GenPRM:思维链+代码验证,通过生成式推理的过程奖励让大模型推理准确率显著提升
过程奖励模型(PRMs)作为验证机制在提升大型语言模型(LLMs)性能方面展现出显著潜力。而当前PRMs框架面临三个核心技术挑战:过程监督和泛化能力受限、未充分利用LLM生成能力而仅依赖标量值预测,以及在测试时计算无法有效扩展。
针对上述局限,这篇论文提出了GenPRM,一种创新性的生成式过程奖励模型。该模型在评估每个推理步骤前,先执行显式的思维链(Chain-of-Thought, CoT)推理并实施代码验证,从而实现对推理过程的深度理解与评估。
下图直观地展示了GenPRM与传统基于分类方法的本质区别: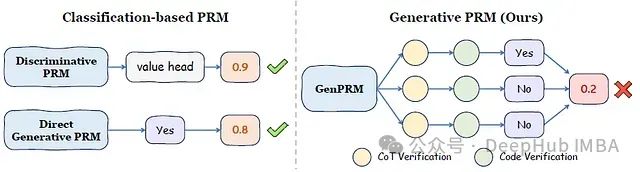
研究的主要技术贡献包括:
- 构建了一种生成式过程奖励模型架构,该架构通过显式CoT推理和代码验证机制,结合相对进展估计技术,实现了高精度PRM标签的获取
- 在ProcessBench及多种数学推理任务的实证评估表明,GenPRM在性能上显著优于现有的基于分类的PRMs方法

 浙公网安备 33010602011771号
浙公网安备 33010602011771号