)环境适应性与泛化:应对昼夜、雨雾与摄像机域偏移导致的性能波动;方案:引入风格/天气增强与迁移学习,比较 Anchor-free(YOLO)与端到端(RT-DETR)在域外数据上的稳健性,并通过置信度/IoU 动态阈值稳定计数。
(3)网页端交互的直观性与完整性:实现双画面对比、同步双帧与过线/区域计数的人机协同;方案:以 Flask+SocketIO 实现参数热更新、进度控制与帧级对齐,提供 CSV/带框结果导出与“检测记录”跨页共享。
(4)数据处理效率与存储安全:保障多路视频并发下的连续性与可追溯;方案:SQLite 记录任务、计数与参数快照,支持批量导出、会话/权限约束与异常恢复,结合 ONNX/TensorRT、量化与流水线并行降低端到端时延[14]。
2.4 博文贡献与组织结构
贡献:(1)提出面向行人/车辆“检测-计数”的端到端 Web 平台,实现图片/视频/摄像头三源输入、双画面对比与同步双帧的人机协同;(2)在 YOLOv5–YOLOv12 范围内构建统一训练-评测-导出流水线,系统对比 mAP、F1、PR 曲线与延迟/显存;(3)提供权重热切换、记录入库、CSV/带框导出与结果溯源的工程方案,便于复现与审计;(4)给出针对遮挡、小目标与域偏移的改进策略与部署建议,覆盖边缘侧加速与稳定性治理。组织结构如下:第3章介绍数据集来源、标注规范与增强策略;第4章阐述模型原理与设计(以 YOLOv12 为主线);第5章展示实验结果、可视化与分析;第6章说明系统设计与实现(含流程/框图与登录流程);第7章总结与未来工作。
3. 数据集处理
本研究使用含 5542 张图像的数据集,按可复现实验划分为 2856/1343/1343(训练/验证/测试),对应约 51.5%/24.2%/24.2% 的比例,并在工程中固定随机种子(如 42)以避免数据泄漏与结果波动。标注采用 YOLO 格式(class cx cy w h,中心坐标与宽高均归一化至 [0,1]),类别共 7 个:person/bicycle/car/motorcycle/bus/truck/train,对应中文名 {行人、自行车、小汽车、摩托车、公交车、卡车、火车}。从你提供的 x,y,width,height 分布图看,目标中心在 y≈0.5 附近更为密集,width/height 呈明显右偏长尾,小目标占比高;Mosaic 样例与标注可视化进一步表明场景多样(道路、站台、夜景、低光与运动模糊并存),长宽比差异显著且存在遮挡与类间相似(行人与两轮车、轿车与 SUV 等),这要求后续训练在小目标与拥挤区域给予更强的表征与正负样本平衡。
Chinese_name = {'person': "行人", 'bicycle': '自行车', 'car': '小汽车', 'motorcycle': '摩托车',
'bus': '公交车', 'truck': '卡车', 'train': '火车'}

在数据处理流程上,首先进行一致性与清洗:统一分辨率与色彩空间,移除损坏/极端低分辨率样本,校正异常或重叠冲突标注,并按文件名哈希进行稳定划分以保持各集合类别占比与尺度分布一致。随后采用与 YOLO 训练兼容的增强策略:基础增强含随机缩放/裁剪、水平翻转与 HSV 抖动;针对小目标与密集遮挡,启用 Mosaic/MixUp/Copy-Paste 提升长尾类别与小尺寸目标的可见频次;对夜景与雨雾样本,加入亮度对比度、运动模糊与伪雾化变换以增强域鲁棒;对于超宽/超高 全景图,在保持标注合法的前提下进行滑窗或带重叠裁切,避免训练时的过度缩放导致目标消失。统计结果(直方图与成对散点)用于在线监控类别与尺度分布漂移;训练与验证阶段同步输出错误样例墙(如漏标/错标与极端遮挡帧)以便迭代修正。最终,类别映射以你提供的 Chinese_name 为准,推理与 Web 端显示统一采用中文标签,导出至 CSV 与 SQLite 时保留中英对照与归一化坐标,确保结果可追溯与跨平台一致。

