ubuntu14.04上实现faster rcnn_TF的demo程序及训练过程
安装环境:Ubuntu14.04、显卡Tesla K40C+GeForce GT 705、tensorflow1.0.0、pycharm5.0
说明:原文见博客园,有问题原文下留言,不定期回复。本文作者疆,转载请备注。
本文可解决的问题:
1.tensorflow1.0.0环境搭建
2.Ubuntu14.04安装pycharm5.0
3.Ubuntu14.04上跑通faster rcnn_TF的demo程序
4.Ubuntu14.04上跑通faster rcnn_TF的训练过程
安装步骤如下:
一、tensorflow1.0.0环境搭建
1.安装Ubuntu14.04及显卡驱动、配置Cuda、cudnn环境请参照前一篇blog,网址为:http://www.cnblogs.com/deeplearning1314/p/8444352.html
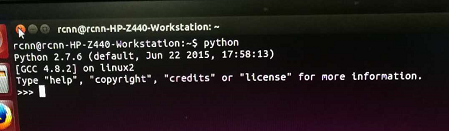
2.首先确认ubuntu系统自带python的版本号,因为python2与python3安装tensorflow略有差异。命令行中敲入 python 显示自带python的版本为2.7.6。
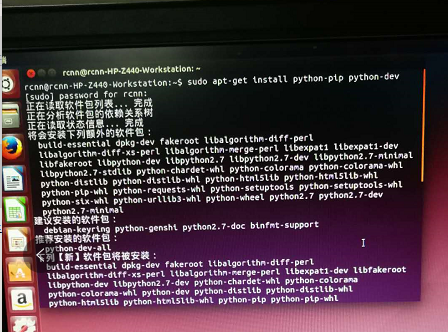
3.安装pip 命令行敲入sudo apt-get install python-pip python-dev
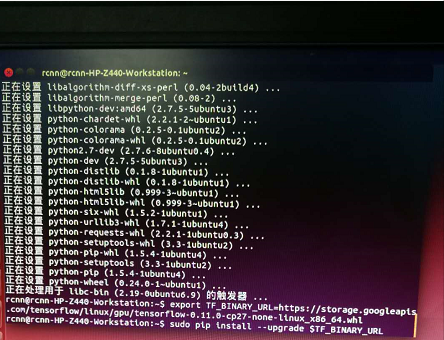
4.本来尝试网上方法(如下图)直接命令行联网下载tensorflow。试了很久没成功,提示网络连接错误,需要FQ、走代理下载。


5.不会走代理下载,于是想了一个办法:直接在自己的笔记本上下载好tensorflow的whl文件(一篇blog提到faster rcnn_TF要求tensorflow版本在1.0.0以上)再拷贝到本机上用pip方式安装。于是用自己笔记本在https://pypi.python.org下载后拷贝到工作站 /home“用户名”(即主文件夹)目录内。
如图所示,进入该目录下,准备以pip方式直接安装下载好的.Whl文件。在该网址上下载到名为tensorflow_gpu-1.0.0-cp27-cp27mu-manylinux1_x86_64.whl。
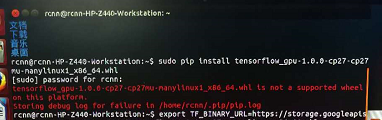
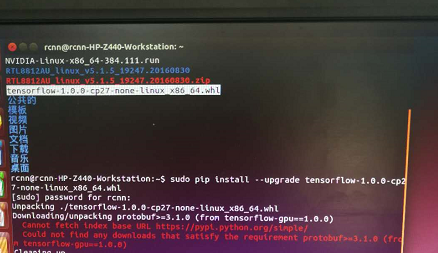
pip安装出现如下错误于是我猜想可能是文件名有问题就把文件名改为标准格式:tensorflow-1.0.0-cp27-none-linux_x86_64.whl
修改后pip安装仍然报了与protobuf相关的错,于是重敲命令重试了一遍(必要时可重启机器),虽然报了几个警告,但提示安装tensorflow成功。

