从零复现Google Veo 3:从数据预处理到视频生成的完整Python代码实现指南
Google Veo 3作为当前最先进的文本到视频生成系统,能够根据文本提示生成高质量、高分辨率的视频内容并同步生成音频。该系统在性能上已超越OpenAI SORA等同类模型,代表了视频生成领域的最新技术水平。
Google最近发布了Veo 3技术报告和模型规格说明,详细阐述了系统架构、训练流程等核心技术细节。本文将基于这些技术文档,从零开始复现Veo 3的实现方法,构建我们自己的小规模Veo 3模型。
Veo 3系统架构概览
根据Google提供的Veo 3高层架构图,我们可以了解其工作流程: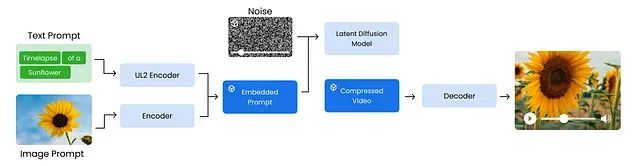
整个训练过程可以分解为四个主要阶段:首先,系统对输入提示进行编码,文本提示通过UL2编码器处理生成语义嵌入向量。同时系统还可以包含图像提示并进行编码以丰富输入信息。其次,这些嵌入向量被组合成嵌入提示,作为条件输入。系统初始化噪声压缩视频来模拟模型训练的生成空间。接下来,潜在扩散模型学习使用嵌入提示作为指导对压缩视频进行去噪处理,逐步生成精细化的压缩视频。最后,该输出通过解码器重建全分辨率视频,例如清晰的1080p向日葵绽放延时摄影。
这个高层图表隐藏了训练、预处理和安全措施等组件的技术细节。基于模型规格说明和技术报告,我们重新构建了Veo 3架构的详细分解图: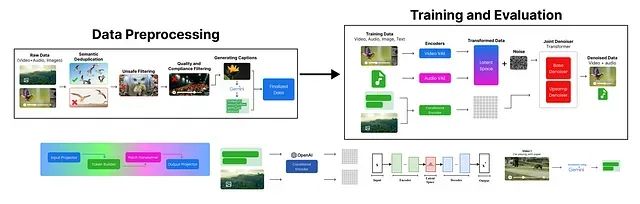
将Veo 3架构分解为四个核心阶段:数据预处理阶段负责输入数据的准备和预处理;训练阶段使用预处理后的数据训练Veo 3模型;评估阶段在各种指标上对训练后的模型进行性能评估。接下来我们将详细分析每个阶段的技术实现。
https://avoid.overfit.cn/post/636514c2565946bb85ca5fce57577ddb

 浙公网安备 33010602011771号
浙公网安备 33010602011771号