大规模向量检索优化:Binary Quantization 让 RAG 系统内存占用降低 32 倍
当文档库规模扩张时向量数据库肯定会跟着膨胀。百万级甚至千万级的 embedding 存储,float32 格式下的内存开销相当可观。
好在有个经过生产环境验证的方案,在保证检索性能的前提下大幅削减内存占用,它就是Binary Quantization(二值化量化)
本文会逐步展示如何搭建一个能在 30ms 内查询 3600 万+向量的 RAG 系统,用的就是二值化 embedding。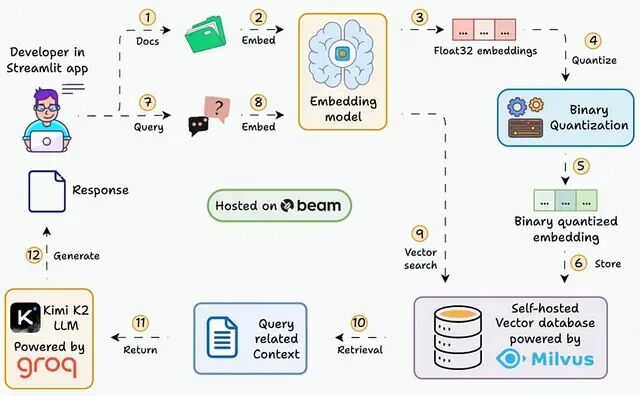
二值化量化解决什么问题
常规 embedding 用 float32 存储:单个 embedding(1024 维)占 4 KB 左右,3600 万个 embedding 就是 144 GB
二值化量化把每个维度压缩成 1 bit:同样的 embedding 只需 128 bytes,3600 万个 embedding 降到 4.5 GB
内存直接减少约 32 倍,而且位运算做相似度搜索更快。
https://avoid.overfit.cn/post/3a922ea4c69b4e2883a63da1d314dadb

 浙公网安备 33010602011771号
浙公网安备 33010602011771号