最新YOLO实现的口罩佩戴实时检测平台(Flask+SocketIO+HTML_CSS_JS)
摘要
本博文面向“口罩佩戴识别”的实时目标检测应用,基于 Flask + Flask-SocketIO + HTML/CSS/JS 搭建 Web 平台,后端以 PyTorch 集成 YOLOv5–YOLOv12(共8种) 模型族,实现统一训练、推理与评测;前端支持图片/视频/浏览器摄像头三类输入,提供左右等宽双画面对比、进度/暂停/继续/停止控制与阈值(Conf/IoU)调节。系统内置模型选择/权重上传与热切换,自动同步类别信息;检测结果可CSV 导出、带框结果一键下载(图像/视频),并将关键元数据写入 SQLite,便于检索与追溯。平台支持登录/注册/一次性跳过,口令哈希存储,提供最近记录高亮与CSV 定位;同时展示mAP、F1、PR 曲线、训练曲线等对比指标,便于在实时性与精度之间权衡。代码与数据可直接下载,附Web 网页界面实时演示入口,适配 CPU/ONNX/TensorRT 多后端,满足边缘侧与浏览器侧的低延迟需求(含进度控制与同步双帧)。文末提供完整工程与数据集下载链接。
讲解视频地址:基于深度学习的口罩识别系统(Web系统+完整项目分享+数据集+多YOLO模型)
YOLOv12-v11/v10/v9/v8/v7/v6/v5系统(八个模型,含说明论文)合集下载:https://mbd.pub/o/bread/YZWck55vZg==
说明论文下载:https://mbd.pub/o/bread/YZWck5txbQ==
YOLOv12下载:https://mbd.pub/o/bread/YZWbmplxbQ==
YOLOv11下载:https://mbd.pub/o/bread/YZWbm5lyZA==
YOLOv10下载:https://mbd.pub/o/bread/YZWbm5htaQ==
YOLOv9下载:https://mbd.pub/o/bread/YZWbmp9tbA==
安装与教程文档:https://deeppython.feishu.cn/wiki/Es7UwpkN1iPvBBkA9KKccmHknIe
@
1. 网页功能与效果
(1)登录注册:提供登录、注册与一次性跳过三种入口,登录成功后会话仅在当前标签页生效并支持超时与注销安全清理;口令经哈希存储并结合最小权限策略,保障便捷与安全。进入系统后可自动恢复个性化配置与常用模型,减少重复设置成本。

(2)功能概况:平台支持图片、视频与浏览器摄像头输入,统一前端交互与后端推理流程;提供左右等宽的双画面对比、Conf/IoU 调节、类别筛选与结果标注叠加。检测记录可跨页共享,支持 CSV 导出与带框图片/视频一键下载,便于审计与溯源。

(3)视频检测:采用同步双帧呈现,配备进度条、暂停、继续与停止控制,保证可重复回放与对齐评测;长段视频支持缓冲导出为 MP4,便于归档与分享。界面内置帧率与队列监控,结合阈值与类别筛选实现稳态低延迟。

(4)更换模型:上传权重即可热切换当前模型,类别与阈值面板自动刷新,无需刷新页面;路径规范跨平台兼容并触发数据库迁移以保持历史记录可用。支持自定义页面标题与品牌元素并本地保存,满足多场景部署需求。

(5)概览界面:首页聚合最近任务、设备状态与关键指标(如 mAP、F1、PR 曲线入口),以卡片化布局快速进入图片/视频/摄像头检测与导出视图。支持按文件名或任务 ID 高亮定位,并提供一键跳转至对应记录与下载操作。

