为什么所有主流LLM都使用SwiGLU?
本文的目标是解释为什么现代LLM架构在前馈部分使用
SwiGLU
作为激活函数并且已经放弃了
ReLU
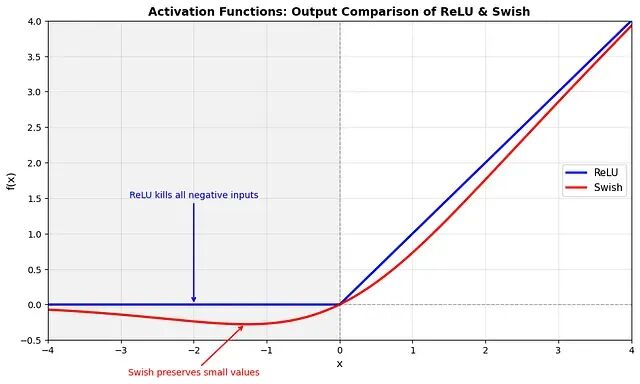
神经网络本质上是一系列矩阵乘法,如果我们堆叠线性层而不使用任何激活函数:
无论你堆叠多少层,它仍然只是一个线性变换,网络只能学习线性关系。
激活函数引入了非线性,使网络能够逼近复杂的非线性函数,这是深度学习表达能力的基础。
https://avoid.overfit.cn/post/3fa28c75fb0b4874aa297defa145ec4a
本文的目标是解释为什么现代LLM架构在前馈部分使用
SwiGLU作为激活函数并且已经放弃了
ReLU
神经网络本质上是一系列矩阵乘法,如果我们堆叠线性层而不使用任何激活函数:
无论你堆叠多少层,它仍然只是一个线性变换,网络只能学习线性关系。
激活函数引入了非线性,使网络能够逼近复杂的非线性函数,这是深度学习表达能力的基础。
https://avoid.overfit.cn/post/3fa28c75fb0b4874aa297defa145ec4a

 浙公网安备 33010602011771号
浙公网安备 33010602011771号