6.为了验证tensorflow安装是否成功,需要跑tensorflow的例子(如下图为某本书的例子)

命令行内敲入Python 然后敲入import tensorflow as tf报错如下:

我在网上查到了解决办法,说与tensorflow环境变量有关。需要在每次import tensorflow as tf导入tensorflow之前敲两句export语句(如下图),这样一来就很麻烦了,因为每一次import tensorflow时都要敲两个export语句。这个问题可通过在Ubuntu系统通过添加环境变量解决这个问题,即将这两句export添加到~/.bashrc和~/.bash_profile文件中,这样便不用在每次导入tensorflow时敲export语句。(命令行用gedit工具打开这两个文件都添加这两个export语句)
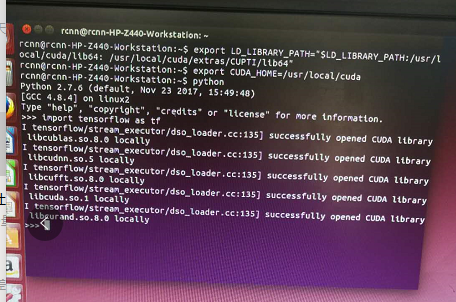
这时便可以测试tensorflow的例子
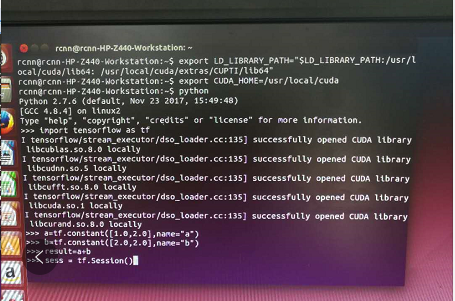
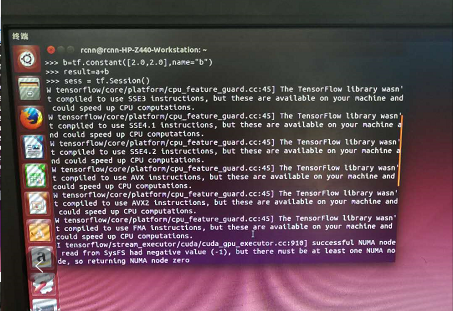
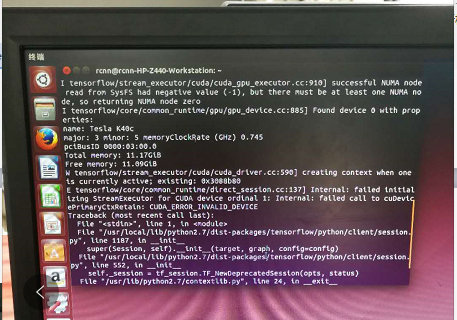
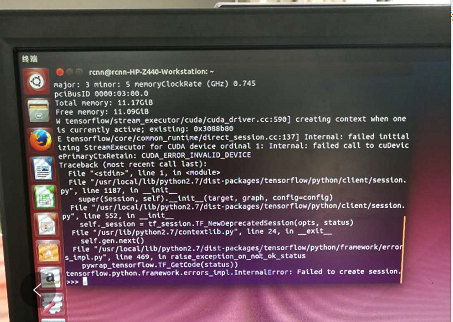

