
Tensorpack.MultiProcessPrefetchData改进,实现高效的数据流水线
参考代码:https://github.com/tensorpack/tensorpack/blob/master/tensorpack/dataflow/parallel.py(目前最新版本已经更名为MultiProcessRunner,在最早的版本叫做MultiProcessPrefetchData)
Tensorpack的数据流水线有多个,其中一个比较好实现的是MultiProcessRunner这个类,思路很简单,利用multiprocess.Queue队列,启动若干进程向队列push元素,然后在__iter__方法中从队列中拿元素.这个MultiProcessRunner处理方式,也在cifar10_resnet中被使用:https://github.com/tensorpack/tensorpack/blob/master/examples/ResNet/cifar10-resnet.py。但是假若图片的尺寸变大(cifar10尺寸是32*32,一个batch取128,图像总的数据量为:128*32*32*3*4bytes=1.5M,imagenet数据大小为224,batch取32的话,数据量为:32*224*224*3*4bytes=18.375M)受限于python多进程队列的实现方式(pipeline),取数据会变得非常慢,从0.02ms变为大概20几ms(通常数据越大网络运行一次的时间越大,相比之下获取数据的时间就基本上可以忽略不计).Tensorpack中imagenet的例子使用的MultiProcessRunnerZMQ,使用ZMQ替换Queue实现跨进程传输.
其实只需要在MultiProcessRunner的基础上稍加改进,就能实现同样0.2ms的数据流水线功能,参考代码:https://github.com/WeiTang114/FMQ,即fast MultiProcess.Queue,原理也很简单:利用python的Queue模块,这个队列不同于multiprocess.Queue,属于本地队列,不用跨进程传输。因此即使是取很大的数据,时间也很短.所以可以再开一个队列和线程,不断的从进程队列中拿元素然后再放入本地队列中,__iter__中直接从本地队列拿元素.
这里有两个问题:
1.处理数据的进程和线程都是死循环,如果不做处理,那么主进程退出后会发现程序没有正常退出。进程的退出可以使用atexit.register,参考:https://github.com/tensorpack/tensorpack/blob/master/tensorpack/utils/concurrency.py中的ensure_proc_terminate函数,线程的退出参考:https://www.jianshu.com/p/7b6a80faf33f方案一
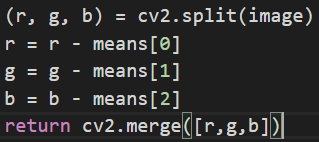
2.经过实测,发现在image augment时,如果处理速度过慢,也会影响主进程取数据的速度,比如flower5数据集在图像像素减去均值的时候,如果用np处理,就比较慢,参考:https://stackoverflow.com/questions/57684412/why-np-subtracta-100-and-np-subtracta-100-100-100-has-different-performan(貌似没人答复),但是针对这个问题找到了一个解决方法,就是先分离通道split,单个通道做减法,然后再merge,速度会稍微快一些.这里还有一点要注意,cv2.imread读取彩色图像的通道顺序是bgr.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号