DGMR压缩技术:让大规模视觉Transformer模型体积减半而性能不减
Transformer架构展现出卓越的扩展特性,其性能随模型容量增长而持续提升。大规模模型在获得优异性能的同时,也带来了显著的计算和存储开销。深入分析主流Transformer架构发现,多层感知器(MLP)模块占据了模型参数的主要部分,这为模型压缩提供了重要切入点。
针对这一问题,研究者提出了多样性引导MLP缩减(Diversity-Guided MLP Reduction, DGMR)方法,该方法能够在保持性能近乎无损的前提下显著缩减大型视觉Transformer模型。DGMR采用基于Gram-Schmidt的剪枝策略,系统性地移除MLP层中的冗余神经元,同时通过精心设计的策略确保剩余权重的多样性,从而在知识蒸馏过程中实现高效的性能恢复。
实验结果表明,经过剪枝的模型仅需使用LAION-2B数据集的0.06%(无标签数据)即可恢复至原始精度水平。在多个最先进的视觉Transformer模型上的广泛实验验证了DGMR的有效性,该方法能够减少超过57%的参数量和浮点运算次数(FLOPs),同时保持性能几乎无损。值得注意的是,在EVA-CLIP-E(4.4B参数)模型上,DGMR实现了71.5%的参数缩减率,且未出现性能下降。
Transformer架构在计算机视觉和自然语言处理领域展现出强大的能力,其性能与模型规模呈现正相关关系。然而,大规模Transformer模型虽然能够达到极高的准确率,但其带来的计算复杂度和内存需求也呈指数级增长,严重限制了模型的实际部署和广泛应用。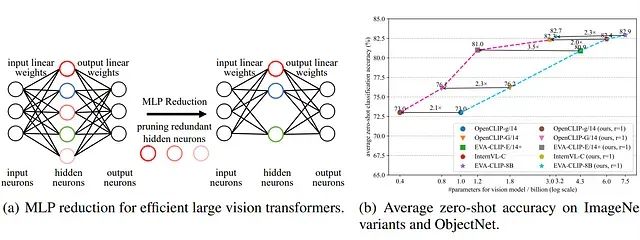
(a)视觉Transformer模型中较大的MLP扩展比导致存在大量冗余参数,为模型压缩提供了机会。(b)本方法在现有最先进大型Transformer模型的压缩任务中实现了近似无损的优异性能
https://avoid.overfit.cn/post/a14cb35858d44dfa994c52fdb2c008c6

 浙公网安备 33010602011771号
浙公网安备 33010602011771号