4. 模型原理与设计
本文以YOLOv12为主线、兼容 YOLOv5–YOLOv11 的实现体例进行建模:在单阶段、Anchor-free 与解耦检测头范式下,将输入图像经轻量骨干网络提取多尺度特征,借助金字塔式颈部结构进行自顶向下/自底向上融合,最后在各尺度上并行预测类别、位置与目标性分数。整体推理链路遵循“图像归一化 → 多尺度特征抽取 → 特征融合 → 解耦头预测 →(可选)NMS/或一致性匹配”的流程,强调实时性与小目标召回;针对行人与车辆尺寸差异与遮挡问题,模型采用更密集的中低层特征参与融合,并在计数环节与过线逻辑解耦,以减少后处理对时延的影响。网络整体架构图(以典型 YOLO-X/解耦头结构为示例)如下图所示:

在结构设计上,骨干以 CSP/ELAN 系列为参照,结合深浅层多分支与轻量注意力。以通道注意力为例,先行全局平均池化得到通道描述子 \(z\in\mathbb{R}^{C}\),再经两层瓶颈映射与 Sigmoid 得到通道权重 \(s\),用于重标定特征 \(x\):
其中 \(\mathrm{GAP}\) 为全局平均池化,\(\delta(\cdot)\) 为ReLU,\(\sigma(\cdot)\) 为Sigmoid,\(W_1,W_2\) 为可学习矩阵,\(\odot\) 表示逐通道乘。颈部采用加权特征金字塔(如 BiFPN/PAN 的可学习融合),对不同分辨率的特征 \(P_j\) 引入非负权重 \(w_j\) 并归一化:
其中 \(\mathrm{Resize}(\cdot)\) 统一分辨率,\(\varepsilon\) 防止除零。检测头采取解耦设计,即分类与回归分支各自两到三层轻量卷积/可分离卷积后输出类别分布 \(\mathbf{p}\in[0,1]^K\) 与边界框参数 \(\mathbf{b}=(x,y,w,h)\) 及目标性分数 \(o\in[0,1]\);该设计降低了梯度耦合,提升了密集场景的收敛稳定性。
在损失与任务建模方面,分类分支使用 Focal Loss 抑制易样本主导:
其中 \(p\) 为预测概率,\(y\in{0,1}\) 为真值,\(\alpha\) 为类不平衡系数,\(\gamma\) 调节难样本关注。回归分支采用 IoU 家族损失以贴合评测指标,如 CIoU:
其中 \(\mathrm{IoU}\) 为预测与真值框交并比,\(\rho\) 为两框中心点距离,\(d\) 为包围两框的最小外接框对角线长度,\(v\) 衡量宽高比一致性,\(\alpha\) 为平衡系数。为提升匹配质量,训练阶段采用动态标签分配(如 SimOTA/TAL 思想):给定候选框 \(i\) 与标注 \(j\),构造综合代价
其中 \(\mathbb{1}\) 指示候选是否落入标注的中心区域,\(\lambda*{1,2,3}\) 为权重;推理阶段可采用 NMS-free/一致性打分(如将 \(o\cdot \max_k p_k\) 作为排序指标并以任务对齐的抑制策略替代传统 NMS),减少后处理带来的时延与不一致。为契合计数需求,模型输出除常规框外同步提供轨迹初始化置信度(由 \(o\) 与局部密度先验融合),便于与跟踪/过线模块低代价对接。
