一分钟训练搞懂 DPPO:把扩散过程建模为 MDP 的强化学习方法
机器人领域的专家轨迹、互联网上的文本图像视频,这些数据让生成模型在机器人操控、语言生成与规划、视觉理解等任务上取得了惊人效果。但问题来了:换到具体任务上这些模型往往不太行。这是因为LLM 需要微调才能遵守安全约束或符合人类偏好,机器人策略也得继续训练才能弥补演示数据的不足。
扩散模型和流模型已经成为生成任务的主流方法,强化学习则是任务层面追求最优性能的老路子。两者结合就有了 DDPO、DPPO、FPO、Flow-GRPO 这些工作。这类方法普遍在数十亿参数、图像文本这种高维环境下运行,所以我们换个思路:在一个二维简单环境里研究训练细节,只优化单条去噪轨迹。
这个环境训练不到一分钟,计算资源几乎可以忽略。状态空间和动作空间都简单到指标没什么意义,不过真正有意思的是不同微调策略下涌现出来的视觉行为。虽然这里聚焦于 DPPO 和扩散策略(把数据当作"动作"),但微调动态完全可以推广到其他基于 RL 的扩散应用场景。
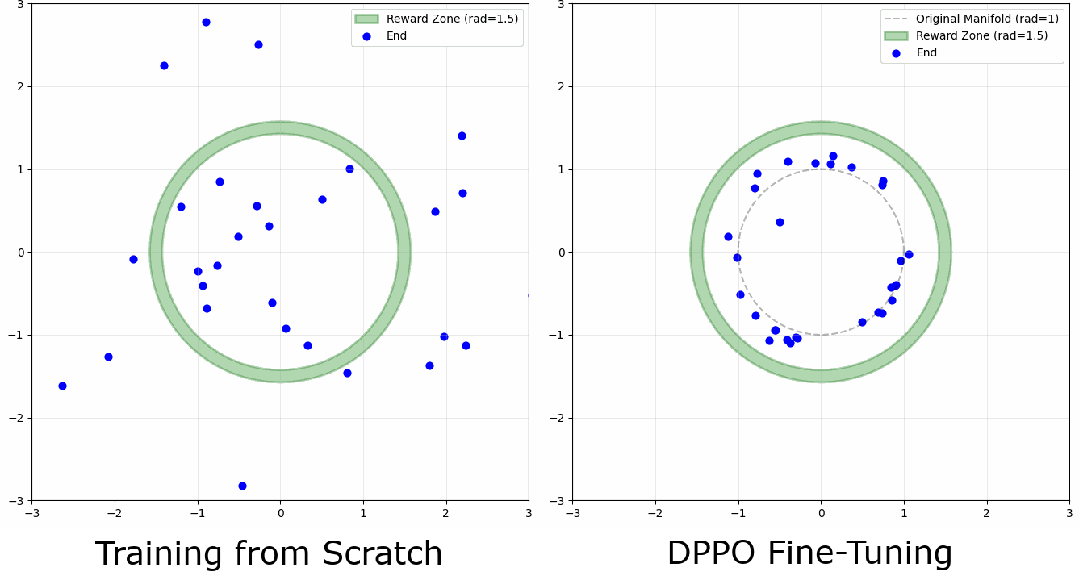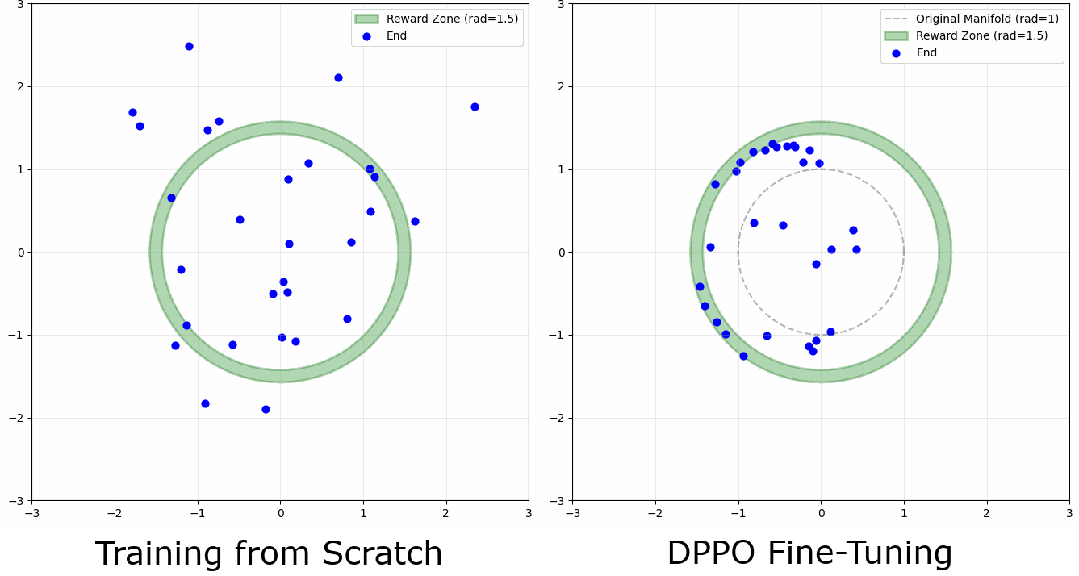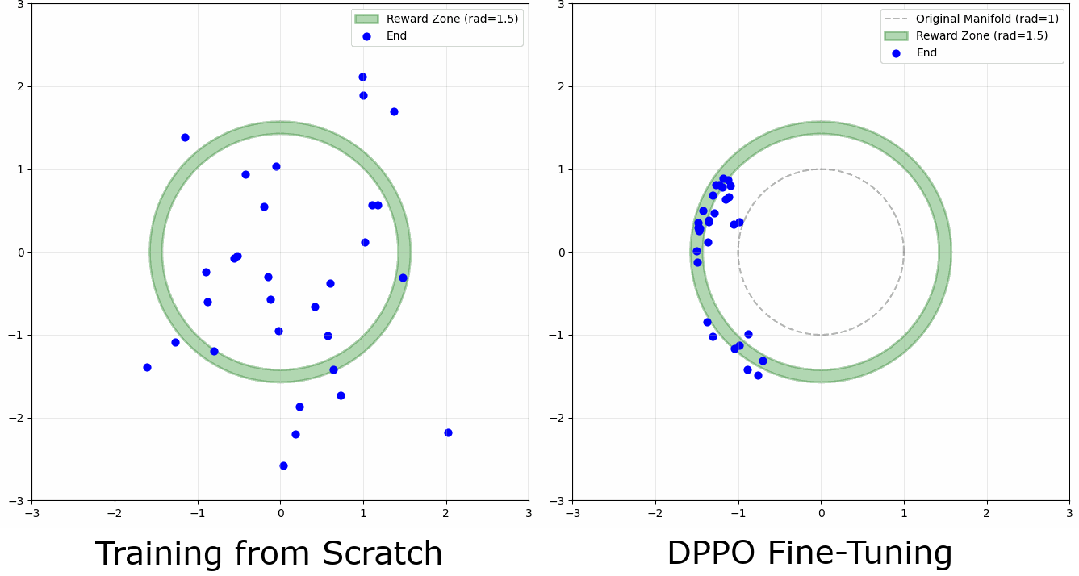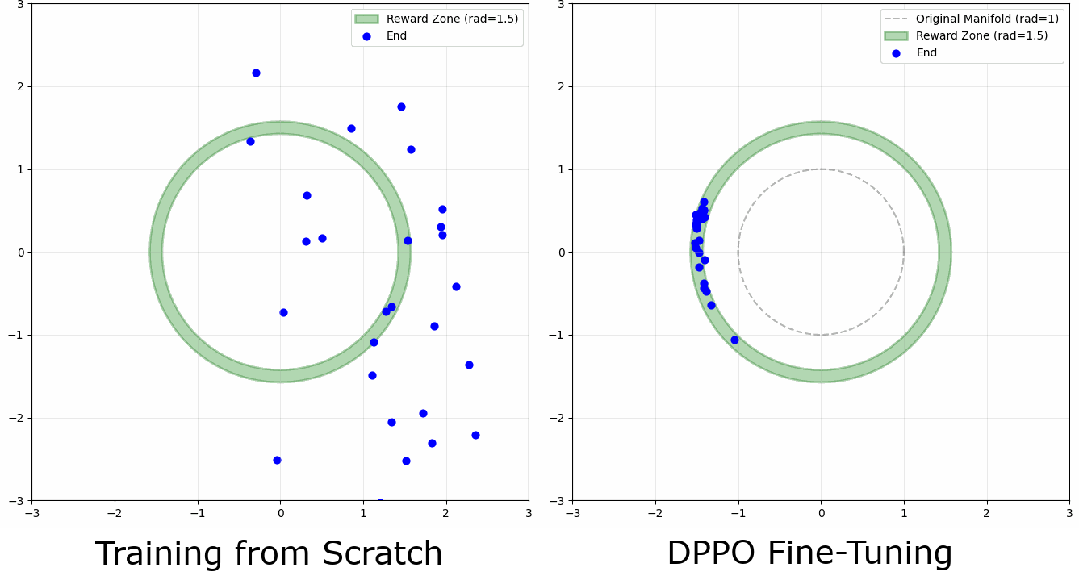
环境
定义一个"环形"高奖励区域,模型要学会把样本去噪到这个环的任意位置。观察点在于:模型会收敛到环上的某个模式,还是把样本均匀分布开?对环宽度的敏感程度如何?下面是一条去噪轨迹的例子:
https://avoid.overfit.cn/post/f27f00300f6c4bf79312ed79a23ae9df

 浙公网安备 33010602011771号
浙公网安备 33010602011771号