大数据集特征工程实践:将54万样本预测误差降低68%的技术路径与代码实现详解
特征工程作为机器学习流程中的关键环节,在模型训练之前执行,其质量直接影响模型性能。虽然深度学习模型在图像和文本等非结构化数据的特征自动学习方面表现优异,但对于表格数据集而言,显式特征工程仍然是不可替代的核心技术。本文通过实际案例演示特征工程在回归任务中的应用效果,重点分析包含数值型、分类型和时间序列特征的大规模表格数据集的处理方法。
特征工程基础理论
特征工程是指从原始数据中选择、转换和构建新特征的系统性过程,旨在提升机器学习模型的预测性能。该过程需要运用领域知识,从数据中提取最具预测价值的信息,并将其转换为适合特定机器学习算法的表示形式。
特征工程的核心价值
精心设计的特征能够显著增强模型的预测能力,使简单模型也能够捕获复杂的数据关系。特征工程的主要价值体现在以下几个方面:
首先,特征工程能够有效减少数据稀疏性。现实世界的数据集通常存在大量零值和缺失值,导致数据稀疏。通过特征工程技术整合信息并创建更加密集的数据表示,可以显著提升模型的学习效率。
其次,特征工程解决了异构数据类型的处理问题。原始数据包含数值型、分类型、文本型和时间型等多种格式,特征工程将这些不同类型的数据统一转换为模型可处理的数值格式。
最后,特征工程能够有效降低数据噪声和异常值的影响,从而构建更加稳健的预测模型。
当特征能够直接对应问题域中的有意义概念时,模型的决策过程将更具可解释性、准确性和稳健性。
常用特征工程技术
特征工程包含多种技术方法,每种方法都有其特定的适用场景:
对数变换技术主要应用于数值特征的处理,通过对数函数使数据分布更趋向于正态分布,满足许多机器学习模型的统计假设。该技术特别适用于处理具有显著偏斜分布的数值特征。
多项式特征创建技术通过将现有特征提升到更高次幂(如x²、x³)或创建交互项(如x×y)来生成新特征。这种方法主要用于捕获数据中的非线性关系。
分箱(离散化)技术将连续数值划分为若干区间,可以有效减少小幅波动的影响,使非线性关系更趋向于线性。该技术特别适用于使用线性模型处理非线性关系,以及数据包含显著异常值或偏斜的情况。
基于时间的特征工程包括提取星期几、月份、年份、小时、季度等基础时间特征,以及构建"是否周末"、"是否假期"等复合特征。同时,还可以计算事件间的时间差。这类特征主要适用于存在季节性模式影响预测结果的场景。
机器学习项目工作流程
虽然不存在适用于所有情况的通用方法,但特征工程的一般工作流程通常涵盖整个项目生命周期,从问题定义和成功指标制定开始。本文将重点演示第一阶段和第二阶段的实施过程,特别关注特征工程的具体应用。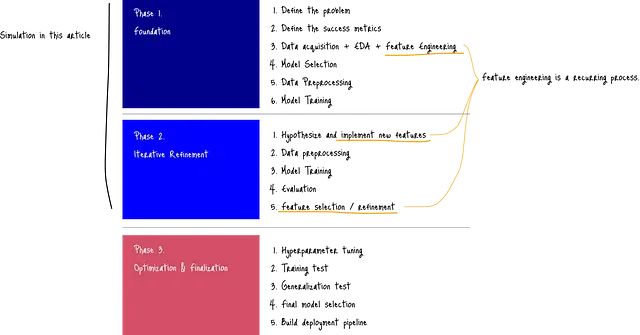
图:机器学习项目工作流程与特征工程位置
https://avoid.overfit.cn/post/f35ee9cd9c874079a3c897f903a7134f

 浙公网安备 33010602011771号
浙公网安备 33010602011771号