分类数据 EDA 实战:如何发现隐藏的层次结构
探索性数据分析(EDA)的本质不是画图和算统计量,而是不被自己的数据欺骗。
分类列是最容易出问题的地方。
city
、
category
、
product
、
department
、
role
、
customer_type
——这些列看起来很简单,跑个
value_counts()
画个柱状图搞定了。
其实分类变量往往藏着隐藏的层次结构。这些关系存在于类别内部,不主动挖掘根本看不出来。一旦忽略那么就会得到错误的结论、垃圾特征、误导性的报表。
这篇文章讲的是如何在 EDA 阶段把这些隐藏结构找出来,用实际的步骤、真实的案例,外加可以直接复用的 Python 代码。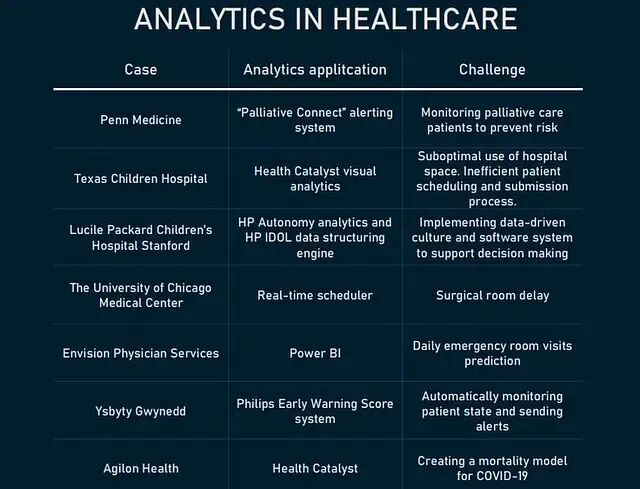
什么是"隐藏层次结构"?
一个分类变量表面看起来是扁平的,实际上却是分层的:这就是隐藏层次结构。
https://avoid.overfit.cn/post/829701eeb5dc40d094b0f69df05c3b15

 浙公网安备 33010602011771号
浙公网安备 33010602011771号