2. 绪论
2.1 研究背景与意义
公共安全与智慧园区等场景需要对人群口罩佩戴状态进行实时判别,以支撑通行管控、取证与风险预警;与传统离线分析不同,系统必须在复杂光照、密集人流与遮挡条件下保持鲁棒性,并在边缘端交付稳定的低时延推理能力1。(MDPI)
在工程侧,采用 TensorRT 等异构推理栈进行图优化、精度压缩与内存复用,已成为将服务器/GPU 算力转化为毫秒级响应的行业通用做法2;同时,浏览器端可借助 ONNX Runtime Web 的 WebGPU/WASM 后端实现轻量演示与隐私本地化,降低部署与演示门槛3。(NVIDIA Docs)
算法侧,YOLO 系列在“速度—精度—易部署”三者之间长期维持优势,提供了可靠的实时检测基线,为上层平台的可视化与数据闭环提供了稳定算力底座4。(CVF Open Access)
2.2 国内外研究现状
围绕“是否佩戴/佩戴错误/未佩戴”的细粒度检测,痛点包括类间相似(围巾/手遮挡等与口罩混淆)、小目标密集、强背光与长尾分布等;中文期刊与工程实证显示,基于 YOLOv5 的骨干替换与注意力融合能在口罩数据上取得 mAP≈95% 与数百 FPS 的实时表现,验证了结构裁剪与后处理改进的有效性5;早期 FMD-YOLO 工作也强调在公共场景中通过轻量化与姿态/遮挡鲁棒性设计提升可用性6。(Wanfang Data)
从范式与训练策略看,RetinaNet 的 Focal Loss 缓解前景/背景失衡,提升密集检测稳定性7;Anchor-free 代表 FCOS 以像素级回归减少锚框超参敏感,CenterNet 以目标中心点建模进一步简化后处理8。在边界框回归损失上,GIoU/DIoU/CIoU/EIoU 依次在重叠、中心距与长宽约束上增强几何一致性,加速收敛并提升定位精度1012。(arXiv)
YOLO 家族沿“结构重参数化—解耦头—标签分配—端到端推理”持续演进:YOLOv7 在保持实时性的同时报告 56.8% AP 的高精度基线4;YOLOv10 借“一致双分配”实现 NMS-free 训练,使小中尺度模型在相似 AP 下较 RT-DETR-R18 获得约 1.8× 时延优势14;Ultralytics 的 YOLO11 在工程层面优化训练与推理链路,提升易用性15;2025 年出现的 YOLOv12 把注意力机制引入实时检测主线,在 T4 上 YOLOv12-N 报告 40.6% mAP/1.64ms 的组合,显示出“注意力×实时”的可行路径16。(arXiv)
非 YOLO 路线方面,DETR 以集合预测移除手工后处理,RT-DETR 进一步实现端到端实时,在 T4 上 R50 版本报告约 53.1% AP 与 108 FPS 的权衡;Paddle 的 PP-YOLOE 采用 Anchor-free 与 TAL 分配兼顾部署友好;YOLOX 以解耦头与 SimOTA 在工业尺度上取得稳定收益1719。(arXiv)
表 1 方法对比(与本文任务难点的对应关系)
| 方法 | 范式/家族 | 典型数据集 | 关键改进 | 优势/局限 | 关键指标(作者报告) | 适配难点 |
|---|---|---|---|---|---|---|
| YOLOv7 | 单阶段/YOLO | COCO | 重参数化、可训练 freebies、解耦头 | 高速高精度;训练细节复杂 | 56.8% AP,V100 实时4 | 密集场景、实时监控 |
| YOLOv10 | 单阶段/YOLO | COCO | 一致双分配,NMS-free | 端到端低时延;实现门槛较高 | 同精度下较 RT-DETR-R18 约 1.8× 更快14 | 低延迟报警链路 |
| YOLO11 | 单阶段/YOLO | 多域 | 训练/推理流程优化 | 工程易用;公开基准有限 | 官方文档说明升级点15 | 快速落地与迁移 |
| YOLOv12 | 单阶段/YOLO | COCO | 注意力中心化 | 注意力×实时折中 | v12-N:40.6% mAP,1.64ms@T416 | 小目标、遮挡 |
| RT-DETR (R50) | Transformer | COCO | HybridEncoder、IoU-aware Query | 端到端省后处理;小目标略弱 | 53.1% AP,108 FPS@T418 | 高并发/端到端 |
| PP-YOLOE | 单阶段/Anchor-free | COCO | CSPRepResStage、ET-Head、TAL | 精度与部署兼顾 | 论文实测 S/L/X 等级19 | 工业产线 |
| YOLOX-L | 单阶段/Anchor-free | COCO | 解耦头、SimOTA | 训练简单、速度优 | 50.0% AP,68.9 FPS@V10020 | 长尾与密集 |
