BookRAG:面向层级文档的树-图融合RAG框架
现有的RAG系统,无论是基于文本的图方法还是基于版面分割的方法,在面对这类文档时往往失效。根源在于两点:结构与语义的脱节以及工作流程的僵化。
本文介绍的BookRAG或许能提供一个有用的视角。
两种传统方法及其局限
处理这类文档有两种主流范式。
第一种是文本优先方法,将所有内容扁平化为纯文本,主要依赖OCR,再用BM25、经典分块RAG或GraphRAG、RAPTOR等图方法完成检索。其中GraphRAG从文本构建知识图谱,通过社区检测形成带摘要的层级聚类;RAPTOR则递归地对分块做聚类和摘要,形成树状结构。
第二种是版面优先方法,保留原始文档版面,将内容分割为段落、表格、图表、公式等结构化块,再用多模态检索或基于LLM的处理管道(如DocETL)处理相关分块。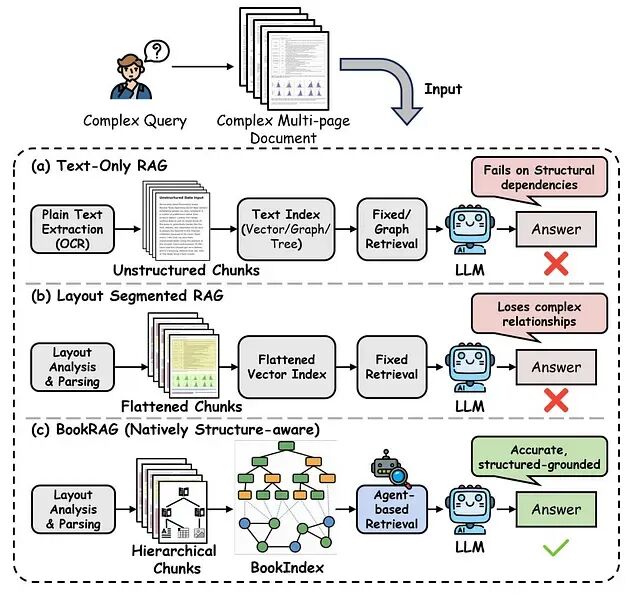
Figure 1: Comparison of existing methods and BookRAG for complex document QA.
两种方法各有价值,但面对类书籍文档时都会遇到两个根本性的问题。
https://avoid.overfit.cn/post/301d874592154a5bada4fd7c777e827e

 浙公网安备 33010602011771号
浙公网安备 33010602011771号