投机解码原理详解:小模型打草稿,大模型一次验证
生产环境中真正烧钱、拖慢体验的环节不是训练、是推理。自回归的方式一次只产出一个 token,每个 token 都要完整走一遍模型所有层的前向传播。70B 参数的模型在 H100 上运行,每个 token 对应 700 亿次乘累加运算,而 GPU 大部分时间都在等内存搬运数据,真正用于计算的比例很低。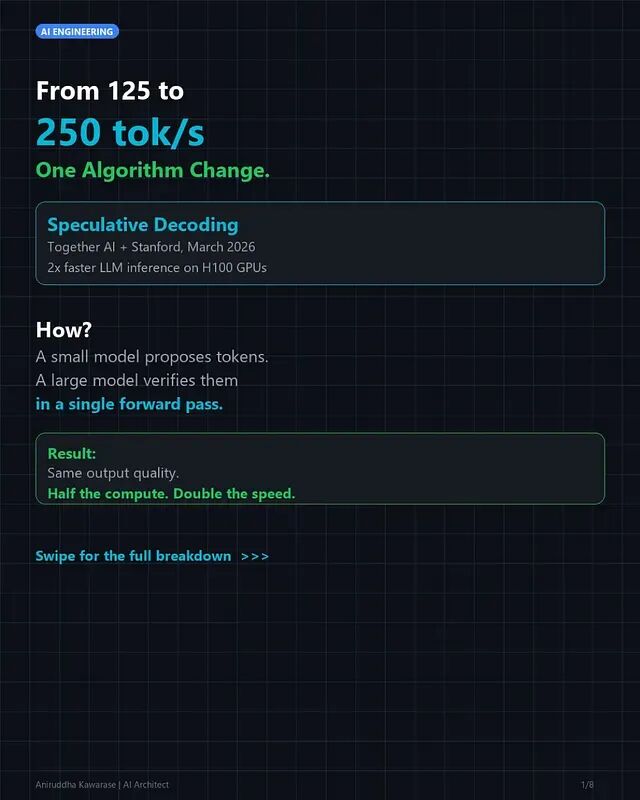
这就是内存带宽墙,H100 的算力高达 990 TFLOPS,但内存带宽只有 3.35 TB/s,自回归解码时后者才是瓶颈。
投机解码在2026 年变成了工程实践中的标配。
什么是投机解码?
投机解码的出发点很简单:用一个小而快的模型去猜测大模型接下来要输出什么,而大多数时候它能猜对。
核心算法分三步。
第一步:草稿生成。一个小型草稿模型(比如 Llama-3 8B)以自回归方式快速生成 K 个候选 token。小模型只占 GPU 显存的一小部分,单 token 生成速度比大模型快约 10 倍。
第二步:验证。大型模型(Llama-3 70B)在一次前向传播中处理全部 K 个草稿 token。验证是并行的,目标模型同时为每个位置计算下一个 token 的概率分布,一次前向传播完成 K 个 token 的校验,而自回归方式需要 K 次。
第三步:接受或拒绝。逐个比较草稿模型与目标模型给出的概率分布:一致则接受,不一致则拒绝并从目标模型在该位置的分布中重新采样,同时丢弃后续所有草稿 token。
https://avoid.overfit.cn/post/4804655307b24c7a9390ce6b45c38d51

 浙公网安备 33010602011771号
浙公网安备 33010602011771号