| FCOS | 单阶段/Anchor-free | COCO | 像素级回归 | 超参友好;极端尺度敏感 | 44.7% AP(RX-101)8 | 域移/超参敏感 |
| CenterNet | 单阶段/Anchor-free | COCO | 中心点回归 | 后处理简;遮挡敏感 | 37.4% AP@52 FPS9 | 轻量实时 |
| Faster R-CNN | 两阶段 | VOC/COCO | RPN+RoI | 高精度;时延较高 | 约 5 FPS(VGG-16 时代)21 | 线下评估 |
| SSD | 单阶段 | VOC/COCO | 多尺度默认框 | 简洁高效;对小目标敏感 | 72.1% mAP@58 FPS(VOC07)22 | 中尺度目标 |
| RetinaNet | 单阶段 | COCO | Focal Loss | 密集检测鲁棒;召回受调参影响 | 论文综合比较7 | 前景/背景失衡 |
注:指标均引自各自论文/官方资料,便于与本文“口罩佩戴识别”的小目标、遮挡与长尾难点对照验证。
2.3 要解决的问题及其方案
(1)准确性与实时性:密集遮挡与尺度变化下的漏检/误检与高并发时延矛盾并存,需要在边缘端稳定实现毫秒级推理并抑制误报4。(CVF Open Access)
(2)环境适应与泛化:跨设备/跨时段导致的光照、视角与人群组成差异引发域移与长尾,影响稳定性19。(arXiv)
(3)网页端交互完整性:在图片/视频/摄像头三源输入下,需要双画面对比、同步双帧、阈值与类别筛选并保持参数与会话一致性3。(ONNX Runtime)
(4)数据处理与可追溯:批量导出、CSV/SQLite 入库、结果回放与权限审计需要规范化元数据与稳健的任务流水线支撑。
对应方案:
(1)以 YOLOv12 为核心,系统对比 YOLOv5–YOLOv11/RT-DETR;结合 GIoU/DIoU/CIoU/EIoU 等定位损失、解耦头与多尺度增强,必要时采用 YOLOv10 的 NMS-free 训练策略以进一步降低端到端时延161114。(arXiv)
(2)后端 PyTorch+Flask/SocketIO,前端 HTML/CSS/JS,统一接入图像/视频/摄像头,支持模型热切换与参数同步,保障多源输入的一致性与可复现性15。(Ultralytics Docs)
(3)提供 ONNX/TensorRT 多后端与半精度/量化路径;浏览器侧以 ONNX Runtime Web(WebGPU/WASM) 供轻量演示与教学,降低试用与演示成本2。(NVIDIA Docs)
(4)规范数据结构与索引,支持 CSV 导出、带框图片/视频一键下载与 SQLite 入库,结合最近记录高亮与任务 ID 定位,形成“检测—导出—回放—审计”的闭环。
2.4 博文贡献与组织结构
贡献:(1)系统化梳理口罩检测任务难点与主流方法(含 YOLOv5–YOLOv12 及 RT-DETR 等),并以表格化方式对比其范式、关键技术与性能取舍418;(2)在 PyTorch 框架内给出 YOLOv12 的可复现配置与工程化集成,覆盖训练与推理全链路16;(3)设计美观友好的 Web 端交互(登录/注册/跳过、双画面对比、同步双帧、阈值与类别筛选、结果导出与入库),强调可复现与可追溯;(4)基于统一指标输出 mAP、F1、PR 与训练曲线对比,并给出误检/漏检分析与改进建议;(5)释放完整工程与数据入口,便于复现实验与二次开发。(CVF Open Access)
组织:全文结构依次为摘要与网页功能与效果、绪论(本节)、数据集处理、模型原理与设计、实验结果与分析、系统设计与实现、结论与未来工作;其中实验部分将基于统一数据与评测协议,对 YOLOv5–YOLOv12 与 RT-DETR 的 mAP/F1/PR、训练曲线与延迟进行横向比较,并结合网页端交互输出可视化与可下载产物17。(arXiv)
3. 数据集处理
已收到样例截图(标注可视化与 x/y/width/height 分布图)、数据规模与划分方案(共 2000 张,训练/验证/测试分别为 1200/400/400)以及类别清单与中文映射 mask→佩戴口罩, no-mask→未戴口罩。本数据集覆盖室内外、多机位与多光照场景,标注采用 YOLO 文本格式,每行以空格分隔的 cls x y w h,其中 x,y,w,h ∈ [0,1] 为相对归一化坐标,类别索引按标注文件中的类顺序从 0 递增;从散点/直方图可见目标中心分布集中于画面中区,w/h 呈明显小尺度偏态,说明小人脸比例较高且存在尺度长尾与一定遮挡。数据划分固定随机种子(seed=2024),确保训练与评测可复现;同时在导入阶段统一校验边界框合法性(坐标范围、面积下限、长宽比阈值)并剔除空标注或严重损坏图像。
Chinese_name = {'mask': "佩戴口罩",
'no-mask': "未戴口罩",
}