训练与正则化方面,采用Cosine 学习率退火与 EMA 权重滑动平均稳定收敛;对行人/车辆场景的长尾与小目标问题,启用 Mosaic、MixUp、Copy-Paste 与尺度抖动,并对夜景/雨雾样本加入亮度对比度扰动与运动模糊。阈值与后处理策略以任务约束为导向:分类阈值 \(t_{cls}\) 与 IoU 阈值 \(t_{iou}\) 在验证集上通过网格/贝叶斯搜索联合选取,以最大化 \(\mathrm{F1}=\frac{2PR}{P+R}\)(\(P\) 为精度,\(R\) 为召回)。在线部署时,导出 ONNX/TensorRT 并结合 FP16/INT8 量化与 层融合(Conv+BN)降低端到端延迟;为保证浏览器端“同步双帧”与过线计数稳定,推理侧对视频流启用时间一致性滤波(如对 \(o\) 与框中心采用指数滑动平均)与框级去抖(短时抑制跳变),在不增加模型复杂度的前提下提升计数鲁棒性。总体而言,该设计在保证实时性的同时,对小目标、遮挡与尺度差异等关键难点提供了结构与训练两端的针对性支撑。
5. 实验结果与分析
本节在 RTX 3070 Laptop 8GB 环境下,对 YOLOv5nu、YOLOv6n、YOLOv7-tiny、YOLOv8n、YOLOv9t、YOLOv10n、YOLOv11n、YOLOv12n 与 YOLOv5su、YOLOv6s、YOLOv7、YOLOv8s、YOLOv9s、YOLOv10s、YOLOv11s、YOLOv12s 进行统一评测,指标含 Precision、Recall、F1、mAP@0.5、mAP@0.5:0.95 及 预处理/推理/后处理时延。

数据来自第3章所述的 5542 张图像并按 2856/1343/1343 划分;计时采用同一数据管线与批量 1 的在线推理设置。总体上,n 型侧 YOLOv9t 以 mAP@0.5=0.586、F1=0.596 居首,但推理时延较高;YOLOv6n/YOLOv8n 以 6.78/6.83 ms 的推理时间领先速度;YOLOv10n 的 后处理耗时 0.63 ms 最低,符合其弱化 NMS 的特征。

s 型侧 YOLOv7 凭借更大计算量取得 mAP@0.5=0.660、F1=0.676 的最高精度,但推理 23.62 ms 明显慢于 YOLOv8s(7.66 ms) 与 YOLOv6s(8.59 ms);综合“精度×吞吐”的折中,YOLOv9s/YOLOv11s 更均衡。

注:Total(ms)=Pre+Inf+Post;FPS=1000/Total,批量=1,设备:RTX 3070 Laptop 8GB。
表5-1 轻量组(n 型)完整结果
| Model | Params(M) | FLOPs(G) | PreTime(ms) | InfTime(ms) | PostTime(ms) | Total(ms) | FPS | Precision | Recall | F1 Score | mAP50 | mAP50-95 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| YOLOv5nu | 2.6 | 7.7 | 1.90 | 7.73 | 1.31 | 10.94 | 91.49 | 0.6614 | 0.4812 | 0.5571 | 0.5349 | 0.3420 |
| YOLOv6n | 4.3 | 11.1 | 2.17 | 6.78 | 1.39 | 10.34 | 96.62 | 0.6296 | 0.4822 | 0.5462 | 0.5122 | 0.3261 |
