更大的上下文窗口为什么让RAG变得更重要而非更多余
一旦模型能读完所有内容检索增强生成(RAG)就没有存在的必要了,开发者只需要把整个代码库或者多年的聊天记录塞进 prompt,让模型自行处理,所以AI行业花了好几年追逐更大的上下文窗口:4K → 32K → 128K → 1M tokens。
但是真正在生产环境里这么做的时候就出了问题,因为答案变差了。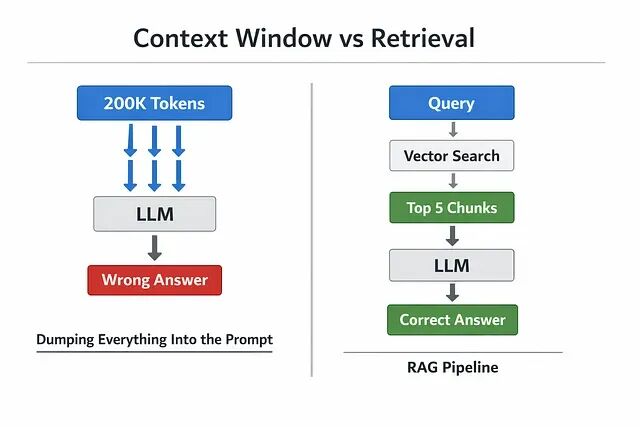
在不少实际系统中,更大的上下文窗口反而拖累了模型表现。
问题出在语言模型处理信息的方式上,LLM 依赖注意力机制对不同概念分配权重,而模型容量虽然在增长,无关上下文的密度一旦上升,注意力分配的可靠性就会迅速衰减。噪声灌进来之后,两个架构层面的故障随之出现:注意力稀释与检索崩溃。
https://avoid.overfit.cn/post/90620d19fba643a680165fbab7b477fd

 浙公网安备 33010602011771号
浙公网安备 33010602011771号