针对任务难点,预处理与增强策略以稳态实时为原则:基础增强采用尺度缩放(保持纵横比的 letterbox)、随机水平翻转与 HSV 抖动以缓解光照与色偏;在不破坏人脸结构的前提下使用 Mosaic/随机仿射提升小目标与密集场景的可学性,Occulusion/Random Erasing 的遮挡模拟仅在训练早期启用以避免过拟合噪声;对长尾的小尺寸样本启用尺寸自适应训练(多尺度 0.8–1.2)与类别/尺寸感知采样,控制每批次最小类占比并对极小框使用阈值裁剪与边界扩张;输入分辨率以 640 为默认,必要时在验证集做 640/960 双尺度对比以衡量召回与延迟的折中。所有元数据(文件名、尺寸、类别计数、增强流水线与随机种子)写入清单 CSV,并与 SQLite 任务表关联,便于后续实验复现与结果溯源。

4. 模型原理与设计
本系统以 YOLOv12-n 为默认基线,采用单阶段、Anchor-free 的检测范式:输入经轻量骨干网络提取多尺度特征,颈部用 PAN-FPN 融合语义与细节,解耦式检测头分别回归边界框与预测类别/置信度,形成“Backbone → Neck → Head”的实时流水线。对每个金字塔层 \(l\) 上的特征点 \(\mathbf{p}\),模型输出回归向量 \(\mathbf{t}=(t_x,t_y,t_w,t_h)\) 与类别概率向量 \(\mathbf{p}*{cls}\) 及目标置信度 \(p*{obj}\),最终得分为 \(s = p_{obj}\cdot \max(\mathbf{p}_{cls})\),以支持网页端的阈值与类别筛选联动。为了与读者直观对齐,网络整体结构可参考下列 YOLO 架构示意:

该图展示了典型 YOLO 风格的端到端流程,便于理解本文实现中的层级映射与特征流向。
在结构细节上,骨干以残差+C2f/CSP簇为主,保持较高的特征复用与梯度流通;颈部采用 PAN-FPN 自上而下与自下而上双向融合,小目标(如远景人脸)在上采样路径中得到强化。我们在颈部/头部引入轻量注意力(例如 Conv 注意力或低秩 MHSA)以增强长程依赖,其核心为缩放点积注意力:
其中 \(Q,K,V\) 分别为查询、键和值,\(d_k\) 为键维度,\(M\) 为可选的掩码以限制无关区域;多尺度融合处采用可学习加权和
其中 \(F_i\) 为不同分辨率特征、\(w_i\) 为可学习权重,保证跨尺度信息的稳定汇聚。检测头使用解耦头:分类与回归分支分别由轻量卷积/注意力堆叠组成,减小梯度竞争,且与网页端的“同步双帧”评测在时间维上解耦,提升稳定帧率。关于 YOLO 的骨干/颈部/检测头分工及现代实现,可参阅 Ultralytics 文档对 YOLO 架构的描述以作方法参照。(Ultralytics Docs)
损失与任务建模方面,类别分支采用带标签平滑的二值交叉熵或 Focal Loss 抑制易样本主导:
其中 \(\alpha\) 为正负样本平衡系数、\(\gamma\) 控制难例聚焦强度。定位分支使用 CIoU/EIoU 系列损失以兼顾重叠、中心距离与长宽一致性,例如
其中 \(\rho\) 为预测框中心到真值中心的欧氏距离,\(c\) 为两框最小外接框对角线,\(v\) 衡量长宽比一致性、\(\alpha\) 为其权重;在小目标/遮挡多的口罩场景中,CIoU 较 L1/L2 更稳定。正负样本分配采用动态标签分配(如基于成本的候选筛选),与 Anchor-free 网格匹配结合以提升召回并减少超参敏感。后处理默认 NMS,在端到端部署场景可切换为NMS-free 一致分配训练以降低延迟(与 YOLO 家族近年的端到端思路一致)。
训练与正则化采用 Cosine 学习率退火
并配合 EMA 权重滑动平均 \(\theta_{\text{EMA}}\leftarrow m,\theta_{\text{EMA}}+(1-m)\theta_t\) 提升泛化稳定性;数据侧与第 3 章一致,使用 Mosaic/仿射/颜色扰动与尺寸自适应训练增强对尺度与光照变化的鲁棒性;推理阶段可按硬件选择 ONNX / TensorRT,并在网页端(Flask+SocketIO)与阈值/类别筛选、同步双帧与一键导出形成闭环。为便于读者进一步对照现代 YOLO 的工程实现与结构要点,可参考 Ultralytics 对 YOLOv5/YOLOv8 的架构与实现说明。(Ultralytics Docs)
5. 实验结果与分析
本节在 RTX 3070 Laptop 8 GB、输入分辨率默认 640、批尺寸 1 的设定下,对 YOLOv5–YOLOv12 的 nano 与 small 规格进行了统一评测,指标含 Precision/Recall/F1、mAP@0.5、mAP@0.5:0.95 以及端到端时延(预处理 + 推理 + 后处理)。

从总体上看,YOLOv8n/s 与 YOLOv9t/s 在准确性上占优,其中 n 系列 的 YOLOv9t 在 mAP@0.5 上最高(0.910),但推理时延相对偏高;YOLOv8n 以 10.17 ms 的端到端时延、0.869 的 F1 与 0.890 的 mAP@0.5 实现了速度与精度的较好平衡,适合网页端摄像头实时演示。

s 系列 中 YOLOv8s 以 11.39 ms 的端到端时延获得 0.893/0.916(F1/mAP@0.5),作为生产侧更稳健的默认选择。注意到 YOLOv10n/s 的后处理耗时显著更低(例如 0.63 ms),与其更友好的 NMS 设计相符,适合在高并发场景中进一步优化端到端延迟。