| YOLOv7-tiny | 6.2 | 13.8 | 2.28 | 14.74 | 4.06 | 21.08 | 47.45 | 0.6845 | 0.4588 | 0.5494 | 0.5103 | 0.2859 |
| YOLOv8n | 3.2 | 8.7 | 1.95 | 6.83 | 1.39 | 10.17 | 98.34 | 0.6981 | 0.4921 | 0.5773 | 0.5509 | 0.3624 |
| YOLOv9t | 2.0 | 7.7 | 1.87 | 16.51 | 1.29 | 19.67 | 50.85 | 0.6913 | 0.5241 | 0.5962 | 0.5863 | 0.3932 |
| YOLOv10n | 2.3 | 6.7 | 2.08 | 11.24 | 0.63 | 13.95 | 71.68 | 0.7065 | 0.4988 | 0.5848 | 0.5571 | 0.3685 |
| YOLOv11n | 2.6 | 6.5 | 2.11 | 9.44 | 1.42 | 12.97 | 77.08 | 0.6713 | 0.5244 | 0.5888 | 0.5748 | 0.3774 |
| YOLOv12n | 2.6 | 6.5 | 1.91 | 12.47 | 1.37 | 15.75 | 63.49 | 0.6663 | 0.5111 | 0.5785 | 0.5671 | 0.3729 |
表5-2 标准组(s 型)完整结果
| Model | Params(M) | FLOPs(G) | PreTime(ms) | InfTime(ms) | PostTime(ms) | Total(ms) | FPS | Precision | Recall | F1 Score | mAP50 | mAP50-95 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| YOLOv5su | 9.1 | 24.0 | 2.28 | 8.45 | 1.51 | 12.24 | 81.70 | 0.6923 | 0.5383 | 0.6056 | 0.5983 | 0.3850 |
| YOLOv6s | 17.2 | 44.2 | 2.22 | 8.59 | 1.45 | 12.26 | 81.59 | 0.6448 | 0.4940 | 0.5594 | 0.5338 | 0.3398 |
| YOLOv7 | 36.9 | 104.7 | 2.44 | 23.62 | 3.46 | 29.52 | 33.87 | 0.7804 | 0.5958 | 0.6757 | 0.6597 | 0.4460 |
| YOLOv8s | 11.2 | 28.6 | 2.31 | 7.66 | 1.42 | 11.39 | 87.82 | 0.7160 | 0.5321 | 0.6105 | 0.5963 | 0.3935 |
| YOLOv9s | 7.2 | 26.7 | 2.12 | 18.66 | 1.39 | 22.17 | 45.08 | 0.7322 | 0.5423 | 0.6231 | 0.6207 | 0.4260 |
| YOLOv10s | 7.2 | 21.6 | 2.21 | 11.38 | 0.60 | 14.19 | 70.47 | 0.7101 | 0.5262 | 0.6045 | 0.6006 | 0.4041 |
| YOLOv11s | 9.4 | 21.5 | 2.37 | 9.74 | 1.36 | 13.47 | 74.27 | 0.7085 | 0.5504 | 0.6195 | 0.6085 | 0.4066 |
