PyTorch CUDA内存管理优化:深度理解GPU资源分配与缓存机制
在深度学习工程实践中,当训练大型模型或处理大规模数据集时,上述错误信息对许多开发者而言已不陌生。这是众所周知的
CUDA out of memory
错误——当GPU尝试为张量分配空间而内存不足时发生。这种情况尤为令人沮丧,特别是在已投入大量时间优化模型和代码后遭遇此类问题。
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 512.00MiB. GPU 0 has a total capacity of 79.32 GiB of which 401.56 MiB is free.
本文将深入剖析PyTorch如何优化GPU内存使用,以及如何通过定制其内部系统机制来充分发挥GPU集群的性能潜力。
GPU内存管理的关键性
在当代深度学习领域,随着数据集规模呈指数级增长及模型复杂度不断提升,高效利用GPU内存已成为技术实现的首要考量因素。无论GPU计算能力多么强大,板载内存容量始终是制约因素。每次内存分配与释放的影响往往比开发者预期更为深远。研究人员在训练大规模模型时常见的挑战主要包括:
内存容量限制是一个基本物理约束。如果训练过程或数据超出可用内存容量,训练将无法继续。计算效率方面,GPU理想状态应将主要时间用于矩阵运算,而非等待数据传输或协调多GPU工作。通信开销也是重要考量因素——GPU在通信期间实质上处于空闲状态,这是计算资源的浪费。为最小化此类开销,需合理利用节点间(相对较慢)和节点内(相对较快)通信带宽,理想情况下实现计算与通信的并行执行。
内存碎片化问题在频繁执行内存分配/释放操作(通过
cudaMalloc
和
cudaFree
)时尤为显著。这是一个核心挑战——即使总体空闲内存空间充足,碎片化也可能导致无法分配所需大小的连续内存块。与此同时,频繁的内存分配/释放不仅导致碎片化问题,还会引入大量计算延迟。此外,现代深度学习应用通常需要处理不同批量大小、动态网络架构或多种规格输入的模型,这要求内存管理系统能够在运行时高效适应变化,而不会造成显著性能损失。
以上因素共同凸显了PyTorch CUDA缓存分配器在整个内存管理体系中的核心地位。它通过系统性解决内存碎片和分配延迟问题,有效降低了内存操作的性能开销。
PyTorch CUDA缓存分配器的工作原理
为了直观理解PyTorch内存分配机制,我们可以观察使用PyTorch性能分析器在训练Llama 1B模型过程中的内存分配情况。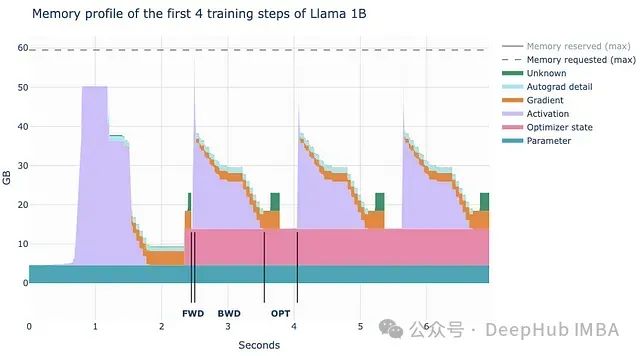
上图展示了使用PyTorch性能分析器记录的Llama 1B模型前4个训练步骤的内存配置文件
https://avoid.overfit.cn/post/0dacd990b25343d690e3258ecdca8a28

 浙公网安备 33010602011771号
浙公网安备 33010602011771号