第一次报错创建会话(tensorflow执行运算需要先创建会话)失败,不关闭窗口再敲一遍(sess=tf.Session())创建会话,上述例子就能得到计算结果。当时我对这个问题不太了解,不知道为什么第二次才能创建会话执行成功。后来想可能是因为tensorflow默认是用gpu执行的但是并未添加CUDA_VISIBLE_DEVICES=0从而使第一次执行时是以cpu执行的。到这里,tensorflow环境就搭建好了。
二、Ubuntu14.04安装pycharm5.0
1.用自己笔记本在pycharm官网下载好pycharm5.0的tar.gz文件后拷贝至工作站/home”用户名”(即主文件夹)目录下。
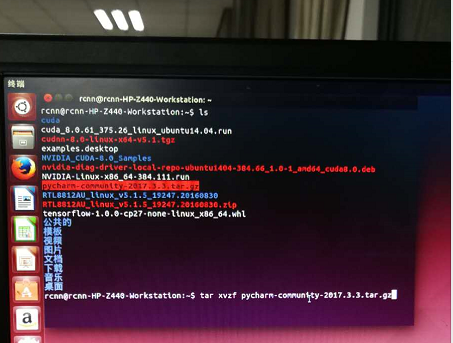
2.解压安装pycharm: tar xvzf pycharm-community-2017.3.3.tar.gz
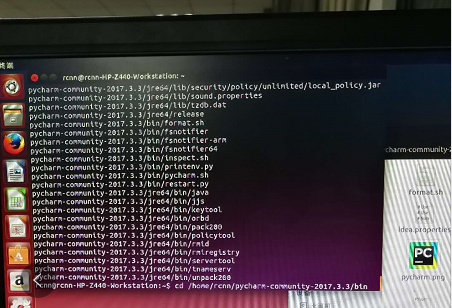
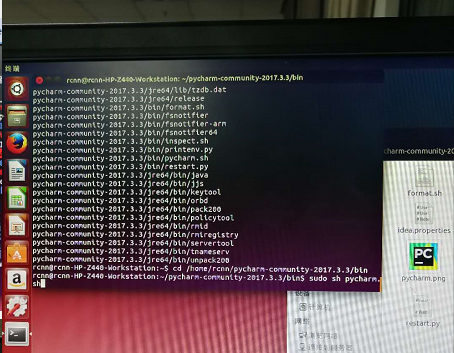
3.命令行方式打开pycharm,首先cd到pycharm的bin目录下(如上图),sudo sh pycharm.sh打开pycharm(如下图)。第一次打开需要对pycharm进行配置。
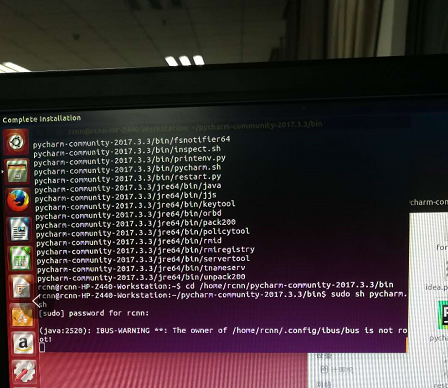
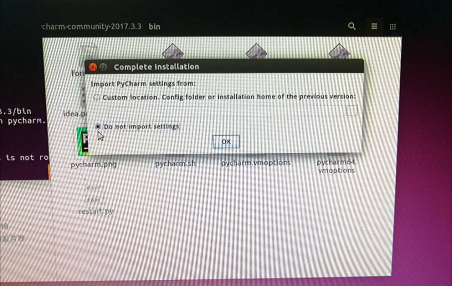
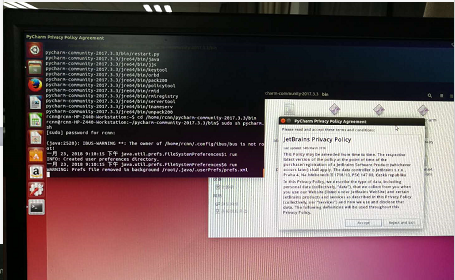
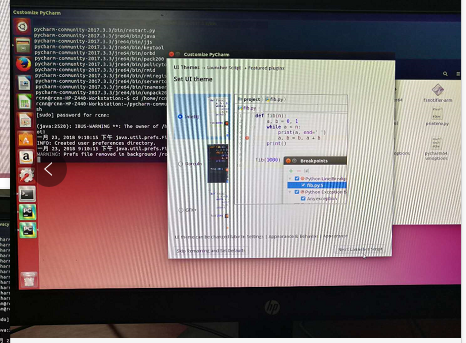
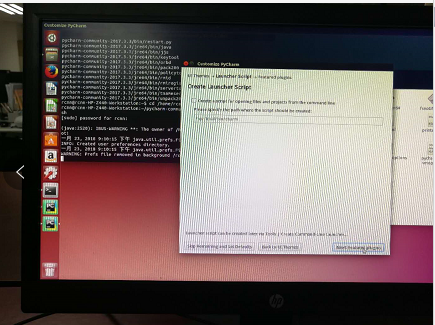
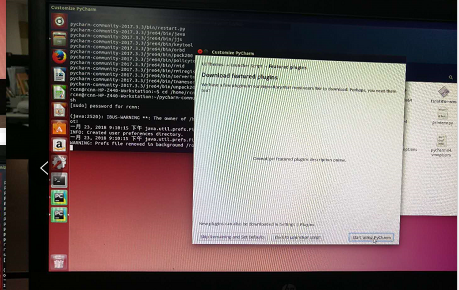
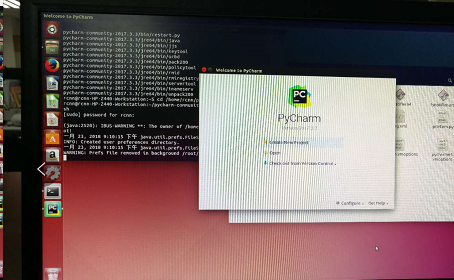
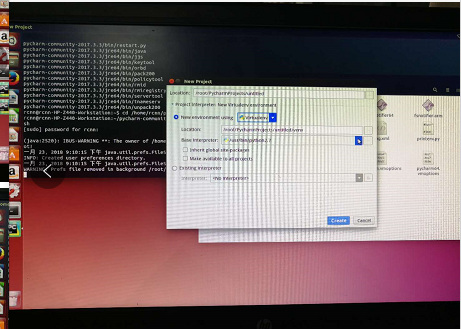
三、Ubuntu14.04上跑通faster rcnn_TF的demo程序
主要参考:
(1)博客http://blog.csdn.net/seven_year_promise/article/details/78589656,基本上是按照这篇blog装成功的,安装过程会有一些较小的差异。
(2)faster rcnn_TF官网中README文件: https://github.com/CharlesShang/TFFRCNN

