SmolVLM:资源受限环境下的高效多模态模型研究
SmolVLM是专为资源受限设备设计的一系列小型高效多模态模型。尽管模型规模较小,但通过精心设计的架构和训练策略,SmolVLM在图像和视频处理任务上均表现出接近大型模型的性能水平,为实时、设备端应用提供了强大的视觉理解能力。
SmolVLM架构设计
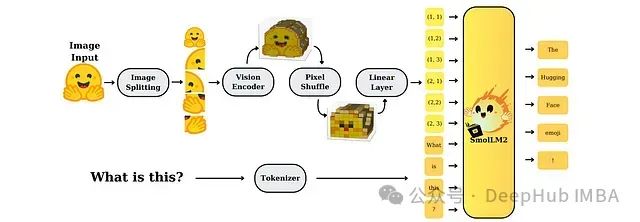
该研究系统性地探索了小型多模态模型的设计选择与权衡。在SmolVLM的架构中,图像首先通过视觉编码器进行处理,编码后的视觉特征经过池化和维度投影后输入到SmolLM2语言骨干网络中进行多模态理解与生成。
SmolVLM根据不同的计算资源需求构建了三种主要变体:
- SmolVLM-256M:结合93M参数的SigLIP-B/16视觉编码器和SmolLM2-135M语言模型。该变体可在不足1GB显存环境中运行,特别适合极度受限的边缘计算场景。
- SmolVLM-500M:将93M参数的SigLIP-B/16视觉编码器与SmolLM2-360M语言模型组合。这一变体在内存效率与性能之间取得平衡,适用于中等计算资源的边缘设备。
- SmolVLM-2.2B:整合400M参数的SigLIP-SO400M视觉编码器和1.7B参数的SmolLM2语言骨干网络。该配置在保持可部署于高端边缘系统的同时最大化了性能表现。
https://avoid.overfit.cn/post/04db3129ef8045a19e0d24f1aae9e633

 浙公网安备 33010602011771号
浙公网安备 33010602011771号