量化交易隐藏模式识别方法:用潜在高斯混合模型识别交易机会
在SPY股票数据分析过程中,虽然能够有效识别日线价格趋势,但挖掘数据中的潜在模式仍然面临重大挑战。市场数据普遍存在高噪声特征,传统分析工具难以识别稳定的行为模式。移动平均线等常规技术指标虽然能够平滑数据,但往往掩盖了数据的内在结构信息。潜在高斯混合模型(Latent Gaussian Mixture Models, LGMM)为这一问题提供了有效的解决方案,能够将复杂的数据混沌转换为清晰的聚类结构,成功识别出SPY数据中的稳定期和波动峰值等不同市场状态。
本文将从技术实现角度阐述LGMM相对于传统方法的优势,通过图表对比分析展示其效果,并详细说明量化分析师和技术分析师如何应用此方法优化投资决策。LGMM的实现原理相对直观,但其在数据分析中的应用价值显著,有潜力改变传统的市场数据分析方法。
潜在高斯混合模型理论基础
潜在高斯混合模型是一种用于识别复杂数据集中隐藏群组结构的统计学习方法。该模型的核心假设是观测数据来源于多个高斯分布(正态分布)的混合,这些分布代表了数据中不同的潜在状态或模式。根据Reynolds(2009)的研究,这种方法类似于根据特征差异将混合样本分类为不同类别的过程,每个类别都具有特定的中心位置(均值)和离散程度(方差)。
LGMM采用期望最大化(Expectation-Maximization, EM)算法进行参数估计,通过迭代优化过程逐步精确确定各个混合组件的参数。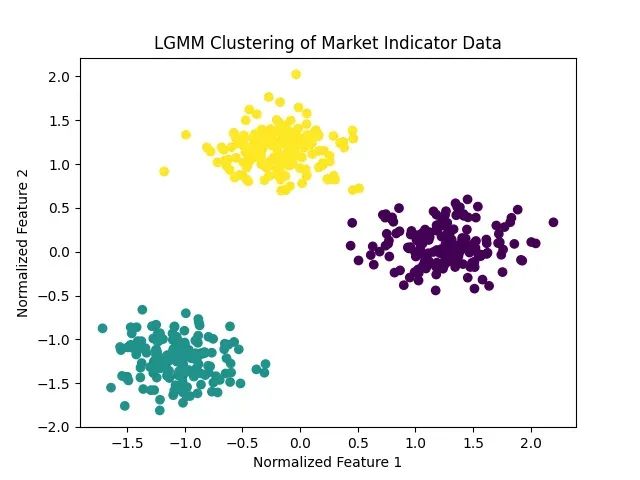
LGMM聚类示意图
在LGMM框架中,数据点x属于组件k的概率密度函数定义为:
P(x|k) = 1 / √(2 * π * σk²) * e^(-(x — μk)² / (2 * σ_k²))
其中,μk表示第k个组件的均值参数,确定了该组件的中心位置;σk²表示方差参数,描述了数据在该组件内的分散程度。该概率密度函数通过量化每个数据点与各组件的拟合程度,实现了对数据分布形状的精确建模,从而能够有效识别隐藏在噪声中的数据模式。
LGMM在处理SPY股票数据、文本分析等复杂数据集时表现优异,但在组件数量选择不当或存在显著异常值的情况下可能面临挑战。实践表明,该方法特别适用于具有多层次隐藏结构的数据集分析。
https://avoid.overfit.cn/post/07bebdcc9ba144868de960382585ab83

 浙公网安备 33010602011771号
浙公网安备 33010602011771号