加速LLM大模型推理,KV缓存技术详解与PyTorch实现
随着大型语言模型(LLM)规模和复杂度的指数级增长,推理效率已成为人工智能领域亟待解决的关键挑战。当前,GPT-4、Claude 3和Llama 3等大模型虽然表现出强大的理解与生成能力,但其自回归解码过程中的计算冗余问题依然显著制约着实际应用场景中的响应速度和资源利用效率。
键值(KV)缓存技术作为Transformer架构推理优化的核心策略,通过巧妙地存储和复用注意力机制中的中间计算结果,有效解决了自回归生成过程中的重复计算问题。与传统方法相比,该技术不仅能够在不牺牲模型精度的前提下显著降低延迟,更能实现近线性的计算复杂度优化,为大规模模型部署提供了实用解决方案。
本文将从理论基础出发,系统阐述KV缓存的工作原理、技术实现与性能优势。我们将通过PyTorch实现完整演示代码,详细分析缓存机制如何与Transformer架构的自注意力模块协同工作,并通过定量实验展示不同序列长度下的性能提升。此外,文章还将讨论该技术在实际应用中的局限性及未来优化方向,为读者提供全面而深入的技术洞察。
无论是追求极致推理性能的AI工程师,还是对大模型优化技术感兴趣的研究人员,本文的实践导向方法都将帮助你理解并掌握这一关键性能优化技术。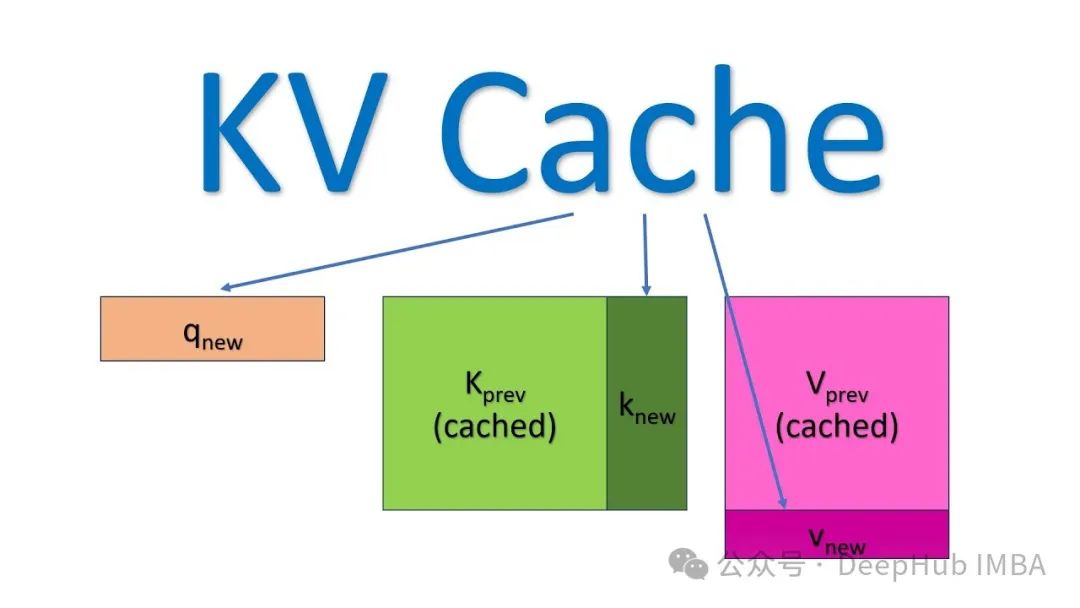
KV缓存是一种优化技术,用于存储注意力机制中已计算的Key和Value张量,这些张量可在后续自回归生成过程中被重复利用,从而有效减少冗余计算,显著提升推理效率。
https://avoid.overfit.cn/post/3e49427b9e42440aa0c8d834c1906f2f

 浙公网安备 33010602011771号
浙公网安备 33010602011771号