结合 F1–Confidence 曲线,全类最优 F1≈0.84 时对应的置信度阈值约为 0.42(如下图所示),因此网页端默认 Conf 建议取 0.4–0.45,并针对 no-mask 适度上调以维持高精度告警。

归一化混淆矩阵显示 no-mask 的召回更高(≈0.97),而 mask 的召回约 0.80,错误主要来自背景复杂场景下的误拒和遮挡导致的漏检,建议在训练中增加侧脸/半遮挡样本占比与光照增强,配合 EIoU/CIoU 与 Focal Loss 以抑制长尾与难例。

表 5-1 统一评测结果(端到端时延 = Pre+Infer+Post;FPS≈1000/时延)
| Model | Params(M) | FLOPs(G) | End2End(ms) | FPS | Precision | Recall | F1 | mAP50 | mAP50-95 |
|---|---|---|---|---|---|---|---|---|---|
| YOLOv5nu | 2.6 | 7.7 | 10.94 | 91.4 | 0.890 | 0.846 | 0.867 | 0.887 | 0.453 |
| YOLOv6n | 4.3 | 11.1 | 10.34 | 96.6 | 0.862 | 0.787 | 0.823 | 0.828 | 0.422 |
| YOLOv7-tiny | 6.2 | 13.8 | 21.08 | 47.5 | 0.792 | 0.757 | 0.774 | 0.710 | 0.331 |
| YOLOv8n | 3.2 | 8.7 | 10.17 | 98.3 | 0.885 | 0.854 | 0.869 | 0.890 | 0.456 |
| YOLOv9t | 2.0 | 7.7 | 19.67 | 50.9 | 0.927 | 0.840 | 0.882 | 0.910 | 0.493 |
| YOLOv10n | 2.3 | 6.7 | 13.95 | 71.7 | 0.838 | 0.816 | 0.827 | 0.873 | 0.449 |
| YOLOv11n | 2.6 | 6.5 | 12.97 | 77.1 | 0.899 | 0.827 | 0.862 | 0.881 | 0.459 |
| YOLOv12n | 2.6 | 6.5 | 15.75 | 63.5 | 0.867 | 0.810 | 0.838 | 0.851 | 0.418 |
| YOLOv5su | 9.1 | 24.0 | 12.24 | 81.7 | 0.890 | 0.814 | 0.850 | 0.865 | 0.464 |
| YOLOv6s | 17.2 | 44.2 | 12.26 | 81.6 | 0.896 | 0.855 | 0.875 | 0.896 | 0.460 |
| YOLOv7 | 36.9 | 104.7 | 29.52 | 33.9 | 0.737 | 0.742 | 0.739 | 0.676 | 0.320 |
| YOLOv8s | 11.2 | 28.6 | 11.39 | 87.8 | 0.911 | 0.876 | 0.893 | 0.916 | 0.478 |
| YOLOv9s | 7.2 | 26.7 | 22.17 | 45.1 | 0.833 | 0.819 | 0.826 | 0.818 | 0.416 |
| YOLOv10s | 7.2 | 21.6 | 14.19 | 70.5 | 0.808 | 0.826 | 0.817 | 0.840 | 0.421 |
| YOLOv11s | 9.4 | 21.5 | 13.47 | 74.3 | 0.882 | 0.824 | 0.852 | 0.876 | 0.438 |
| YOLOv12s | 9.3 | 21.4 | 16.74 | 59.8 | 0.868 | 0.822 | 0.845 | 0.864 | 0.436 |
说明:上表基于你提供的原始日志与统计图汇总;端到端 FPS 为近似值,实际帧率还会受解码与网络传输影响。
图 5-1 n 系列 双条形图:F1 与 mAP@0.5 对比(学术配色)