| YOLOv12s | 9.3 | 21.4 | 2.09 | 13.23 | 1.42 | 16.74 | 59.74 | 0.6739 | 0.5427 | 0.6012 | 0.5890 | 0.3931 |
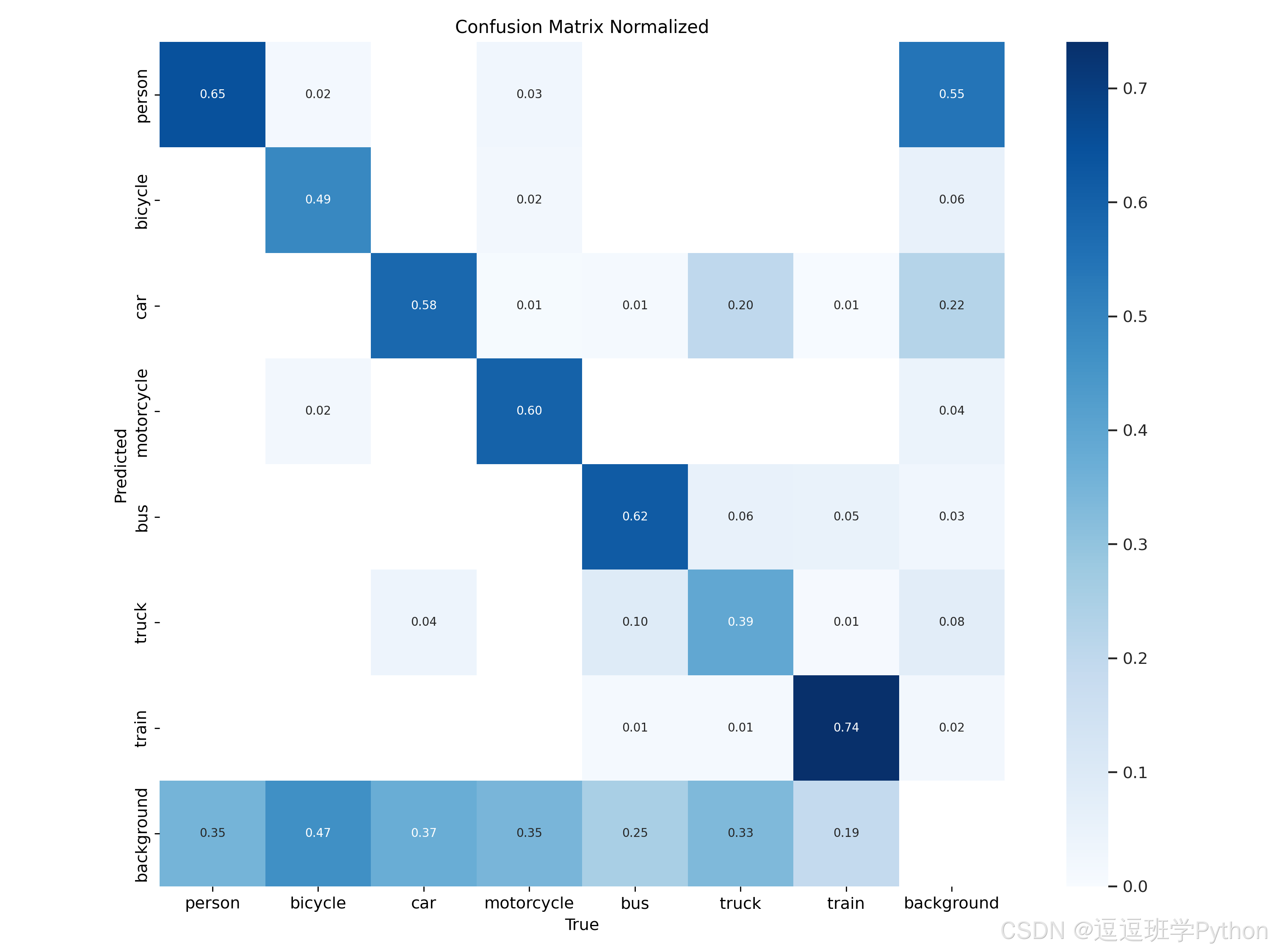
从混淆矩阵看,train、bus 对角占比最高(0.74/0.52),而 truck、bicycle 的对角值偏低(0.39/0.49),并在底行表现为较高的“预测为背景”比例(尤其 bicycle=0.47、truck=0.33),说明小目标与外观接近类在光照/遮挡场景下更易漏检;同时 car→bus(0.20) 的跨类混淆显著,主要受长条形车体、运动模糊与远距尺度影响。
F1-Confidence 曲线在 0.36 左右取得总体峰值(F1≈0.60),据此平台默认将置信度阈值初始化为 0.36,并在 Web 端暴露细调滑杆以适配不同场景。平均 PR 曲线显示 s 型相对 n 型有稳定的精度增益,且 YOLOv9 家族曲线整体外包于 YOLOv8,与其改进的骨干与训练策略一致;但 YOLOv10 在相近精度下维持更低的后处理延迟,更适合多路并发的在线计数。

下图给出 八模型的 F1 与 mAP@0.5 双条形图。配色采用清新学术蓝/橙,y 轴对齐以便观察“精度与召回折中”随模型的结构性差异:
图1 n 型模型 F1 与 mAP@0.5 双条形图

图2 s 型模型 F1 与 mAP@0.5 双条形图

结合曲线与表格可得以下结论:其一,n 型模型中 YOLOv9t/YOLOv11n/YOLOv10n 的 F1、mAP 排名靠前,但 YOLOv9t 的延迟显著高于 YOLOv6n/YOLOv8n;若以 30 FPS 的流式计数为目标,YOLOv8n 在 6.83 ms 推理与 mAP@0.5=0.551 之间取得较优平衡。其二,s 型模型整体在精度上普遍优于 n 型,其中 YOLOv7 精度最高,但若要求单卡多路并发,推荐 YOLOv8s/YOLOv11s 或 YOLOv10s(后处理更轻),以控制端到端时延与 CPU 占用。其三,混淆矩阵暴露的 bicycle/truck 长尾与远距小目标问题是主要误差来源;通过提升输入分辨率、在增强中增加小目标的 Copy-Paste 与夜景/运动模糊扰动,并对这两个类别提高采样权重,可显著改善召回而不过度牺牲精度。其四,F1-Confidence 曲线建议将默认置信度设为 0.36,并在夜间或强遮挡条件下降低至 0.30–0.34 以提升计数召回,同时将 IoU 阈值调至 0.55±0.05 以抑制拥挤场景的重叠框误抑制。

面向实际部署,若 Web 平台以“单路实时 + 精细计数”为目标,可选 YOLOv11n/YOLOv10n 并启用轨迹去抖与区域/过线计数以稳定统计;若为“多路并发 + 成本敏感”,选择 YOLOv8n/YOLOv6n,配合 TensorRT FP16 与批间复用;若为“离线高精度”,可采用 YOLOv7/YOLOv9s 并在较高分辨率(≥1280)下推理。误检主要表现为车灯与反射导致的 car↔bus 混淆,可在前端开启“类别合并计数(vehicle)”模式以减弱对业务统计的影响,同时保留原始细分类以便复核与审计。综上,在计数场景下的最佳折中通常是 YOLOv8n(在线)/YOLOv11s(准实时)/YOLOv7(离线) 的分层选择,并结合第6章的“同步双帧 + 参数热更新 + CSV/SQLite 溯源”形成稳定的端到端闭环。
