PyTorch推理扩展实战:用Ray Data轻松实现多机多卡并行
单机 PyTorch 模型跑推理没什么问题,但数据量一旦上到万级、百万级,瓶颈就暴露出来了:内存不够、GPU 利用率低、I/O 拖后腿,更别说还要考虑容错和多机扩展。
传统做法是自己写多线程 DataLoader、管理批次队列、手动调度 GPU 资源,这哥工程量可不小,调试起来也麻烦。Ray Data 提供了一个更轻量的方案:在几乎不改动原有 PyTorch 代码的前提下,把单机推理扩展成分布式 pipeline。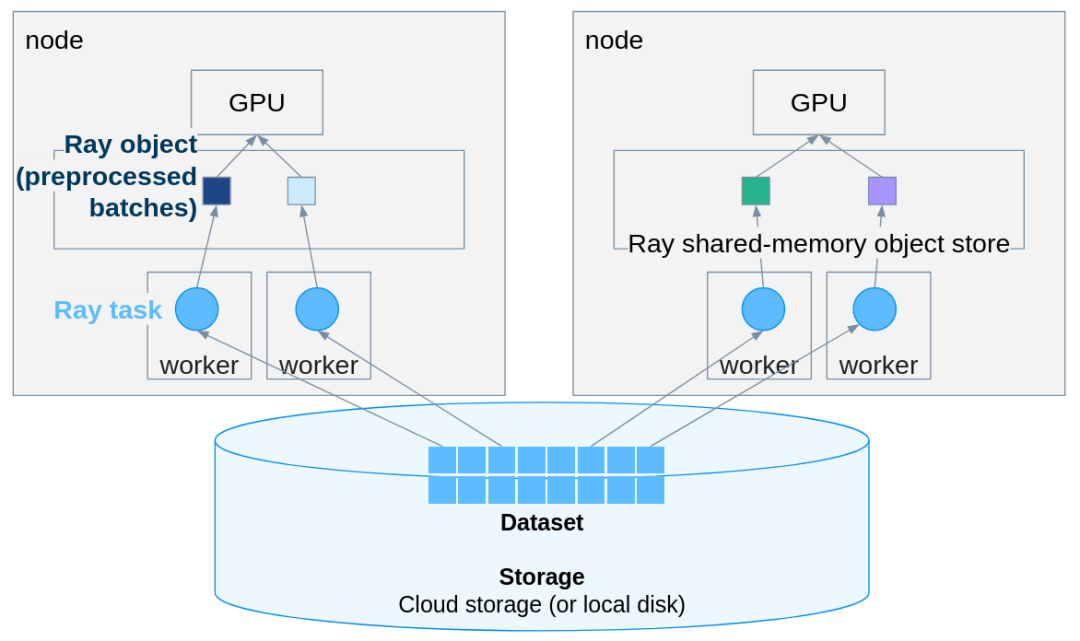
单机 PyTorch 模型跑推理没什么问题,但数据量一旦上到万级、百万级,瓶颈就暴露出来了:内存不够、GPU 利用率低、I/O 拖后腿,更别说还要考虑容错和多机扩展。
传统做法是自己写多线程 DataLoader、管理批次队列、手动调度 GPU 资源,这哥工程量可不小,调试起来也麻烦。Ray Data 提供了一个更轻量的方案:在几乎不改动原有 PyTorch 代码的前提下,把单机推理扩展成分布式 pipeline。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号