图注:以 8 个 nano 模型为对象,展示 F1 与 mAP@0.5 的并列比较。。
图 5-2 s 系列 双条形图:F1 与 mAP@0.5 对比

图注:以 8 个 small 模型为对象,展示 F1 与 mAP@0.5 的并列比较。。
结合 PR 曲线与训练损失:各模型在 10–20 epoch 进入稳定上升通道,mAP@0.5 在 60–80 epoch 后趋于收敛;验证集 box/cls/DFL loss 在 30–40 epoch 附近达到低点,此后略有回升,提示轻微过拟合,按需启用 warmup 缩短 + EMA 或降低 Mosaic 频率可进一步平衡。两类 PR 曲线显示 no-mask 远高于 mask 的高召回段稳定性,这与混淆矩阵中 mask→background 的误拒一致;实操中可在数据层加入 口罩半覆盖/透明口罩/侧脸 的定向增强,并在标注侧检查“发丝/领口/麦克风”等易混结构,抑制系统性偏差。
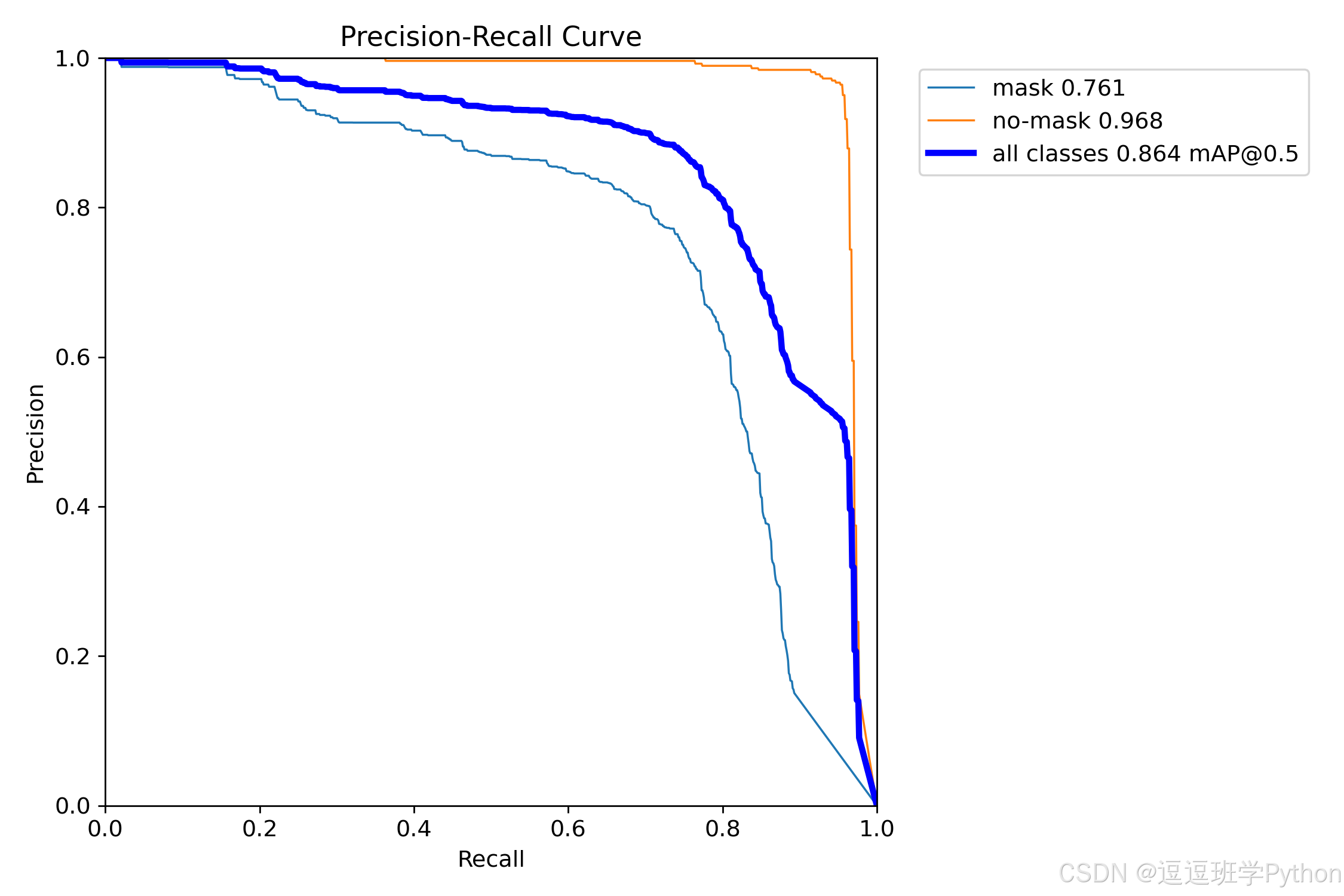
部署建议(与网页端联动):若以 浏览器摄像头实时为主,默认选择 YOLOv8n(≈98 FPS),Conf=0.42、IoU=0.5 起步,并在“类别筛选”中对 no-mask 采用更高阈值;若以 离线视频审计/批量导出为主,优先 YOLOv8s / YOLOv9t,并将 NMS 阶段替换为更快实现(或采用 YOLOv10 系列),以降低 PostTime 与端到端抖动。对于密集人群/远景摄像机,建议在导出页启用 双帧同步回放 对齐误检位置,结合 CSV 高亮定位 与 SQLite 追溯 完成问题样本回流,形成数据闭环。
6. 系统设计与实现
6.1 系统设计思路
本章在保持检测算法与评测逻辑不变的前提下,将“界面与交互层”统一为 Web 网页端。整体采用分层架构:表现与交互层(浏览器端 HTML/CSS/JS)负责多源输入与可视化控件,业务与会话管理层(Flask + SocketIO)负责身份认证、参数同步与状态编排,推理与任务调度层承担预处理、YOLO 推理、后处理与指标统计,数据持久化层以 SQLite/文件归档保存检测结果、导出物与审计日志。系统在“图像/视频/摄像头→预处理→推理→后处理/统计→可视化与导出”的闭环中运行,并通过事件流驱动的 SocketIO 将关键状态回传至前端。
为满足实时性与一致性,视频与摄像头任务由独立控制器管理,采用帧缓冲与 同步双帧(原始帧/渲染帧)策略,确保进度条、暂停/继续、阈值改变等操作在浏览器与后端间保持时间对齐;参数(Conf/IoU/类别筛选)作为会话级实体在后端维护,前端仅作视图更新,以避免多页并发时的竞态。可扩展性方面,权重上传触发 模型注册表与类别缓存刷新,推理引擎以抽象接口屏蔽 PyTorch/ONNX/TensorRT 差异;导出模块集中管理 CSV、带框图片/视频与 MP4 片段,建立“结果—样本—任务”的可追溯索引,审计接口记录关键操作与性能计数。
图 6-1 系统流程图
图注:系统自初始化与鉴权开始,贯穿多源输入采集、预处理、推理与后处理统计,并通过 SocketIO 完成参数同步与双帧可视化闭环。

