Google DeepMind发布MoR架构:50%参数超越传统Transformer,推理速度提升2倍
自2017年Vaswani等人发表"Attention Is All You Need"以来,Transformer架构已成为现代自然语言处理和人工智能系统的核心基础,为GPT、BERT、PaLM和Gemini等大型语言模型提供了强有力的技术支撑。然而,随着模型规模的不断扩大和任务复杂性的持续增长,传统Transformer架构面临着日益严峻的计算资源消耗和内存占用挑战。
这是7月Google DeepMind与韩国科学技术院(KAIST)和蒙特利尔学习算法研究所(Mila)联合提出了一项重要的架构创新——递归混合(Mixture of Recursions, MoR)。这一新型架构通过引入自适应令牌级计算机制,在显著降低参数数量和计算开销的同时,实现了超越标准Transformer的性能表现。
本文深入分析MoR架构的核心技术创新,详细阐述其在令牌级推理、内存管理和训练效率方面相对于传统Transformer架构的显著优势。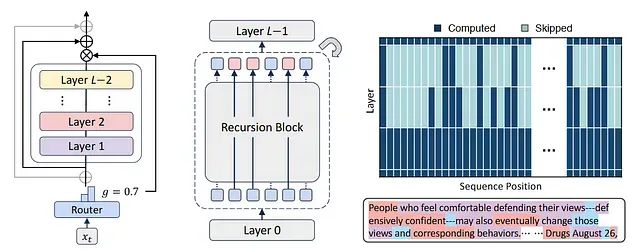
https://avoid.overfit.cn/post/1703bc65882e4336ae3f5206daa61cfc

 浙公网安备 33010602011771号
浙公网安备 33010602011771号