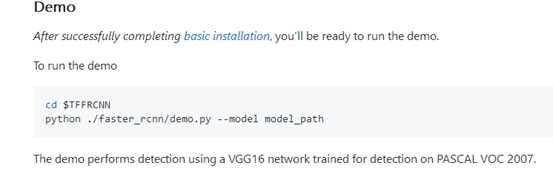
具体步骤以下面为准:
1.安装Python库
首先命令行敲入 sudo apt-get update
然后依次安装各个库,敲入
sudo apt-get install cython python-opencv python-tk python-scipy python-yaml
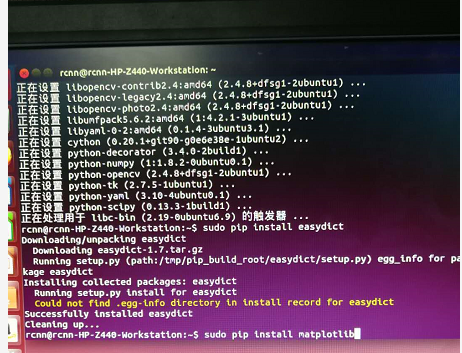
sudo pip install easydict
sudo pip install matplotlib(这里按照上述blog安装失败,错误信息如下图)
sudo python -m pip install Pillow
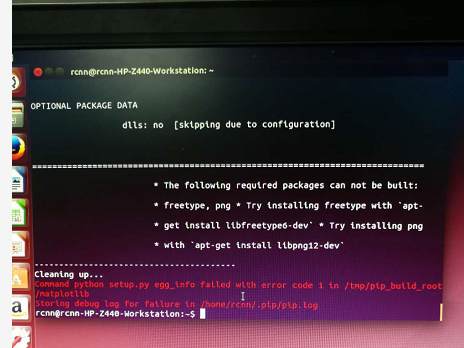
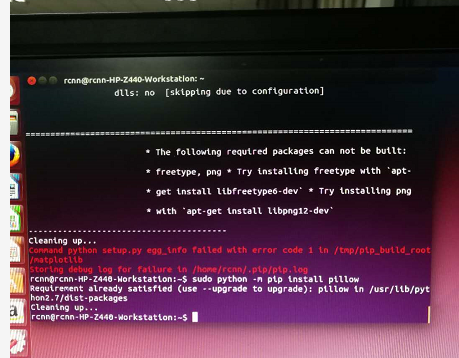
上面提到matplotlib库未安装成功,网上搜了很久无果,于是自己试了命令sudo apt-get install python-matplotlib安装成功。
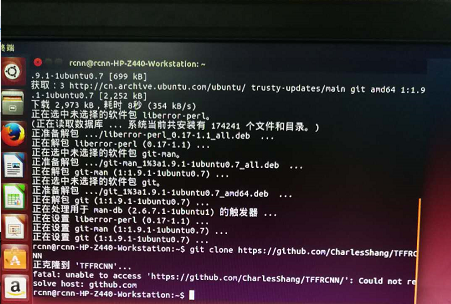
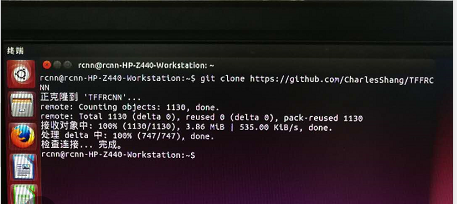
2.代码下载(网址:https://github.com/CharlesShang/TFFRCNN)直接在命令行内敲入 git clone https://github.com/CharlesShang/TFFRCNN提示未安装git,按照提示安装git后依然报错,于是重启机器重新git clone安装成功。安装成功后在本机主文件夹(即/home “用户名”)下可看到TFFRCNN文件夹。

