PaperCoder:一种利用大型语言模型自动生成机器学习论文代码的框架
机器学习研究领域正经历着飞速发展,然而与此形成鲜明对比的是,已发表研究成果的代码实现往往缺失或难以获取。这种代码的缺失极大地阻碍了研究结果的可复现性,并减缓了科学进步的步伐。研究人员不得不投入大量时间和精力从论文中反向工程方法,这不仅效率低下,而且容易出错,最终阻碍了新思想的验证和进一步发展。据统计,在2024年顶级机器学习会议上发表的论文中,仅有极小一部分(例如21.23%)提供了相应的代码
近年来,大型语言模型(LLMs)在理解科学文献和生成高质量代码方面展现出卓越的能力。这些模型能够理解复杂的文本描述,并将其转化为可执行的代码,为自动化将研究论文转化为代码库提供了有希望的途径。正是基于此,本文介绍了一种名为PaperCoder的新型多智能体LLM框架,旨在自动生成机器学习研究论文的代码库。PaperCoder的出现,正是为了弥合机器学习研究中代码可复现性不足的鸿沟,为科研人员提供更便捷、高效的工具。图1a概括了PaperCoder将科研论文转化为代码仓库的三阶段流程。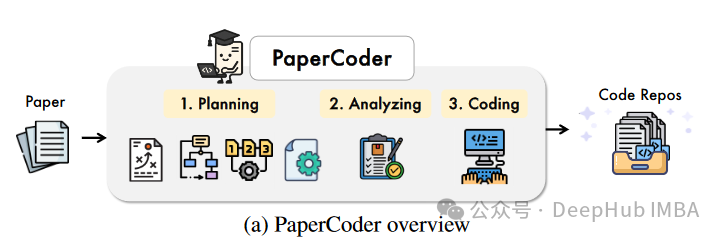
https://avoid.overfit.cn/post/a74f6ea10ab148c9aa8306ac67c9786f

 浙公网安备 33010602011771号
浙公网安备 33010602011771号