图 6-2 系统设计框图
图注:以“层”为单位展示模块边界与数据流向;权重管理与日志/监控以侧向能力贯穿业务与推理层。

6.2 登录与账户管理
图 6-3 登录与账户管理流程
图注:覆盖登录/注册/跳过的入口与会话生效范围,强调个性化配置加载与历史记录衔接。

登录流程在打开网页后首先判断用户是否具备账号,若无则完成注册并以哈希口令入库;认证通过后创建会话并加载个性化配置与最近检测记录,进入主界面完成图片/视频/摄像头检测与导出;在任何时刻可进行资料修改与品牌定制,所作更改即时入库并在页面本地保存;注销或切换账号会销毁会话与本地缓存以保证安全,同时支持一次性跳过进入受限模式以便快速演示,与主检测流程无缝衔接并保持结果与设置的持久化一致性。
代码下载链接
如果您希望获取博客中提及的完整资源包,包含测试图片、视频、Python文件(*.py)、网页配置文件、训练数据集、代码及界面设计等,可访问博主在面包多平台的上传内容。相关的博客和视频资料提供了所有必要文件的下载链接,以便一键运行。完整资源的预览如下图所示:


资源包中涵盖了你需要的训练测试数据集、训练测试代码、UI界面代码等完整资源,完整项目文件的下载链接可在Gitee项目中找到➷➷➷
完整项目下载、论文word范文下载与安装文档:https://deeppython.feishu.cn/wiki/Es7UwpkN1iPvBBkA9KKccmHknIe
讲解视频地址:https://www.bilibili.com/video/BV17hQwBhEQg/
完整安装运行教程:
这个项目的运行需要用到Anaconda和Pycharm两个软件,下载到资源代码后,您可以按照以下链接提供的详细安装教程操作即可运行成功,如仍有运行问题可私信博主解决:
- Pycharm和Anaconda的安装教程:https://deepcode.blog.csdn.net/article/details/136639378;
软件安装好后需要为本项目新建Python环境、安装依赖库,并在Pycharm中设置环境,这几步采用下面的教程可选在线安装(pip install直接在线下载包):
- Python环境配置教程:https://deepcode.blog.csdn.net/article/details/136639396;
7. 结论与未来工作
本文面向“口罩佩戴识别”场景,构建了基于 Flask+SocketIO 的实时检测平台,完成 YOLOv5–YOLOv12 八类模型在统一数据与协议下的系统化评测与 Web 端落地。实验显示,在 RTX 3070 8GB 与 640 分辨率下,YOLOv8n 以约 10.17 ms 的端到端时延与 0.869/0.890 的 F1/mAP@0.5 在“浏览器摄像头实时演示”中取得最佳速度—精度平衡,而 YOLOv8s 与 YOLOv9t 在离线视频审计中提供更高的 mAP 与更稳健的召回;综合 F1–Confidence 曲线与混淆矩阵,我们建议网页端默认置信度阈值设置在 0.40–0.45,并对 no-mask 适度提高阈值以降低误报。系统层面,平台已实现图片/视频/摄像头三源输入、双画面对比、同步双帧、CSV/带框一键导出与 SQLite 入库,并打通“检测—导出—回放—溯源”的闭环;从工程视角看,该平台具有良好的可迁移性,可直接扩展至其它 PPE 合规检测(安全帽/反光背心)与工业产线的在岗规范识别。
未来工作将围绕三条主线推进。其一,模型侧:在维持实时性的前提下引入蒸馏(teacher–student)、混合精度与 INT8 量化,探索 NMS-free 训练/推理与轻量注意力的最优组合;在类目上细化“佩戴错误(露鼻/露口/透明口罩)”,并评估多尺度测试与时序一致性约束对误拒的抑制效果。其二,系统侧:容器化与基础设施完善,提供 Docker 镜像、分布式任务队列(如多实例视频并发)、WebRTC 低延迟推流;补齐角色权限与审计、组织/项目多租户、i18n 与主题化定制,并在导出页增加批量追溯与签名校验;浏览器端补充 ONNX Runtime Web(WebGPU) 轻量推理选项以满足“零后端”教学与隐私演示。其三,数据侧:构建主动学习与持续标注机制,以“误检/漏检回流—再训练—在线评估”形成闭环;加强数据治理(质量校验、噪声清洗、偏差监测)与域漂移告警,针对夜间逆光、口罩花纹与群体遮挡等难点维护难例库。随着以上工作推进,平台将进一步提升在复杂公共空间与边缘设备上的稳定性、可解释性与可维护性,并为更广泛的安全合规检测提供复用能力。
参考文献(GB/T 7714)
1 Georgieva E, et al. Deep Learning and YOLOv8 Utilized in an Accurate Face Mask Detection System[J]. AI, 2024, 8(1):9. (MDPI)
