ViTAR:模糊位置编码让视觉Transformer适配任意分辨率图像
视觉Transformer在计算机视觉领域展现出强大的性能,但其对输入图像尺寸的严格约束限制了在实际应用中的灵活性。ViTAR(Vision Transformer with Any Resolution)通过引入模糊位置编码技术,实现了对任意分辨率图像的处理能力,为计算机视觉的实际应用开辟了新的技术路径。
计算机视觉技术的快速发展中,视觉Transformer(ViT)作为重要的技术突破,在图像分类、目标检测等任务中取得了显著成果。传统ViT架构存在一个关键技术限制:要求所有输入图像具有统一的尺寸规格。这一约束在处理真实世界的多样化数据时带来了显著挑战,特别是在遥感图像、医学影像、监控视频等领域,图像数据往往具有不同的分辨率和宽高比。ViTAR通过创新的模糊位置编码机制,成功解决了这一技术瓶颈。
本文将深入分析ViTAR相对于传统ViT的技术改进,重点阐述模糊位置编码的工作原理及其技术实现。
任意分辨率视觉Transformer的技术架构
ViTAR是一种新型的基于Transformer的视觉架构,其核心创新在于能够直接处理不同尺寸的图像数据,无需进行尺寸标准化或图像裁剪预处理。这一技术特性在需要保持原始空间信息完整性的应用场景中具有重要价值。
在传统的图像处理流程中,不同尺寸的图像数据需要通过缩放、裁剪等预处理操作统一到固定分辨率,这种处理方式可能导致关键空间信息的丢失。ViTAR通过技术创新避免了这一问题,其主要技术优势体现在:支持任意分辨率的图像输入、采用创新的模糊位置编码技术实现精确的空间位置感知、在高分辨率真实数据上保持稳定的性能表现。
ViTAR的技术特性使其在多个专业领域具有重要应用价值。在遥感图像处理中,该技术能够处理不同分辨率的卫星图像数据,确保地理信息的完整性和精度。在医学影像分析领域,ViTAR可以直接处理CT扫描、MRI或X射线图像的原始分辨率数据,避免因图像预处理导致的诊断信息丢失。在智能监控系统中,该技术能够适应不同摄像设备产生的多样化视频帧格式。此外,在文档分析和处理场景中,ViTAR能够有效处理不同格式和宽高比的扫描文档。
ViTAR采用多分辨率数据集进行训练,通过这种训练策略使模型学会在不同分辨率间进行有效泛化。这种训练方法使得ViTAR特别适合处理真实世界的复杂数据集,相比之下,传统ViT主要依赖于固定尺寸的标准化数据集(如ImageNet)进行训练。
技术对比分析
ViTAR与传统ViT在技术特性上存在显著差异。从灵活性角度分析,ViTAR提供了更高的输入适应性,能够处理任意分辨率的图像数据,而传统ViT则需要固定的输入尺寸。在性能表现方面,ViTAR在真实世界的高分辨率任务中表现出色,而传统ViT在处理标准化数据集时具有更好的计算效率。从实现复杂度来看,ViTAR的模糊位置编码机制增加了一定的技术复杂性,但传统ViT在处理统一标准化图像数据集时实现更为直接。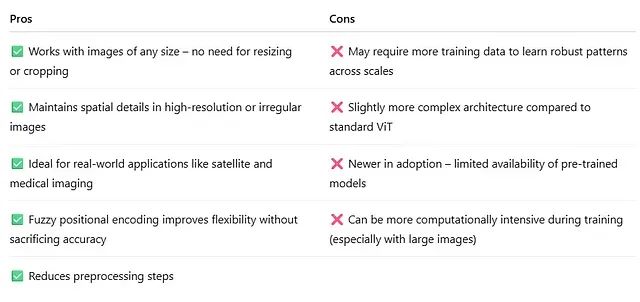
https://avoid.overfit.cn/post/4f2588ea51fb444eb65d73da527a3f04

 浙公网安备 33010602011771号
浙公网安备 33010602011771号