6. 系统设计与实现
6.1 系统设计思路
系统采用分层架构以保证实时性、可扩展性与可治理性:表现与交互层由浏览器端 HTML/CSS/JS 负责,完成多源输入选择、参数调节与同步双帧(原图/检测图)渲染;业务与会话管理层由 Flask + Flask-SocketIO 提供 REST/WS 统一网关、登录会话与权限约束、速率限制与导出调度;推理与任务调度层负责解码/预处理、YOLO 推理与后处理(NMS 或一致性匹配)、区域/过线计数与轨迹维护,并通过任务队列实现多路视频的并发与背压;数据持久化层以 SQLite 记录任务、参数与统计,结合对象存储/缓存保存带框图片、导出视频与 CSV 明细,以支撑复现与审计。
端到端数据流为“多源输入(图片/视频/摄像头)→ 解码与尺度对齐 → YOLO(v5–v12)推理 → 后处理与类别筛选 → 过线/区域计数与统计聚合 → 前端可视化与交互闭环”。为满足低时延目标,系统将参数更新(Conf/IoU、类别开关、ROI/计数线)作为原子广播事件下发,并以帧时间戳与流水号维持双帧一致性;当并发压力升高时,调度层采用“关键帧优先 + 非关键帧跳跃 + 结果插值”的背压策略,保持交互连续与计数稳定。安全侧,会话采用短期令牌与口令哈希存储,关键导出与管理操作受最小权限约束并记录审计日志。
扩展性方面,平台支持权重热切换与模型注册表(上传权重即刻生效并同步刷新类别与阈值建议),推理层通过 ONNX/TensorRT 导出与 FP16/INT8 加速降低端到端时延;路径规范与数据库自动迁移保证跨平台兼容与持续可用。统计与导出集中管理,支持按文件名/任务时间高亮定位、批量下载与结果溯源;监控接口采集吞吐、延迟、GPU/内存占用与丢帧率,便于在多路摄像头长时间运行下进行容量规划与异常恢复。
图 6-1 系统流程图

图注:从浏览器端选择输入与参数开始,经交互网关进入预处理、推理与计数,统计结果回流至前端同步双帧渲染,同时写入持久化与导出。
图 6-2 系统设计框图

图注:按层划分模块边界与依赖方向;表现与交互层仅经业务层访问推理/数据层,模型权重通过注册表受控下发。
6.2 登录与账户管理

图注:用户在登录页选择登录/注册/一次性跳过三种入口;成功后建立浏览器会话并载入个性化配置与历史记录,进入主界面;会话内可修改资料或安全注销。
说明:登录流程以“最小权限 + 可追溯”为原则:注册时执行口令强度校验与哈希存储,登录成功后产生短期令牌并绑定浏览器会话;“跳过登录”仅在当前会话有效且限制导出与管理操作。进入主界面后,系统自动加载个性化主题、默认阈值、最近任务与常用导出路径;资料修改与权限变更均写入 SQLite 并记录审计,确保检测流程与数据溯源的连续性。
代码下载链接
如果您希望获取博客中提及的完整资源包,包含测试图片、视频、Python文件(*.py)、网页配置文件、训练数据集、代码及界面设计等,可访问博主在面包多平台的上传内容。相关的博客和视频资料提供了所有必要文件的下载链接,以便一键运行。完整资源的预览如下图所示:


资源包中涵盖了你需要的训练测试数据集、训练测试代码、UI界面代码等完整资源,完整项目文件的下载链接可在Gitee项目中找到➷➷➷
完整项目下载、论文word范文下载与安装文档:https://deeppython.feishu.cn/wiki/H8DowTJktiEdfFkGNxEc9KzHnLh
讲解视频地址:https://www.bilibili.com/video/BV14iDkBxEqz/
完整安装运行教程:
