ONNX Runtime Python 推理性能优化:8 个低延迟工程实践
在深度学习落地过程中,有一个常见的误区:一旦推理速度不达标,大家的第一反应往往是拿着模型开到,比如:做剪枝、搞蒸馏、甚至牺牲精度换小模型。
实际上生产环境中的 Python 推理链路隐藏着巨大的“工程红利”。很多时候你的模型本身并不慢,慢的是低效的数据搬运、混乱的线程争用以及不合理的 Runtime 默认配置。在不改变模型精度的情况下,仅靠ONNX Runtime (ORT) 的工程特性,往往就能从现有技术栈中“抠”出惊人的性能提升。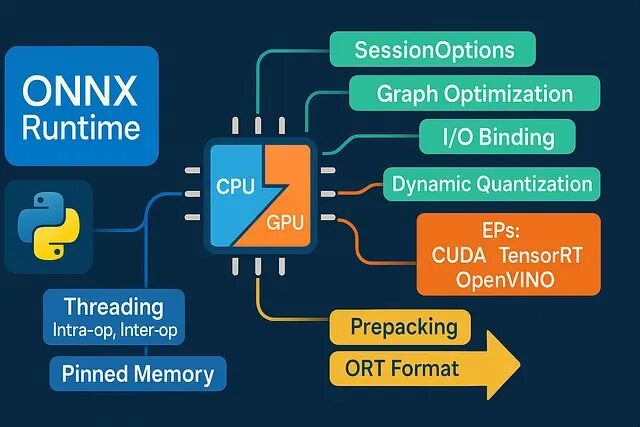
以下是 8 个经过实战验证的低延迟优化策略,专治各种“莫名其妙的慢”。
https://avoid.overfit.cn/post/aa489c6b429641b9b1a1a3e4a3e4ce1d

 浙公网安备 33010602011771号
浙公网安备 33010602011771号