CRAG 架构解析:如何在生成器前修正错误检索结果
绝大多数 RAG 系统把检索当作不会出错的环节,无论拿到的文档是否真正切题,都会径直送入生成器。
"CRAG 提出了标准 RAG 从未追问的问题:如果检索器出错了,该怎么办?"
"不加甄别地引入检索文档,无论其是否相关,都会主动误导生成器,让 RAG 的表现甚至不如不做检索。
CRAG 详解
CRAG 引入了一个轻量级检索评估器,对给定查询所检索到的文档集合给出三种置信度判定之一。
得分达到 UPPER_TH 及以上时判定为"正确":至少有一篇文档具有足够相关性,进入知识精炼流程,将文档拆解为句子级片段,过滤掉无关内容,再将保留下来的部分重组为干净的知识(k_in)。得分在 LOWER_TH 以下则判定为"错误":所有本地文档均不相关,全部丢弃,查询被改写后转入网络搜索,以搜索结果作为外部知识(k_ex)。两个阈值之间的区域称为"模糊",质量不确定,同时使用 k_in 与 k_ex 作为上下文,在两个来源之间对冲风险。
模糊路径是论文中细节最丰富的部分,也是工程实现中最容易被跳过的部分。当评估器拿不准时,同时采信两个来源是最稳妥的策略,但这并不等同于"无条件双源并用"——触发条件明确限定在置信度真正偏低的场景。
分解-再重组算法
即便一篇文档被判定为"正确",其中仍可能夹带大量无关内容。以保险政策文件为例:某一页直接描述理赔程序,其余许多页却充斥着行政样板文字与其他险种的条款定义。CRAG 针对这一问题设计了句子级精炼算法:
- 分解:将每篇检索文档拆分为独立的句子(片段)。
- 过滤:对每个片段评估其与具体查询的相关性,丢弃低于阈值的片段。
- 重组:将保留下来的片段按原始顺序拼接为连贯的上下文字符串。
经过这道处理,送入生成器的上下文不仅体积更小,信息密度也更高——即便文档整体上是相关的,其中的无关句子也不会对生成过程构成干扰。
在原论文中,片段级别的评分由经过微调的 T5 模型完成。本文的代码实现中,片段评分与其他所有评估任务共用同一个 LLM,以少量评分精度的损失换取更简洁的运维结构和更少的模型依赖。
架构图
下图直接取自 CRAG 论文,看图是了解整个系统设计最直接的方式。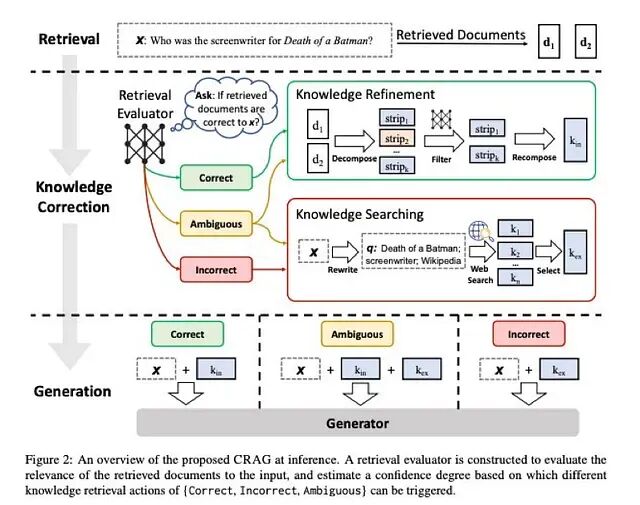
推理阶段的 CRAG 框架。对检索到的文档 d₁ 和 d₂ 进行评估,所得置信度触发三种知识检索动作之一,随后上下文才会被送入生成器。
https://avoid.overfit.cn/post/1a4ba7fc989f4c7f9ca4c61179cf5656

 浙公网安备 33010602011771号
浙公网安备 33010602011771号