从另一个视角看Transformer:注意力机制就是可微分的k-NN算法
注意力机制听起来很玄乎,但我们可以把它看作一个软k-NN算法。查询向量问:"谁跟我最像?",softmax投票,相似的邻居们返回一个加权平均值。这就是注意力头的另外一种解释: 一个可微分的软k-NN:计算相似度 → softmax转换为权重 → 对邻居值求加权平均。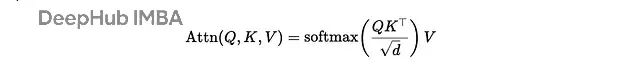
通过
1/sqrt(d)
缩放防止softmax在高维时饱和,掩码决定哪些位置可以互相"看见"(处理因果关系、填充等问题)。
想象有个查询向量 𝐪 在问:"哪些token跟我相似?"
接下来就是三步走:
- 把 𝐪 跟每个键 𝒌 ᵢ 做比较,算出相似度分数
- Softmax把这些分数归一化成概率分布(分数越高权重越大)
- 用这些权重对值向量 𝐯ᵢ 做加权平均
这就是注意力的另外一种解释:考虑序列顺序的软邻居平均算法。
https://avoid.overfit.cn/post/036fe92cd30245fbb4d7ff97f5301c36

 浙公网安备 33010602011771号
浙公网安备 33010602011771号