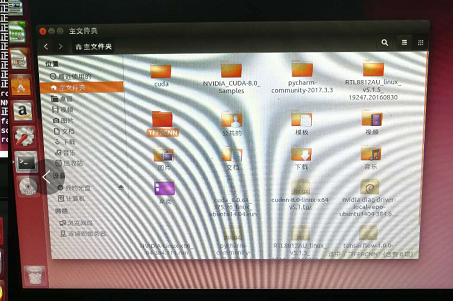
3.在TFFRCNN根目录下新建文件夹 model,放入下载好的训练文件(.ckpt文件),这个文件也需要走代理下载(试了很多种方法如wget、google浏览器FQ都没下载到)。于是让在国外的表哥帮忙下了,由于本人百度云上传文件次数受限,这里给不了个人百度云下载链接。
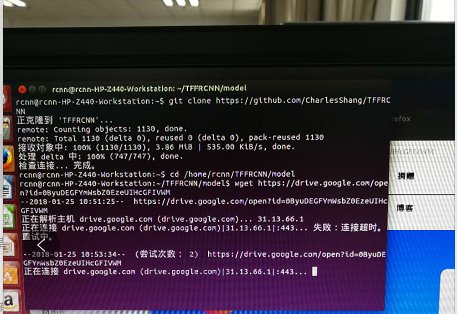
4.打开 lib文件夹下的 make.sh,根据英文注释提示和本机gcc编译器版本来修改,同时注意修改与显卡计算能力有关的参数。 本人机器gcc版本为4.8.4
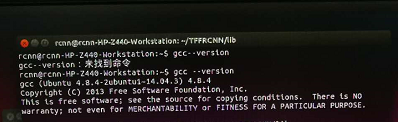
由于本人用于深度学习的显卡(Tesla K40C)计算能力为3.5,make.sh中两处改为-arch=sm_35。同时根据gcc版本取消注释(uncomment)相关行。
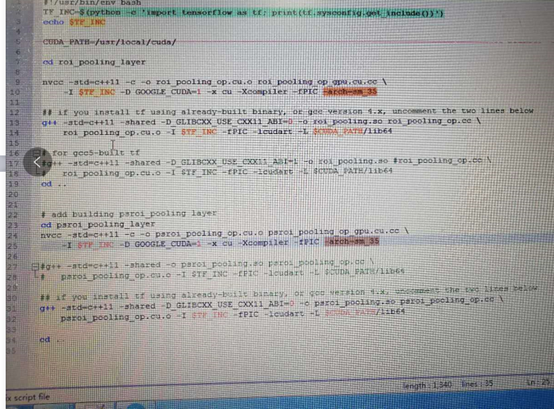
5.执行make
命令行敲入cd ./lib
再敲入 export PATH=$PATH:/usr/local/cuda-8.0/bin
最后敲入make
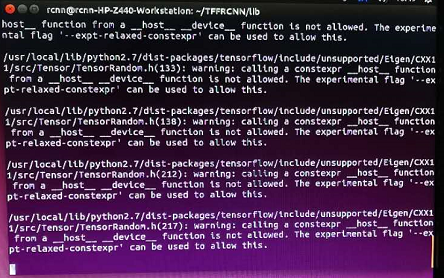

