torch.compile 加速原理:kernel 融合与缓冲区复用
PyTorch 的即时执行模式在原型开发阶段很方便,但在推理性能上存在明显短板。每个张量操作独立启动 kernel、独立访问显存,导致内存带宽成为瓶颈GPU 算力无法充分利用。
torch.compile 通过提前构建计算图来解决这个问题。它的核心策略是操作融合和缓冲区复用:第一次调用需要编译而之后的推理会快很多。在 PyTorch 官方的基准测试中,各种模型平均获得了 20%-36% 的加速。
即时执行意味着每个操作独立运行。一个 32 层、每层 100 个操作的模型,前向传播一次就要触发 3200 次 kernel 启动,这些开销全部叠加到推理延迟里。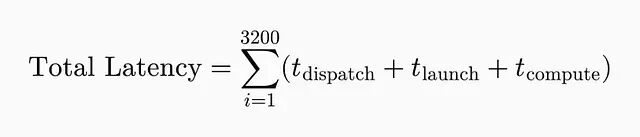
延迟飙升的根本原因是什么?内存才是即时执行成为瓶颈。Nvidia H100 能跑到 300+ TFLOPs但内存带宽只有约 3 TB/s。所以内存搬运的代价太高了,即时执行模式在规模化场景下根本撑不住。每个操作至少要做三次内存访问:从 VRAM 读输入张量、把中间结果写回 VRAM、再从 VRAM 读权重。
https://avoid.overfit.cn/post/271bbf42f4a946c3a92b8a9745e223db

 浙公网安备 33010602011771号
浙公网安备 33010602011771号