LLM开发者必备:掌握21种分块策略让RAG应用性能翻倍
检索增强生成(Retrieval-Augmented Generation, RAG)是当前AI工程师在实际应用中面临的重要技术挑战之一。从理论角度来看,RAG的工作原理相对直观:从自定义数据源中检索相关上下文,然后基于这些上下文让大语言模型生成对应的回答。
在实际部署过程中,开发者往往需要处理大量格式混乱的异构数据,并经历反复的系统调优过程,包括分块策略的优化、嵌入模型的选择、检索器的配置、排序器的微调以及提示工程等多个环节。即便如此,系统仍可能出现信息检索不足或生成虚假信息的问题。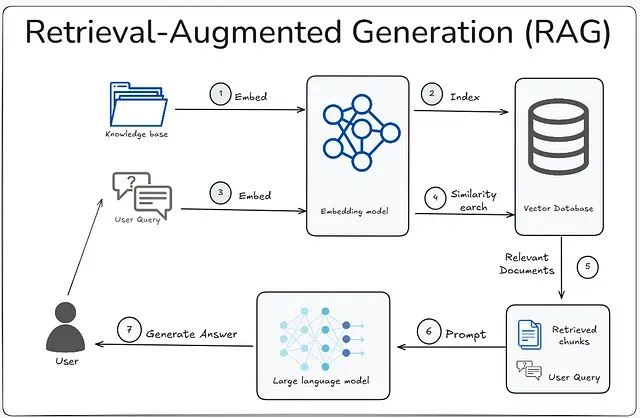
RAG系统包含多个相互关联的组件,其中文本分块策略是决定整个系统性能的关键因素。不同的数据类型、文件格式、内容结构、文档长度和应用场景都需要采用相应的分块策略。分块策略的选择不当会直接影响检索质量和生成效果。
本文将系统介绍21种文本分块策略,从基础方法到高级技术,并详细分析每种策略的适用场景,以帮助开发者构建更加可靠的RAG系统。
https://avoid.overfit.cn/post/e2c4af013010450788db34351fd9d6f3

 浙公网安备 33010602011771号
浙公网安备 33010602011771号