ReasonRank:从关键词匹配到逻辑推理,排序准确性大幅超越传统方法
本文深入分析ReasonRank,一个采用自动化数据合成框架和两阶段训练策略(监督微调+强化学习)的先进段落重排器,该系统在信息检索领域实现了突破性的推理能力,在BRIGHT等权威基准测试中超越了参数规模更大的现有模型。
信息检索技术在过去十年中经历了深刻变革。现代搜索引擎和人工智能助手已能够精准理解用户的真实查询意图,而非仅仅依赖字面输入。用户能够提出复杂问题并在毫秒级时间内获得相关文档响应。这一技术突破主要依赖于一类被称为"重排器"的模型,这些模型接收初始检索结果并通过智能化排序将最优结果置于前列。
列表式重排作为当前的主流技术,通过对整个段落列表的全局分析和上下文理解实现了卓越的性能表现。大型语言模型的发展进一步增强了这一能力。
然而在技术进步的表象之下,一个关键问题正在显现。尽管模型在语义理解方面持续改进,但在推理能力方面却面临瓶颈制约。
现代搜索系统的核心挑战:推理能力缺失
考虑专业应用场景中的典型查询需求:根据Python错误跟踪信息和现有代码,从多个Stack Overflow解决方案中识别采用正确逻辑修复方法的方案,而非仅基于语法相似性的匹配;在多个法律文档中确定为特定判例提供最有力证据支持的文档;基于患者症状和实验室检查结果,从医学研究文献中筛选出最相关的诊断路径指导。
这类查询需求远超简单的关键词或主题匹配。它们要求系统具备多步骤逻辑处理能力,包括证据关联、因果关系理解以及推理链构建。当前最先进的重排器虽然在模式识别方面表现出色,但在面对需要深度结构化推理的复杂任务时往往力不从心。
问题的根本原因在于训练数据的特性。现有重排器主要基于MSMARCO等大规模通用数据集进行训练。虽然这些数据集具有重要价值,但其相关性判断往往依赖于词汇或语义层面的重叠度。段落被认为相关的标准通常是包含正确实体或讨论相同高层主题。这种训练范式在模型学习方式与复杂实际应用需求之间形成了显著的"推理差距",导致即使是最先进的重排器也难以在复杂任务中显著改善初始检索结果。
来自中国人民大学、百度公司和卡内基梅隆大学的联合研究团队针对这一挑战展开深入研究。他们于2025年8月9日发表的论文"ReasonRank: Empowering Passage Ranking with Strong Reasoning Ability"不仅提供了技术改进方案,更重要的是提出了构建具备真正推理能力模型的全新范式。
核心创新:自动化专家知识生成
研究团队识别出瓶颈并非源于大型语言模型的推理潜力不足,而是高质量推理密集型训练数据的严重匮乏。传统的人工标注方法成本高昂且效率低下。基于此认知,研究团队提出了一个突破性问题:是否可以通过自动化方式创建理想的专家级训练课程?
这一思路构成了ReasonRank的核心创新理念。研究团队设计了一个自动化框架,能够从零开始合成大规模、多样化且高保真度的训练数据集。该框架的关键组件是强大的大型推理模型DeepSeek-R1,其作用类似于"专家导师"。
该专家导师系统承担的任务远超传统的二元相关性标注。其主要功能包括:生成推理链,不仅提供正确答案,还明确阐述达成排序决策的逐步推理过程;挖掘高质量样本,既要识别真正相关的正例段落,也要发现表面相关但逻辑上存在缺陷或实际无用的困难负例段落。
通过这种专家级数据生成的自动化实现,ReasonRank团队创建了一个可扩展的数据稀缺问题解决方案,为缩小推理差距奠定了基础。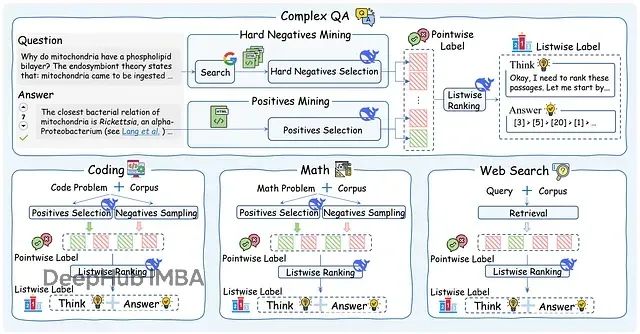
https://avoid.overfit.cn/post/6f92ff4d6ec54ae083b0170c535c8420

 浙公网安备 33010602011771号
浙公网安备 33010602011771号