信息检索重排序技术深度解析:Cross-Encoders、ColBERT与大语言模型方法的实践对比
现代搜索系统的核心挑战不仅在于从海量文档集合中检索相关信息,更在于对检索结果进行精准排序,确保用户能够快速、可靠且经济高效地获得所需信息。在面对不同重排序技术方案时,工程师们需要在延迟性能、硬件资源消耗、系统集成复杂度以及用户体验质量之间进行权衡决策。本文将深入分析三种主流的重排序技术:Cross-Encoders(交叉编码器)、ColBERT以及基于大语言模型的重排序器,并详细阐述各方案在实际应用中的性能表现、成本考量以及适用场景。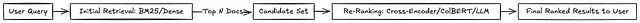
Cross-Encoders:基于深度成对分析的精确排序
Cross-Encoders采用Transformer架构对查询-文档对进行联合编码处理,部分先进模型在MS MARCO等权威基准测试中取得了显著成果,MRR@10指标可达40以上。该技术的核心优势在于能够对初始检索获得的候选文档集(如前50名结果)进行精确重排序,使最相关的答案优先展示。在高精度要求场景中,这种排序准确性直接影响用户对系统的信任度以及最终的转化效果。
技术挑战与成本分析: Cross-Encoders的计算复杂度在于每个文档的重排序都需要执行完整的前向传播过程。当系统需要处理每秒数千次查询请求,且每次查询涉及100个候选文档的cross-encode处理时,将面临显著的GPU资源消耗和延迟增长。在未优化状态下,单次查询的延迟增长预期至少达到数百毫秒级别。为控制成本,技术团队通常采用文本截断策略降低token数量、实施查询批处理机制或对高频查询结果进行缓存。部分团队选择采用托管服务(如Cohere API)以简化部署复杂度,但这种方式将成本控制权转移至外部服务提供商。
对于日处理百万级查询的大规模系统,纯Cross-Encoder方案的经济成本可能难以承受。但是在专业领域应用中,当查询频次相对较低但单次查询价值较高时,Cross-Encoders能够在最终排序阶段提供接近专家级别的精确度。可将其视为确保用户获得最优质结果的最终质量保障机制。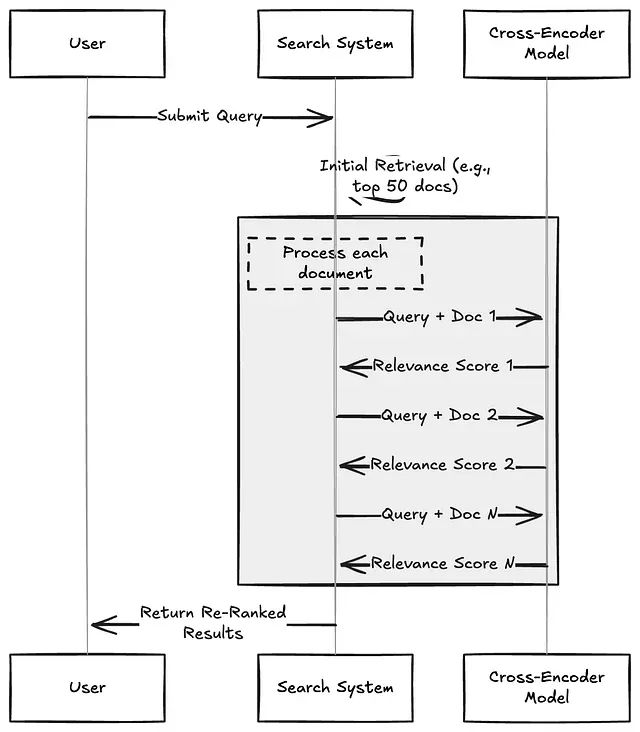
https://avoid.overfit.cn/post/ad38e08e97da42eb8820731ee3e59752

 浙公网安备 33010602011771号
浙公网安备 33010602011771号