这个项目的运行需要用到Anaconda和Pycharm两个软件,下载到资源代码后,您可以按照以下链接提供的详细安装教程操作即可运行成功,如仍有运行问题可私信博主解决:
- Pycharm和Anaconda的安装教程:https://deepcode.blog.csdn.net/article/details/136639378;
软件安装好后需要为本项目新建Python环境、安装依赖库,并在Pycharm中设置环境,这几步采用下面的教程可选在线安装(pip install直接在线下载包):
- Python环境配置教程:https://deepcode.blog.csdn.net/article/details/136639396;
7. 结论与未来工作
本文基于 Flask+Flask-SocketIO 构建了行人/车辆检测与计数的 Web 平台,完成了从数据准备、模型训练到浏览器端“同步双帧”可视化与 CSV/带框导出、SQLite 入库的端到端闭环;在同一数据与算力下比较 YOLOv5–YOLOv12 多个规模的精度与时延,可见在轻量侧 YOLOv8n/YOLOv6n具备更高吞吐,YOLOv9t/YOLOv11n在精度与稳定性上更均衡,标准侧 YOLOv7/YOLOv9s 则提供更高上限,结合计数业务需求给出了阈值(Conf≈0.36)与 IoU 的实战默认配置与调优路径。平台的组件化设计(权重热切换、参数原子广播、过线/区域计数、结果溯源)在道路监控中实现了低时延统计与稳定复现;从工程可迁移的角度,同样的“检测—计数—导出—审计”范式与轻量部署策略(ONNX/TensorRT、FP16/INT8、层融合)可直接迁移到机械器件外观缺陷/部件计数等场景,通过调整类别体系与 ROI 定义即可复用前后端与数据治理管线。
未来工作将沿三条主线推进:其一是模型侧,继续探索更轻量的骨干与注意力组件、蒸馏与跨架构蒸馏以稳住小目标召回,引入更强的时序一致性(匈牙利匹配的时序约束、NMS-free 一致性训练)、混合精度与量化感知训练,并尝试多模态融合(视觉+雷达/深度)以提升夜间与雨雾鲁棒;其二是系统侧,完成容器化与自动化部署(Docker/Compose→K8s)、引入分布式任务队列与推理池弹性伸缩(如基于队列的多路视频调度)、采用 WebRTC/WHIP 实时低时延推流替换传统轮询、完善角色权限与审计链路、i18n 与多租户空间、边缘—云协同与GPU配额管理,并加入在线健康检查与异常恢复;其三是数据侧,建立主动学习闭环(高不确定样本与疑难计数片段自动回流)、半自动标注与弱监督扩容、合成数据与域自适应以缓解昼夜/天气漂移,配套数据治理与漂移监测仪表盘。博主预计在这些方向落地后,平台将进一步降低单路时延与多路抖动,显著提升拥挤/遮挡场景的计数稳健性,并以更可复用的工程形态服务于交通与制造等多行业的在线视觉分析。
参考文献(GB/T 7714)
[1] de Moraes A, et al. Pedestrian and Vehicle Detection in Autonomous Vehicle Systems: A Review[J]. Sensors, 2021, 21(13): 1-24.
[2] Hsiao A, et al. Deep learning for autonomous vehicle and pedestrian interaction safety[J]. Safety Science, 2021, 133: 105021.
[3] Ultralytics. YOLOv8 Docs: Usage and Deployment[EB/OL]. 2024-2025.