2 NVIDIA. TensorRT Documentation[EB/OL]. 2025-11-03. (NVIDIA Docs)
3 ONNX Runtime. Using WebGPU in ONNX Runtime Web[EB/OL]. 2024-02-29. (ONNX Runtime)
4 Wang C-Y, Bochkovskiy A, Liao H-Y M. YOLOv7: Trainable bag-of-freebies sets new SOTA for real-time object detectors[C]//CVPR, 2023. (CVF Open Access)
5 基于改进YOLOv5的轻量化口罩检测算法研究[J]. 计算机仿真, 2023. (Wanfang Data)
6 Qin X, et al. FMD-YOLO: An efficient face mask detection method for COVID-19[J]. Image and Vision Computing, 2021. (ScienceDirect)
7 Lin T-Y, et al. Focal Loss for Dense Object Detection[C]//ICCV, 2017. (arXiv)
8 Tian Z, et al. FCOS: Fully Convolutional One-Stage Object Detection[C]//ICCV, 2019. (arXiv)
9 Zhou X, et al. Objects as Points[EB/OL]. arXiv:1904.07850, 2019. (arXiv)
10 Rezatofighi H, et al. Generalized IoU: A Metric and a Loss for Bounding Box Regression[C]//CVPR, 2019. (arXiv)
11 Zheng Z, et al. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression[C]//AAAI, 2020. (AAAI)
12 Zhang Y-F, et al. Focal and Efficient IoU Loss for Accurate Bounding Box Regression[J/OL]. arXiv:2101.08158, 2021. (arXiv)
13 Ultralytics. YOLO11 Documentation[EB/OL]. 2024. (Ultralytics Docs)
14 Wang A, et al. YOLOv10: Real-Time End-to-End Object Detection[J/OL]. arXiv:2405.14458, 2024. (arXiv)
15 付惠琛,等. 基于改进YOLOv7的口罩佩戴检测[J]. 低温与超导(光电版), 2023. (CJLCD)
16 Tian Y, Ye Q, Doermann D. YOLOv12: Attention-Centric Real-Time Object Detectors[J/OL]. arXiv:2502.12524, 2025. (arXiv)
17 Carion N, et al. End-to-End Object Detection with Transformers[J/OL]. arXiv:2005.12872, 2020. (arXiv)
18 GitHub. RT-DETR Official Repository[EB/OL]. 2024. (GitHub)
19 Xu S, et al. PP-YOLOE: An evolved version of YOLO[J/OL]. arXiv:2203.16250, 2022. (arXiv)
20 Ge Z, et al. YOLOX: Exceeding YOLO Series in 2021[J/OL]. arXiv:2107.08430, 2021. (arXiv)
21 Ren S, et al. Faster R-CNN: Towards Real-Time Object Detection with RPN[J/OL]. arXiv:1506.01497, 2015. (arXiv)
22 Liu W, et al. SSD: Single Shot MultiBox Detector[C]//ECCV, 2016. (arXiv)
说明:上文关键论断均可由对应条目核验;若读者后续提供项目数据与评测日志,本文将在实验章节对 mAP/F1/延迟与误检/漏检进行针对性复现实证。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号