正则表达式复习
平时工作中,不管是输入验证,还是字符查找,关键信息替提取,数据替换都会看到正则的影子,下面做个小结,方便后续复习
1 单个字符
1.1 元字符
"\d": 匹配数字,
例如要匹配一个固定格式的电话号码以0开头前4位后7位,如0737-5686123 正则:^0\d\d\d-\d\d\d\d\d\d\d$ 这里只是为了介绍"\d"字符,实际上有更好的写法会在 下面介绍。
"\w":匹配字母,数字,下划线.
例如我要匹配"a2345BCD__TTz" 正则:"\w+" 这里的"+"字符为一个量词指重复的次数,稍后会详细介绍。
"\s":匹配空格
例如字符 "a b c" 正则:"\w\s\w\s\w" 一个字符后跟一个空格,如有字符间有多个空格直接把"\s" 写成 "\s+" 让空格重复
".":匹配除了换行符以外的任何字符
这个算是"\w"的加强版了"\w"不能匹配 空格 如果把字符串加上空格用"\w"就受限了,看下用 "."是如何匹配字符"a23 4 5 B C D__TTz" 正则:".+"
1.2反义字符
- "\W" 匹配任意不是字母,数字,下划线 的字符
- "\S" 匹配任意不是空白符的字符
- "\D" 匹配任意非数字的字符
- "\B" 匹配不是单词开头或结束的位置
- "[^abc]" 匹配除了abc以外的任意字符
1.3范围字符
- [abc]:查找方括号内任意一个字符。
- [^abc]:查找不在方括号内的字符。
- [0-9]:查找从 0 至 9 范围内的数字,即查找数字。
- [a-z]:查找从小写 a 到小写 z 范围内的字符,即查找小写字母。
- [A-Z]:查找从大写 A 到大写 Z 范围内的字符,即查找大写字母。
- [A-z]:查找从大写 A 到小写 z 范围内的字符,即所有大小写的字母。
- [\u0000-\u00ff]:如果匹配任意 ASCII 字符。
- [^\u0000-\u00ff]:双字节的汉字。
2.选择匹配
\w(.mp4|.avi|.wmv|.rmvb) 匹配这几种视频后缀
3.重复匹配
单个字符加上量词才能显示威力
| 量词 | 描述 |
|---|---|
| n+ | 匹配任何包含至少一个 n 的字符串 |
| n* | 匹配任何包含零个或多个 n 的字符串 |
| n? | 匹配任何包含零个或一个 n 的字符串 |
| n{x} | 匹配包含 x 个 n 的序列的字符串 |
| n{x,y} | 匹配包含最少 x 个、最多 y 个 n 的序列的字符串 |
| n{x,} | 匹配包含至少 x 个 n 的序列的字符串 |
4.惰性贪婪
重复类量词都具有贪婪性,在条件允许的前提下,会匹配尽可能多的字符。
- ?、{n} 和 {n,m} 重复类具有弱贪婪性,表现为贪婪的有限性。
- *、+ 和 {n,} 重复类具有强贪婪性,表现为贪婪的无限性。举列子
a*b 代表匹配aaaaaaa...aaaab 或者单独的b,也就是说a有多少匹配多少a,或者a不出现。
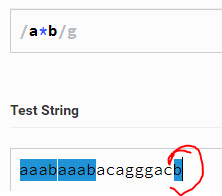
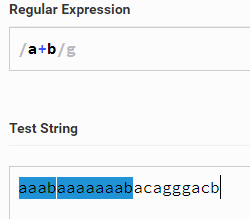
a+b 代表匹配axxxxxb ,axxxxb 中间有多少匹配多少。区别* 就是 a 一定会出现,而且是有多少匹配多少。
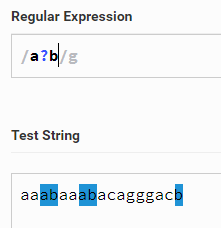
a?b 代表匹配 ab 或者单独的b.