6.运行demo
将 faster rcnn文件夹下的 demo.py 拷贝到TFFRCNN根目录下,修改demo(如图颜色标记)

第一处添加该句和导入模块语句import os,第二处直接改成绝对路径。执行如下命令:
cd ..
python demo.py --model “your model path”
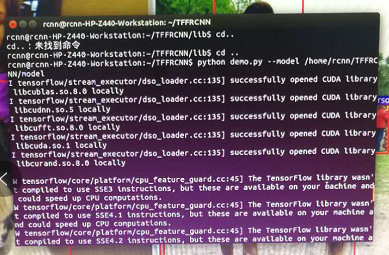

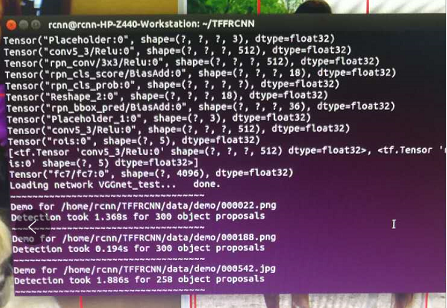
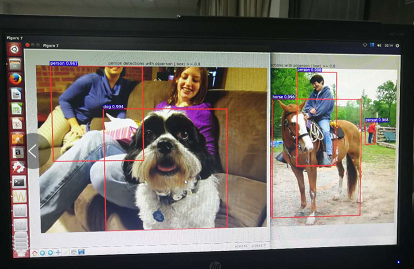
若想在pycharm中跑demo,需对pycharm做如下配置:
(1) 打开demo程序,在pycharm5.0中file---setting---project interprete选择当前程序及基础解释器均为Python2.7
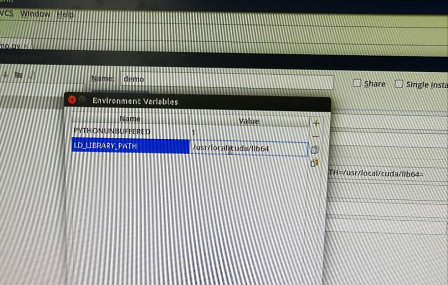
(2) 在pycharm5.0中run---edit configurations---environment variables添加环境变量LD_LIBRARY_PATH=/usr/local/cuda/lib64 (如下图)
(3) 在pycharm5.0中run---edit configurations---script parameters添加命令行参数
--model /home/rcnn/TFFRCNN/model
完成以上配置后即可直接在pycharm中run本程序。
四、Ubuntu14.04上跑通faster rcnn_TF的训练过程
主要参考:
1.https://blog.csdn.net/qq_39531954/article/details/78865452
2.http://www.cnblogs.com/danpe/p/7840087.html
3.faster rcnn_TF官网中README文件: https://github.com/CharlesShang/TFFRCNN

