PCA多变量离群点检测:Hotelling's T2与SPE方法原理及应用指南
主成分分析(Principal Component Analysis, PCA)作为一种经典的无监督降维技术,在保留数据主要信息的同时能够有效压缩数据维度。由于PCA对数据变异性的高度敏感性,该方法在多变量异常值检测领域展现出独特的优势。
当分析任务需要建立早期预警系统以识别异常状态,并且要求结果具备良好的可解释性和透明度时,基于PCA的异常检测方法提供了理想的解决方案。尽管多变量数据集的异常值检测因高维性和无标签特性而面临诸多挑战,但PCA方法凭借其固有的降维能力和可视化特性,为这一难题提供了有效的解决途径。
本文将系统阐述基于PCA的异常值检测理论框架,重点介绍霍特林T²统计量和SPE/DmodX(平方预测误差/距离建模残差)两种核心方法,并通过连续变量和分类变量的实际案例,详细演示无监督异常值检测模型的构建过程。
异常值检测方法论:单变量与多变量分析的比较
异常值检测的方法学框架可以划分为单变量和多变量两种基本范式(图1)。单变量方法采用逐个变量分析的策略,通过数据分布特征分析来识别偏离正常范围的观测值,这种方法在处理低维数据时具有较好的效果。
多变量方法则同时考虑多个特征变量之间的相互关系,能够捕获线性或非线性关联模式中的异常观测,对于具有偏斜分布特征的高维数据表现出更强的检测能力。在Python生态系统中,scikit-learn库提供了丰富的多变量异常检测算法实现,包括单类支持向量机(One-Class SVM)、孤立森林(Isolation Forest)和局部异常因子(Local Outlier Factor)等方法。
本文专注于基于主成分分析的多变量异常值检测方法,该方法的核心优势在于其优异的可解释性:通过PCA的降维特性,异常值可以在低维空间中进行直观的可视化展示,为分析人员提供清晰的几何直觉。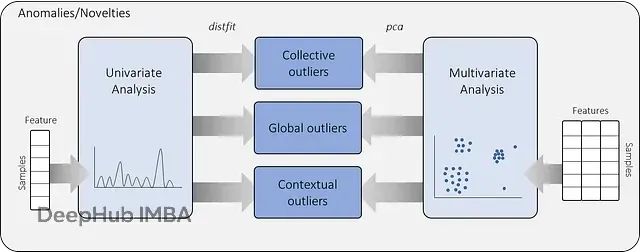
图1. 单变量与多变量异常值检测方法的分析框架比较。多变量数据集的异常值检测方法是本文的核心内容
异常值与新颖性检测的概念区分
https://avoid.overfit.cn/post/8c6580ce36cc43dbaba5ddacbc915bad

 浙公网安备 33010602011771号
浙公网安备 33010602011771号