从零开始用自定义 Triton 内核编写 FlashAttention-2
本文实现 FlashAttention-2 的前向传播,具体包括:为 Q、K、V 设计分块策略;流式处理 K 和 V 块而非物化完整注意力矩阵;实现在线 softmax 算法保证数值稳定性;支持因果和非因果两种注意力模式;用 Triton autotuner 自动调优内核配置;最后用 PyTorch 验证正确性。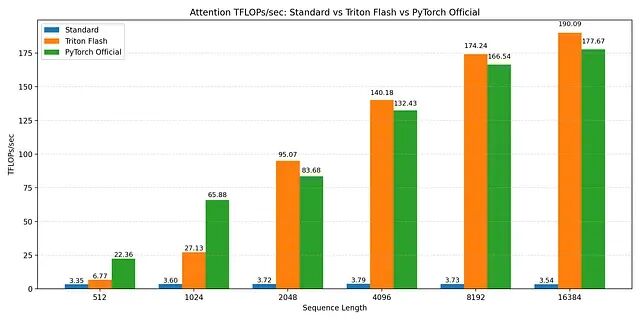
FlashAttention vs. standard attention vs torch2.2 (spda flashattn) TFLOP/s benchmarks
https://avoid.overfit.cn/post/0ae6fbc34b7f4c1788f6399a7a1fc431

 浙公网安备 33010602011771号
浙公网安备 33010602011771号