5.边界量词
| 量词 | 说明 |
|---|---|
| ^ | 匹配开头,在多行检测中,会匹配一行的开头 |
| $ | 匹配结尾,在多行检测中,会匹配一行的结尾 |
6. 分组预判
先了解在正则中捕获分组的概念,其实就是一个括号内的内容 如 "(\d)\d" 而"(\d)" 这就是一个捕获分组,可以对捕获分组进行 后向引用 (如果后而有相同的内容则可以直接引用前面定义的捕获组,以简化表达式) 如(\d)\d\1 这里的"\1"就是对"(\d)"的后向引用
下面列出捕获分组常有的用法
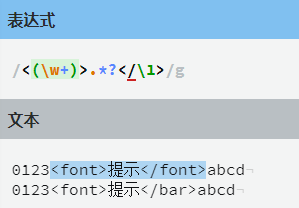
"(exp)" 匹配exp,并捕获文本到自动命名的组里
"(?<name>exp)" 匹配exp,并捕获文本到名称为name的组里
"(?:exp)" 匹配exp,不捕获匹配的文本,也不给此分组分配组号
以下为零宽断言,搞懂一个还是很好理解的。
"(?=exp)" 匹配exp前面的位置 取后面是什么ing 的字符。
如 "How are you doing" 正则"(?<txt>.+(?=ing))" 这里取ing前所有的字符,并定义了一个捕获分组名字为 "txt" 而"txt"这个组里的值为"How are you do";
"(?<=exp)" 匹配exp后面的位置 与"(?=exp)"空间上相反,前面是什么How 这里< 好像是方向,靠前面的意思
如 "How are you doing" 正则"(?<txt>(?<=How).+)" ,就是取前面的字符是How 后面的内容并定义了一个捕获分组名字为 "txt" 而"txt"这个组里的值为" are you doing";
"(?!exp)" 匹配后面跟的不是exp的位置 与"(?=exp)"逻辑上相反 后面不能是什么
如 "123abc" 正则 "\d{3}(?!\d)"匹配3位数字后非数字的结果
"(?<!exp)" 匹配前面不是exp的位置 与"(?=exp)"逻辑上相反,空间上相反
如 "abc123 " 正则 "(?<![0-9])123" 匹配"123"前面是非数字的结果也可写成"(?!<\d)123"
理论知识清楚了,但是遇到实际问题,还是要实践出真知
IP地址的长度为32位,分为4段,每段8位,用十进制数字表示,每段数字范围为0~255,段与段之间用英文句点“.”隔开。例如:某台计算机IP地址为10.11.44.100。
分析IP地址的组成特点:250-255、200-249、0-199。
这三种情况可以分开考虑,
1. 250-255:特点:三位数,百位是2,十位是5,个位是0~5,用正则表达式可以写成:25[0-5]
2. 200-249:特点:三位数,百位是2,十位是0~4,个位是0~9,用正则表达式可以写成:2[0-4]\d
3. 0-199:这个可以继续分拆,这样写起来更加简单明了.
3.1. 0-9: 特点:一位数,个位是0~9,用正则表达式可以写成:\d
3.2. 10-99: 特点:二位数,十位是1~9,个位是0~9,用正则表达式可以写成:[1-9]\d
3.3. 100-199:特点:三位数,百位是1,十位是0~9,个位是0~9,用正则表达式可以写成:1\d{2}
于是0-99的正则表达式可以合写为[1-9]?\d,那么0-199用正则表达式就可以写成(1\d{2})|([1-9]?\d),这样0~255的正则表达式就可以写成(25[0-5]|2[0-4]\d|((1\d{2})|([1-9]?\d)))
最后,前面3段加上句点.可以使用{3}重复得到,第4段再来一次同样的匹配,得到IP地址的正则表达式:
((25[0-5]|2[0-4]\d|((1\d{2})|([1-9]?\d)))\.){3}(25[0-5]|2[0-4]\d|((1\d{2})|([1-9]?\d)))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号