高级检索增强生成系统:LongRAG、Self-RAG 和 GraphRAG 的实现与选择
检索增强生成(RAG)早已不是简单的向量相似度匹配加 LLM 生成这一套路。LongRAG、Self-RAG 和 GraphRAG 代表了当下工程化的技术进展,它们各可以解决不同的实际问题。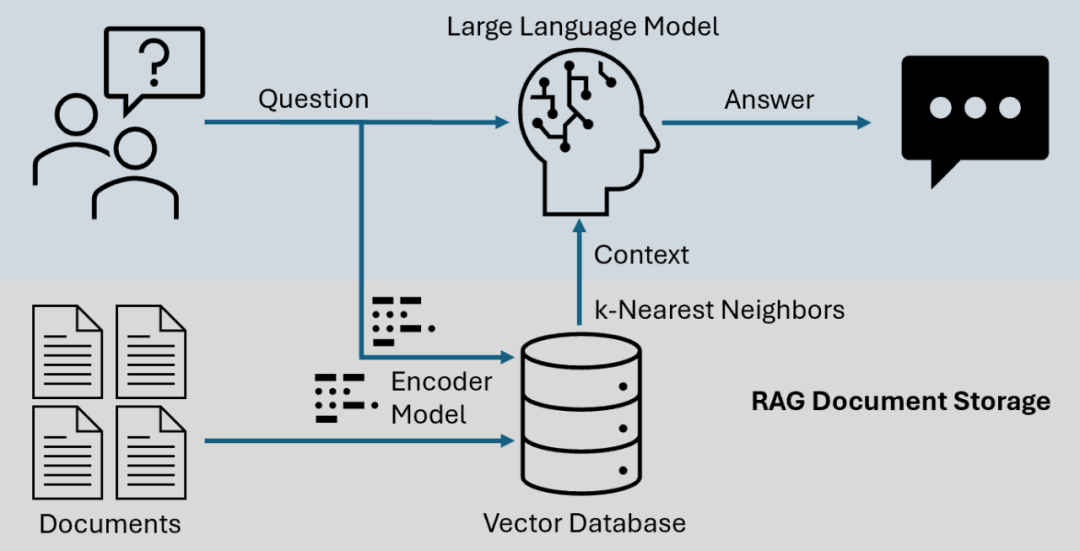
传统 RAG 的核心限制
标准的 RAG 流程大概是这样的:把文档分割成小块、向量化、通过余弦相似度检索、喂给 LLM。这套路对很多场景确实够用,但会遇到很多问题,比如:
跨越式的上下文依赖。一个完整的逻辑链条可能横跨几千个词,而小块划分会把它们切散。其次是检索的盲目性,系统拉回来的内容有没有真正用处,完全没有办法自检。最后就是关系的表达能力。向量相似度再相关,也就是找找"感觉差不多"的内容,实体间的复杂联系它看不见。
高级 RAG 的这几种变体,正是为了解决这些问题而设计的。
https://avoid.overfit.cn/post/20ba0abf1ad148998a5adf7fcc521c8f

 浙公网安备 33010602011771号
浙公网安备 33010602011771号