理解 Agent 记忆:从无状态模型到持久化记忆架构
大语言模型从根本上是无状态的。发送一条消息产生一个回复,每次新对话都是一块白板。
这事因为模型本身就是一个巨型函数:输入进去,token 出来,模型权重中没有任何持久化存储能在会话之间保留对话历史。
简单聊天机器人不在乎这一点。让它写一封求职信,写完就结束不需要连续性。
Agent 面对的情况截然不同。它们需要处理长期运行的任务,在时间推移中学习用户偏好,跨多个会话与其他 agent 协作。无状态性构成了根本性障碍,没有人能接受一个每周一早上都要重新自我介绍的个人助理。
错误的心智模型
多数人第一次思考 agent 记忆时,会本能地给出最简答案:往上下文窗口里塞更多东西。上下文窗口就是模型当前能"看到"的全部信息,想让 agent 记住什么就粘贴进去,看起来问题就解决了。
但是上下文窗口是有限的,目前最长的大约在 100 万到 200 万 token 之间。听起来很大,但一个长期运行的自主 agent 积累的状态量可以远远超过这个上限。在触及上限之前还有一个更深层的问题:模型在处理深埋于长上下文中的信息时,表现会明显下降,注意力分布并不均匀。而且上下文是临时性的,会话一结束就消失了。要保持连续性就得在每个新会话开始时重新注入完整历史,代价高且容易出错。
计算机的存储体系是一个更贴切的类比。计算机不会把所有数据都放在 RAM 里,它采用层次结构:快速、小容量的即时内存处理当前工作,较慢、大容量的持久化存储放置其余数据,由系统决定加载什么、保留什么、释放什么。
Agent 记忆遵循相同的逻辑。
Agent 记忆的四种类型
Agent 记忆并非单一概念,它是一个四层体系,各层服务于不同目的。
第一层是工作记忆,对应 agent 当前正在处理的内容,也就是上下文窗口:用户的消息、对话历史,以及已注入的文档或工具调用结果。访问速度快,但完全是临时性的,会话结束即消失。
第二层是情景记忆,记录发生过的事:过去的对话、已完成的任务、做出的决策及其原因。存储在外部,按需检索。可以把它理解为 agent 的日记,赋予它一种个人历史感——"两周前讨论过同样的话题。"
第三层是语义记忆。用户的名字、偏好、角色、所在公司的技术栈,这类事实性知识不绑定于任何特定对话,是 agent 学到并持久存储的独立事实,最接近用户画像或知识库的概念。
第四层是程序记忆,关乎"怎么做":可用的工具、需要遵循的工作流、塑造 agent 行为的系统提示词。模型权重本身也可以视为程序记忆的一种形式——数万亿参数编码了推理、写作和响应的方式。这一层变化最少,但最具基础性。
四种记忆类型映射到技术栈的不同组件上。工作记忆对应上下文窗口;情景记忆和语义记忆对应外部数据库(向量存储、关系型数据库、键值存储);程序记忆对应模型权重和系统提示词。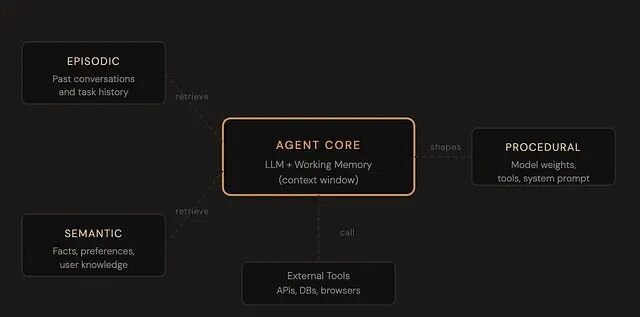
https://avoid.overfit.cn/post/88add337b3214e46a3037a6a446b436a

 浙公网安备 33010602011771号
浙公网安备 33010602011771号