构建高性能LLM推理服务的完整方案:单GPU处理172个查询/秒、10万并发仅需15美元/小时
在构建智能代理、检索增强生成(RAG)系统或大语言模型应用时,核心组件往往是通过API访问的大语言模型(LLM)。专业的服务提供商通过模型优化技术实现高效且可扩展的推理服务。
这些优化技术主要包括权重量化(W4A16、W4A8等)、键值缓存(KV Cache)、推测解码(Speculative Decoding)等推理时优化方法。在部署层面,Kubernetes Pod调度和Docker容器化技术确保当某个集群面临高流量时,能够将请求重定向至其他可用的Pod或集群节点。每个系统组件都经过精心优化,以高效处理百万级别的并发查询请求。
本文将通过系统性实验不同的优化技术来构建自定义LLaMA模型服务,目标是高效处理约102,000个并行查询请求,并通过对比分析确定最优解决方案。
研究重点集中在模型架构优化和云端部署策略,采用延迟、内存消耗和准确性等关键指标对优化后的LLM进行综合评估。
开发与部署管道架构
本文涉及模型权重优化、延迟性能调优和Kubernetes集群部署等多个复杂环节,首先建立清晰的管道架构视图至关重要。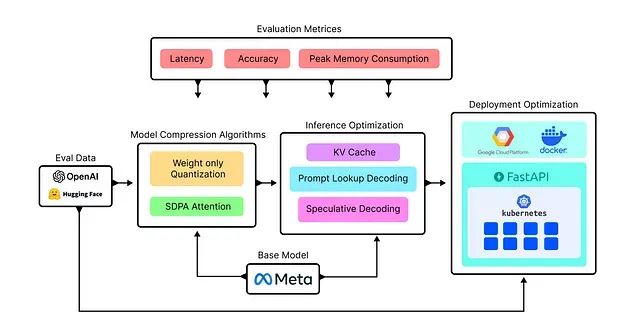
实验设计采用双数据集评估策略,分别用于开发阶段的算法验证和部署阶段的性能测试。评估体系基于三个核心性能指标:延迟性能用于衡量并行处理过程中LLM API调用的响应时间;准确性指标评估各种优化算法应用后生成答案的质量;峰值内存消耗监测LLM推理过程中的平均内存使用情况。
实验流程分为三个阶段。首先进行模型权重优化技术的试验研究,通过应用不同算法优化模型权重并评估各技术的效果。其次专注于LLM推理步骤的优化,以提升实时处理效率。最后进入基于Kubernetes和Docker的部署阶段优化。完成部署后,将使用约100,000个查询对系统进行大规模测试,以验证整体性能表现。
https://avoid.overfit.cn/post/36f952daee8847af919f4db990775ea5

 浙公网安备 33010602011771号
浙公网安备 33010602011771号