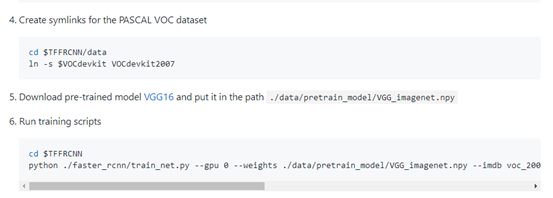
训练VOC数据步骤如下:(翻译讲解上述英文步骤1---5)
1.我没用上述wget方式直接联网下载,貌似行不通必须走代理。所以可用自己笔记本到给出网址下载3个文件,它们是VOC2007数据集(包括图片、标注信息等)及一些代码文件。
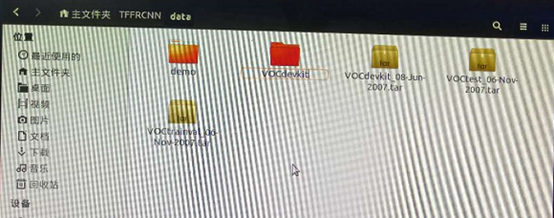
2.在TFFRCNN文件data文件夹内新建VOCdevkit文件夹,下载好上述3个.tar文件后拷贝到data文件夹内,用上述3句命令分别解压3个文件。
3.解压后得到如上述3的文件结构。
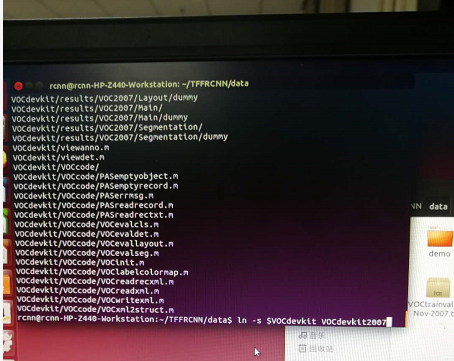
4.按上述4中命令建立软链接(如下图软链接图标,这里的意思就是访问VOCdevkit文件夹等同于访问VOCdevkit2007文件夹),其实也可以不做这步而把3中VOCdevkit文件夹改名为VOCdevkit2007。
5.在data文件夹下新建pretrain_model文件夹,根据所给网址下载VGG16预训练网络模型(.npy文件),该文件也需要走代理、FQ下载。
6.打开命令行,在命令内敲入sudo apt-get inatall python-skimage(该模块与COCO数据集有关,由于程序中有import COCO语句,缺少模块就会报错)

7.为使训练完成后能直接生成.ckpt等3个文件(其中.ckpt可供demo直接测试)需对train.py文件做如下修改,同时需要添加from tensorflow.core.protobuf import saver pb2。如果此处不改,会生成4个文件,这样在demo程序恢复模型变的较为复杂。

8.为方便调试,直接在pycharm下跑训练程序,需做如下设置:
(1)打开train_net.py程序,在pycharm5.0中file---setting---project interprete选择当前程序及基础解释器均为Python2.7
(2)在pycharm5.0中run---edit configurations---environment variables添加环境变量LD_LIBRARY_PATH=/usr/local/cuda/lib64
(3)在pycharm5.0中run---edit configurations---script parameters添加命令行参数
--gpu 0 --weights home/rcnn/TFFRCNN/data/pretrain_model/VGG_imagenet.npy --imdb voc_2007_trainval --iters 70000 --cfg home/rcnn/TFFRCNN/experiments/cfgs/faster_rcnn_end2end.yml --network VGGnet_train --set EXP_DIR exp_dir --restore 0
友情提示:千万不要少了--restore 0
(4)在train_net.py程序中添加代码:
import os
os.environ["CUDA_VISIBLE_DEVICES"]="0"
完成以上配置后即可直接在pycharm中run本程序。
本想在最后借个百度账号上传本工程及上述需走代理下载的文件,但是借来的账号仍然提示上传次数超过500次,估计百度网盘抽风了,前几篇blog里的链接都失效了。如有需要请在文末评论联系本人。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号