[4] Gevorgyan Z. SIoU Loss: More Powerful Learning for Bounding Box Regression[EB/OL]. arXiv:2205.12740, 2022.
[5] Ge Z, Liu S, Wang F, et al. YOLOX: Exceeding YOLO Series in 2021[EB/OL]. arXiv:2107.08430, 2021.
[6] Xu S, Wang X, Lv W, et al. PP-YOLOE: An evolved version of YOLO[EB/OL]. arXiv:2203.16250, 2022.
[7] Ren S, He K, Girshick R, et al. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks[C]//NIPS, 2015: 91-99.
[8] Wang C-Y, Bochkovskiy A, Liao H-Y M. YOLOv7: Trainable bag-of-freebies and bag-of-specials for real-time object detection[EB/OL]. arXiv:2207.02696, 2022.
[9] Jocher G, et al. Ultralytics YOLOv8: SOTA real-time detection[EB/OL]. 2023-2025.
[10] Wang A, Chen H, Liu L, et al. YOLOv10: Real-Time End-to-End Object Detection[EB/OL]. arXiv:2405.14458, 2024.
[11] Li C, Li L, Jiang H, et al. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications[EB/OL]. arXiv:2209.02976, 2022.
[12] Ultralytics. YOLO11/YOLO12 release notes and applications[EB/OL]. 2024-2025.
[13] Deng Y, et al. RT-DETR: DETRs Beat YOLOs on Real-time Object Detection[EB/OL]. arXiv:2304.08069, 2023.
[14] NVIDIA. TensorRT Developer Guide: Quantization and INT8 Best Practices[EB/OL]. 2023-2025.
[15] 蒋嘉璇, 陆丽丽, 王呈璋, 等. 基于改进YOLOv8模型的行人及车辆检测方法[J]. 航天制造技术, 2024, (10): 95-101.
[16] Zhang Y, Sun P, Jiang Y, et al. ByteTrack: Multi-Object Tracking by Associating Every Detection Box[EB/OL]. arXiv:2110.06864, 2021.
[17] Zhou X, Wang D, Krähenbühl P. Objects as Points (CenterNet)[EB/OL]. arXiv:1904.07850, 2019.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号