TPU 架构与 Pallas Kernel 编程入门:从内存层次结构到 FlashAttention
做过 GPU kernel 优化的人对以下编程模型肯定不会陌生:写一个 CUDA kernel分发到流式多处理器(SM)上执行,缓存层次结构自行负责数据搬运。而TPU 则完全不同,除非明确告诉编译器要把哪些数据块搬到哪里,否则kernel 根本无法编译。实际操作确实和听起来一样繁琐,所以JAX 的Pallas 就是解决的这个问题:以 tile 为单位描述计算,无需手动指定输入张量各部分的搬运路径,编译器自动生成所需的数据移动操作。
本文从硬件约束入手,接着逐步编写复杂度递增的 kernel,最后分析 JAX 生产级 FlashAttention 实现。我们先从基础开始,把那些绕不开的"为什么"讲清楚。
为什么不能在 TPU 上直接写循环?
GPU 上的基本原理很简单:写一个对单个元素或小块数据操作的 kernel,硬件调度成千上万份到各核心执行。线程通常处理同一张量中位置相邻的元素,大量线程同时读取内存中相邻的区域。GPU 的设计就是围绕这一模式展开的:自动合并相邻读取,将近期访问的数据保留在靠近计算单元的位置。内存访问符合这个模式时性能很好;不符合时,硬件通常也能平滑掉一部分开销。
__global__ void add(float* x, float* y, float* out, int n) {int i = blockIdx.x * blockDim.x + threadIdx.x;if (i < n) {out[i] = x[i] + y[i];}}// 幕后:数千个线程在 GPU 上同时运行这同一个 kernel。// thread 0 → out[0] = x[0] + y[0]// thread 1 → out[1] = x[1] + y[1]// thread 2 → out[2] = x[2] + y[2]
理解 Pallas 的价值,先要看清 TPU 和 GPU 在定位上的根本差异。TPU 不是通用并行处理器,它只做一件事,矩阵运算而且做得极好。它不会给游戏带来更高帧率,但一定可以加速模型训练。TPU v5e 芯片围绕一个称为 TensorCore 的计算模块构建,内含四个 MXU(Matrix Multiply Unit),可以理解为 128×128 的 systolic array乘法器排成网格,计算结果沿网格逐级传递给相邻单元。TPU 的内存层次结构不像 GPU 那样自动管理缓存,数据必须在三个层次之间显式搬运:
- HBM(高带宽内存):v5e 上约 16 GB,张量存放的位置,片外,速度相对较慢。
- VMEM(向量内存):16+ MB 的片上 SRAM,速度快但容量小;数据到达这里后计算单元才能访问。
- 寄存器:算术运算实际发生的位置,值从 VMEM 加载到寄存器、完成计算后写回 VMEM。
![]()
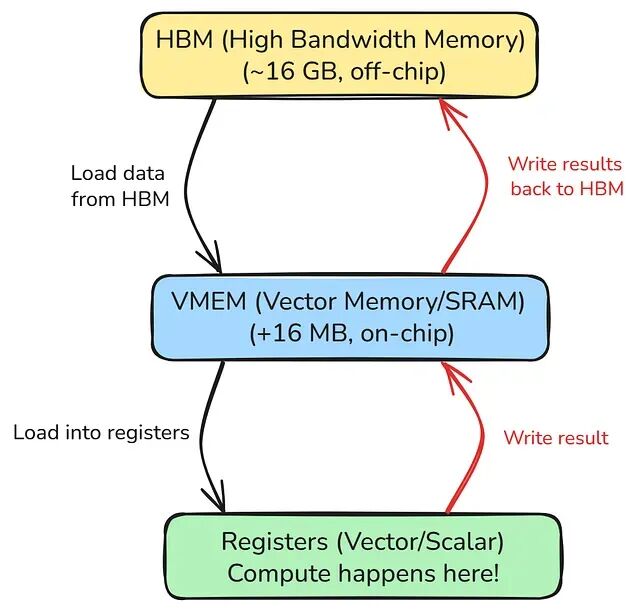
TPU 计算需要显式的数据暂存。
没法在 TPU 上像 CPU 或 GPU 那样对数据写一个简单循环,原因就在这里,数据不会自动从 HBM 流到寄存器。必须显式调度 DMA(直接内存访问)传输,将数据从 HBM 搬入 VMEM;kernel 执行完毕后 VMEM 中的结果再写回 HBM,这是 Pallas 存在的根本理由。GPU 上写
https://avoid.overfit.cn/post/12fe51915c5b439aacc1d33f3e4a2b12

 浙公网安备 33010602011771号
浙公网安备 33010602011771号