GSPO:Qwen让大模型强化学习训练告别崩溃,解决序列级强化学习中的稳定性问题
这是7月份的一篇论文,Qwen团队提出的群组序列策略优化算法及其在大规模语言模型强化学习训练中的技术突破
大规模强化学习的稳定性挑战
强化学习(Reinforcement Learning, RL)已成为构建先进大语言模型(Large Language Models, LLMs)的核心技术环节。通过人类反馈强化学习(RLHF)和AI反馈强化学习(RLAIF)等方法,模型获得了执行复杂指令、进行多步推理以及与人类偏好对齐的能力。
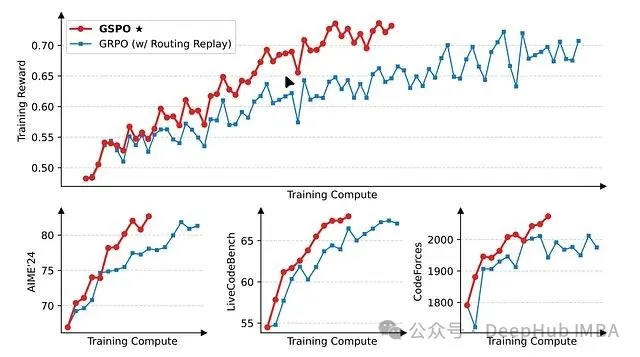
然而大规模强化学习面临的核心挑战在于训练稳定性。在实际训练过程中,模型经常出现突发性性能退化,表现为能力丢失和输出质量严重下降,这种现象被称为"模型崩溃"。此类不稳定性不仅造成大量计算资源浪费,更严重阻碍了技术发展进程。
Qwen团队在其最新研究中提出了群组序列策略优化(Group Sequence Policy Optimization, GSPO)算法,该算法针对性地解决了上述稳定性问题。为深入理解GSPO的技术价值,本文将首先分析其前身算法群组相对策略优化(Group Relative Policy Optimization, GRPO)的设计理念与内在缺陷,进而阐述GSPO如何通过算法改进实现更稳健的训
https://avoid.overfit.cn/post/7e72446552ba45fa9b263b8db170827c

 浙公网安备 33010602011771号
浙公网安备 33010602011771号